

作者:边江

“人工智能基础模型(Foundation Models),也就是人们常说的大语言模型(Large Language Models)或大模型,在不同产业具有巨大的应用潜力,但一些企业和机构对于人工智能大模型的应用方式,还局限在智能客服、对话机器人,或者文字、图片生成等方面。事实上,基础模型拥有强大的推理、生成和泛化能力,适用于产业界中最具商业价值的任务,如精准预测和控制、高效优化决策,以及智能化、可交互的工业模拟。”
边江,微软亚洲研究院资深首席研究员
随着人工智能大模型(基础模型)的发展,很多企业和机构都对其在生产力场景中的应用表现出极大的热情。不过,我们也观察到这样一个现象:很多产业从业者似乎更关注人工智能接近“人”的一面——像人类一样对话、写作、创作,以及拥有近似于人类的感知能力。比如,很多企业在引入人工智能大模型时,首选场景都倾向于智能客服,对话机器人等“类人”岗位。毫无疑问,这种倾向存在着对大模型理解和应用上的局限,并不能让它在产业界发挥出应有的潜力。
然而,这些局限有其必然性。因为基础模型与生产场景的融合还缺乏成熟且普遍的先例。如果把人工智能看作一种“生产工具”,那么它的应用就类似于“先有工具再发掘用途”,而且人类历史上可能从未有过这种不针对特定需求,而是有着广泛用途但又存在不确定性的工具。
此外,由于不同产业存在更加丰富、复杂的场景,适用于产业界相应场景的基础模型,与通常意义上的基础模型也不尽相同。这就需要对产业大模型进行同步创新,在更多产业场景中充分发挥基础模型的能力,实现人工智能与应用场景的匹配。对于各个产业来说,我们不妨从摆脱思维局限开始,不要将人工智能等同于机器“人”。然后,重新审视和改变现有的业务流程和业务架构,梳理出适应人工智能时代的人与基础模型的合作模式。
基础模型在产业界潜力无限
基础模型是具有通用的数据表示能力、知识理解能力和推理能力的人工智能模型,可以在不同的领域和场景中自然迁移,并快速适应新的环境。与此同时,产业界的数字化平台在经过多年的发展后,已经积累了大量的行业数据,为基础模型提供了更丰富和更适用于特定场景的知识和信息——这让基础模型有了融入产业场景的基础。
在应用价值方面,基础模型强大的推理能力,能够帮助使用者更好地理解数据,从海量的数据中提取有价值的信息,发现数据之间的关联和规律,从而提供更深刻的洞察和更有效的建议。这一优势可以在产业领域的预测、决策、模拟等场景中发挥关键作用。
基础模型的另一个优势是泛化能力。在基础模型出现之前,每个行业场景都需要使用特定数据来训练一个专属人工智能模型,这难以大规模复用,限制了人工智能的商业价值,而基于全世界通用知识训练的基础模型,极大地提升了模型的泛化能力,让产业界不再需要像传统人工智能解决方案那样,为每个场景训练专属模型。
基础模型还可以和生成式人工智能结合,提升工业仿真和智能模拟的准确性、真实性与可交互性,促进数字孪生的实现。工业仿真和模拟都是对真实世界的还原和测试,涉及众多复杂的角色和环境。传统人工智能模型难以支撑大规模仿真,模拟时往往会简化真实情况,或忽略重要的极端事件,影响了模拟和仿真的质量和真实性。生成式人工智能大模型能够支持更广泛的场景,在深入学习特定领域专业知识的基础上,建立特定数据维度分布与真实事件的映射,实现接近现实世界的模拟,更好地辅助工业预测与决策任务,达到工业应用标准。
基础模型在产业界落地需要克服四个难题
在产业界,最重要也最有商业价值的任务包括精准预测和控制,高效优化决策,以及智能化、可交互的工业模拟等复杂任务。这些领域也是传统行业企业应该重点关注的应用方向。然而,通过对现有的 GPT 等基础模型的评测,并结合产业领域的实际情况,我们发现基础模型与真实产业需求之间还存在明显差距,需要克服若干难题,才能使其在产业界发挥更大的作用。
首先,我们缺乏一个能够从纷繁的领域数据中理解复杂领域知识,且可以基于领域知识来构建智能体的通用框架。不同的领域具有各自丰富且复杂的数据,例如物流企业中的海关信息、跨国政策等相关信息;医药行业中 FDA(食品药品监督管理局)药物审查文档;法律行业中的各类法规文档等。构建基于领域知识的智能体需要更通用的框架,从这些数据中提炼出重要的领域知识,发现数据和知识之间的隐含关联,并对它们进行有效的组织和管理。
其次,在文本数据之外,基础模型对结构化数据的处理和理解能力较弱。目前的基础模型最擅长的还是纯文本内容的生成和创作,部分模型也能处理图像、语音等数据。但是,工业场景中的数据往往是数值型、结构化的,如健康监测指标、电池充放电信号、金融信用行为等时序数据或表格数据。现有的大模型还没有针对这类数据进行特定的设计和优化,不能充分理解并处理这些数据,因此很难精准的完成基于这类数据的预测和分类任务。
第三,从应用层面来看,基础模型的决策能力不够稳定和可靠。能源、物流、金融、健康等关键产业场景中最重要的往往是决策类任务,包括物流路径优化、能耗设备控制、投资策略制定、医疗资源调度等,这些任务往往涉及多个变量和多个约束,特别是当面对动态变化的环境时,基础模型还没有完全适应这些复杂的任务,无法直接在产业领域应用。
最后,我们还缺乏对一些特定领域的基础数据的洞察,以及构建特定领域基础模型的方法和经验。很多特定领域的核心信息并不是单纯的文本,因此他们的基础数据也不再是文本中的字和词,而是包含独特的语义结构和关系的新型基础数据,例如金融投资行业中的交易订单信息;生物医药行业中的分子结构信息等,相关领域的核心知识往往隐含在这一类基础数据中,需要更深入和更细致的分析。只有在此基础上构建特定领域的基础模型,才能更有效地挖掘和释放数据的潜力。
构建产业基础模型:融合通用知识与领域专业知识
为了推动基础模型在产业界更快地落地和应用,我们可以着重从以下几个方面入手:
首先,我们可以利用丰富和复杂的产业领域数据,构建更通用、高效和实用的检索增强生成(RAG)框架,可以适配各个垂直领域,帮助提炼出重要的领域知识,发现数据和知识之间的隐含关联,并对它们进行有效的组织和管理。

