
LongRoPE:超越极限,将大模型上下文窗口扩展超过200万tokens
2024-04-16 | 作者:系统与网络组
编者按:大模型的飞速发展给人们的生活带来了前所未有的便利。我们是否能够设想利用大模型的潜力,快速扫描整部百科全书、解析繁琐复杂的法律条款,甚至对文章进行精准引用呢?在未来,这些将统统可以实现。然而,目前传统的大模型的上下文窗口限制与昂贵的微调成本使得它们难以处理超长文本,从而限制了其应用潜力。为解决这一问题,微软亚洲研究院的研究员们提出了 LongRoPE。通过精细化非均匀位置插值和渐进式扩展策略,LongRoPE 成功将大模型的上下文窗口扩展至2048k,不仅保持了原始短上下文窗口的性能,还大幅提升了长文本处理的效果。LongRoPE 的应用前景广阔,将为大模型的发展带来更多可能。
在2024年,长文本问题已成为大模型发展中备受关注的关键挑战。人们普遍认为,能够接受无限长度输入的大模型将会带来许多重大突破。例如,它可以一口气通读整套百科全书、冗长的法律条文、或大部头的经典医学教材,并准确提供任意章节的简要引用。这对于研究人员和公众都将是巨大的助益。如果大模型可以将一个人所有相关的信息(文本、照片、音视频等)作为上下文全部输入,那么甚至可能为该人创建一个可交互的数字副本。这些潜在的应用场景将为大模型开辟更广阔的前景。
然而,实现长文本并非易事。目前主流的大模型通常只提供一个有限且较短的预定义上下文窗口。例如,LLaMA2 允许输入最多4096个 tokens。当输入超过该限制时,由于模型没有在预训练中见过超出上下文窗口的新的 token 位置,其性能会显著下降。
最近的研究表明,通过在更长的文本上进行微调,预训练的大模型上下文窗口可以扩展到约128k。但进一步扩展上下文窗口则存在三个主要挑战:首先,未经训练的新位置索引引入了许多异常值,使得微调变得困难。例如,当从 4k tokens 扩展超过1000k时,会引入超过90%的新位置,这就使得现有的微调方法变得难以收敛。其次,微调通常需要相应长度的长文本,但当前训练数据中长文本数量有限。此外,随着上下文窗口的继续扩展,模型的计算量和内存需求将显著增加,带来极其昂贵的微调时间成本和 GPU 资源开销。最后,当扩展到超长的上下文窗口后,由于引入众多新位置信息,大模型的注意力会分散,从而降低了大模型在原始短上下文窗口上的性能。
为了解决这些挑战,微软亚洲研究院的研究员们推出了 LongRoPE。作为迈向无限上下文窗口的第一步,LongRoPE 首次将预训练的大语言模型(LLMs)的上下文窗口扩展到了2048k(约210万)个 tokens,而其实现仅需在256k的训练长度内进行1k次微调步骤即可,同时仍能保持原始短上下文窗口的性能。

图1:LongRoPE 现在保持着最长 LLM 上下文窗口的记录
LongRoPE: Extending LLM context window beyond 2 million tokens
https://arxiv.org/pdf/2402.13753.pdf
LongRoPE的主要方法