其次,基于工业场景中重要的数值数据和相应的结构化依赖,构建适合产业化的基础模型,通过有效融合通用知识和时序数据或表格数据中的领域知识,更有效地解决产业中的预测、分类等任务。

另一个我们目前正在着重探索的方向:利用基础模型已具备的强大的生成、泛化和迁移能力,提高产业决策的质量和效率。在这方面,我们在探索两种路径,一是将基础模型作为一个智能体,二是让基础模型辅助强化学习智能体。
将基础模型作为一个智能体:我们可以利用基础模型的先验知识,结合离线强化学习(Offline Reinforcement Learning),通过持续收集新的领域知识并不断微调,促进智能体的进化,提高作为智能体的基础模型的优化决策能力,使其能更专注于处理产业领域内的任务。
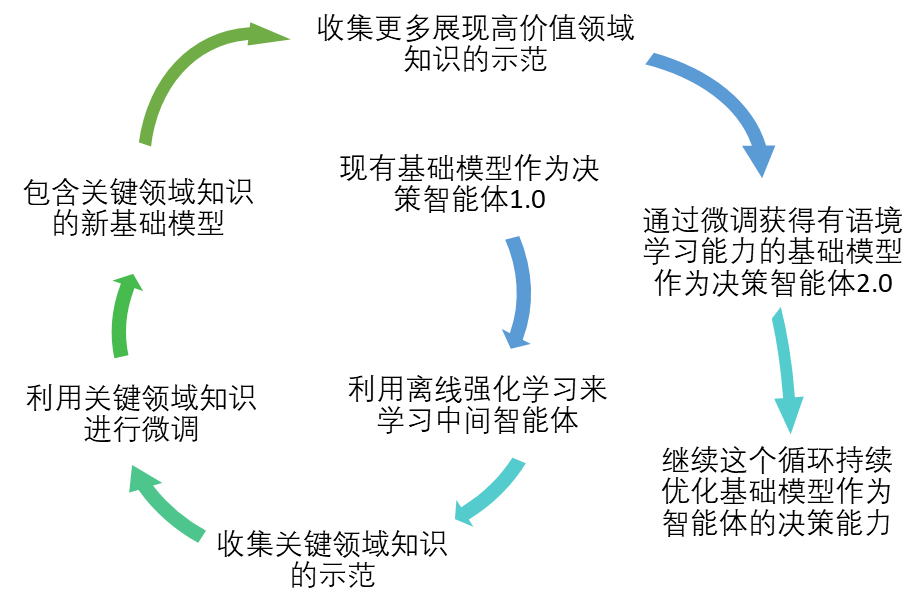
经过优化的基础模型可以在多种产业场景中发挥作用。例如,在方程式赛车中,该基础模型能够优化赛车的轮胎维修策略,根据赛车轮胎的损耗和维修成本,找到最佳的进站维修时间,以缩短赛程、提高赛车排名;在化工企业的产品调度中,利用这一基础模型可以大幅提高产品存储与生产过程中管线协同的效率,从而提升生产执行效率;另外,基于基础模型的泛化能力与鲁棒性,还可以将其快速迁移至空调控制优化的场景中,在保证舒适温度的同时实现能耗最小化。
使用基础模型辅助强化学习智能体:我们可以让模型学习通用表示,在不同的环境和任务中快速适应,从而提升泛化能力。在这一方法中,我们引入了预训练世界模型(Pretrained World Model),它可以模拟人类的学习和决策过程,增强产业决策的效果。通过利用具有广泛知识的预训练世界模型,并采用两阶段预训练框架,开发者能够更全面和灵活地训练基础模型进行产业决策,并将其扩展到任何特定的决策场景。
我们与微软 Xbox 团队合作,在游戏测试的场景中验证了这个框架的有效性。我们利用该框架针对游戏地图预训练了世界模型,解决了在新游戏场景中利用地标观察进行长期空间推理或导航的问题。该预训练模型明显优于没有世界模型或使用传统学习方法的模型,极大地提高了游戏探索的效率。
此外,我们还可以使用领域内专有的基础数据和所蕴含的特定语义信息,打造领域内的基础模型,为智能可交互的决策和模拟开拓新的可能性。比如,我们可以基于金融市场交易订单数据构建金融投资基础模型,这些基础数据是包含丰富语义结构和信息的交易订单,而不是纯文本字符。基于这一金融基础模型,我们可以实现针对不同市场风格的订单流生成,模拟不同市场环境下的大规模订单交易,实现对金融投资市场的可控模拟,从而更好地理解市场变化的规律,探索应对极端场景的策略。

基础模型引领产业数字化转型的下一波浪潮
很早之前,微软亚洲研究院就已经意识到人工智能在产业界的广泛应用需要新的技术探索、尝试和突破,通过跟来自不同产业的合作伙伴合作,我们陆续研发出 Qlib 人工智能量化投资平台、MARO 多智能体资源优化平台、FOST 时空预测工具、BatteryML 电池性能分析与预测平台等开源模型。这些面向产业的人工智能平台、工具和模型,不仅在工业界发挥了重要作用,也为目前基础模型的产业落地提供了重要的数据和工具基础。
借鉴成功的人工智能产业化经验,我们已经开始从前文介绍的几个维度深入探索面向工业领域的人工智能基础模型及其应用。我们发现,在这些突破传统大模型认知的维度上,基础模型拥有巨大潜力,能够深刻促进产业变革。
可以想象,未来基础模型将能够帮助产业界实现行业内的知识自动管理、自动提取、自动迭代。在此之外,我们也在探索基础模型帮助企业实现自动研发,包括研发方向的自动发掘、算法研究方案的自动生成、研发过程和科学实验的自动生成和执行,以及研究思路的自动迭代。换言之,人工智能将能够自主进行数据驱动的产业化研发,这将深刻改变产业界的运作模式。

基础模型将是继互联网和云计算之后,加速产业数字化转型的新动力,并将带来新一波的产业创新爆发。我们期待与更多产业界的合作伙伴一起,深入真实场景,探索基础模型在产业领域应用的更多可能性,充分释放基础模型的商业价值。
本文作者
边江博士,现任微软亚洲研究院资深首席研究员、微软亚洲研究院机器学习组和产业创新中心负责人,所带领的团队研究领域涉及深度学习、强化学习、隐私计算等,以及人工智能在金融、能源、物流、制造、医疗健康、可持续发展等垂直领域的前沿性研究和应用。
边江博士曾在国际顶级学术会议和期刊上发表过上百篇学术论文,并获得数项美国专利。他曾是多个国际顶级学术会议程序委员会成员,并担任多个国际顶级期刊审稿人。过去几年,他的团队成功将基于人工智能的预测和优化技术应用到金融、物流、医疗等领域的重要场景中,并将相关技术和框架发布到开源社区。
边江博士本科毕业于北京大学,获计算机科学学士学位,之后在美国佐治亚理工学院深造,获计算机科学博士学位。
相关模型开源链接:
Qlib 人工智能量化投资平台:https://www.msra.cn/zh-cn/news/features/qlib-2
MARO 多智能体资源优化平台:https://github.com/microsoft/maro
FOST 时空预测工具:https://github.com/microsoft/FOST
BatteryML 电池性能分析与预测平台:https://github.com/microsoft/BatteryML