精细化非均匀位置插值。目前的大模型通常采用 RoPE 旋转位置编码,对 RoPE 位置编码进行插值是解决上述挑战中第一个问题的一种常见方法。这种方法将新位置索引缩小到预训练范围内。在已有的相关工作中,位置插值(position interpolation,PI)会通过扩展比例来线性插值 RoPE 的旋转角度。NTK-aware 位置编码插值方法提出,利用公式对每个RoPE维度进行经验性重新缩放,YaRN 会将 RoPE 维度分成三组,并分别针对三组 RoPE 维度进行不同的缩放(即直接外推,NTK-aware 插值和线性插值)。然而,这些方法主要基于启发式经验插值,未充分利用 RoPE 中的复杂非均匀性,导致关键信息在位置编码插值后丢失,从而限制了上下文窗口的大小。
研究员们经过实验发现,有效的位置编码插值应考虑两种非均匀性:不同的 RoPE 维度和 token 位置。低维 RoPE 和初始 token 位置存储着关键信息,因此需要进行更少程度的插值。相比之下,高维 RoPE 存储的信息相对较为稀疏,可进行较大程度的插值。为了充分利用这些非均匀性,研究员们提出了一种基于进化算法的方法,允许搜索 RoPE 每个维度以及不同 token 位置的旋转角度缩放因子,有效地保留了原始 RoPE 位置编码中的信息。这种方法最大程度地减小了位置插值引起的信息损失,从而为微调提供了更好的初始化。此外,这种方法还允许在不微调的情况下实现8倍的扩展。
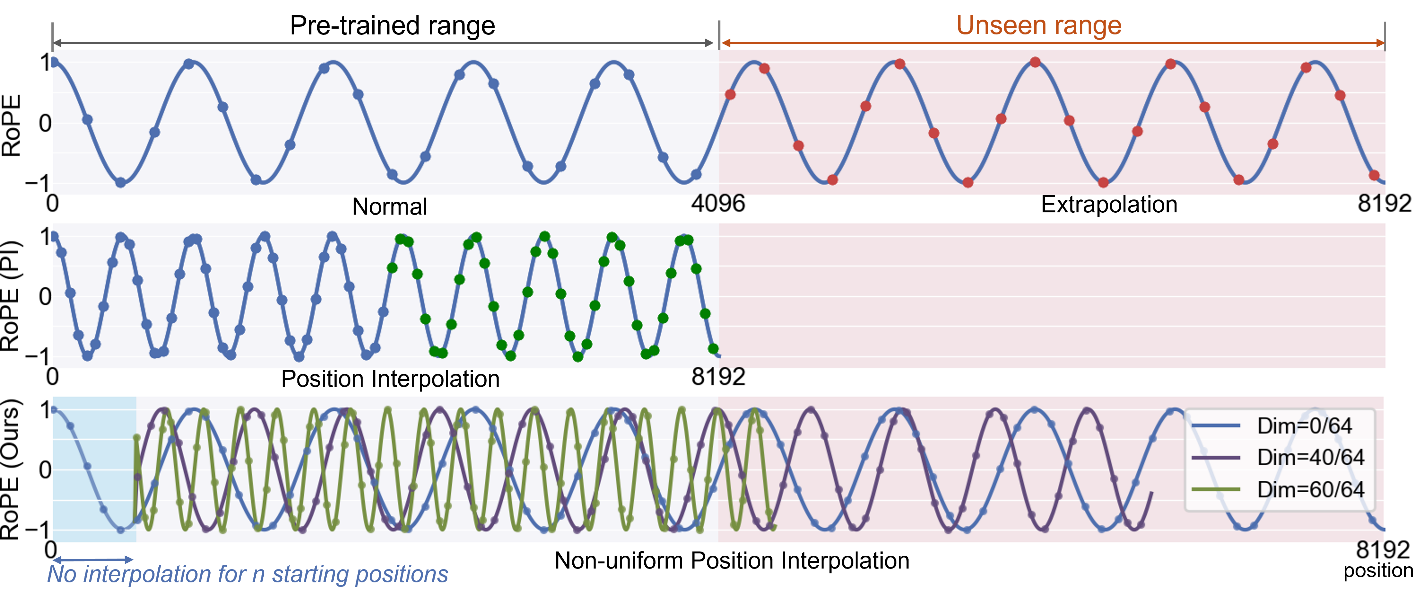
图2:不同位置编码插值方法的比较。上:RoPE 在直接外推下的表现;中:线性位置编码插值下的 RoPE;下:LongRoPE 在不同 RoPE 维度以及位置上的非均匀性插值。
渐进式扩展策略。在非均匀位置编码插值的基础上,LongRoPE 采取了高效的渐进式扩展策略,从而在无需直接对极长文本进行微调的情况下,有效实现了2048k上下文窗口的目标。具体策略如下:首先在预训练的大模型上搜索256k上下文窗口对应的位置编码插值方案,并在此长度下进行微调。其次,由于 LongRoPE 的非均匀插值允许在不微调的情况下进行8倍扩展,所以研究员们对已扩展的微调后的大模型进行了二次非均匀插值搜索,最终达到了2048k上下文窗口。
恢复短上下文窗口性能。在将上下文窗口扩展到极长的2048k后,研究员们注意到原始上下文窗口内的性能出现了下降。这是位置插值的一个已知问题,因为它导致原始上下文窗口内的位置被压缩在更窄的区域内,从而对大模型的性能产生了负面影响。为了解决这一问题,研究员们在扩展后的大模型上对8k长度内的 RoPE 缩放因子进行了重新搜索,旨在引导在较短长度上进行较少的位置插值,来恢复短上下文窗口的性能。在推理过程中,大模型可根据输入长度动态调整相应的 RoPE 缩放因子。
LongRoPE的实验性能
研究员们在 LLaMA2-7B 和 Mistral-7B 上应用 LongRoPE 并进行了测试,从三个方面评估了其性能。
第一项测试是在长文档上评估扩展上下文语言模型的困惑度。在256k以内的评估长度上,研究员们使用了 Proof-pile 和 PG19 数据集来进行测试。LongRoPE 在4k-256k的文本长度上,整体上显示出困惑度下降的趋势,优于基准。即使在上下文窗口长度是标准长度16倍的情况下,LongRoPE-2048k 模型在256k上下文长度内也超过了最新基线水平。
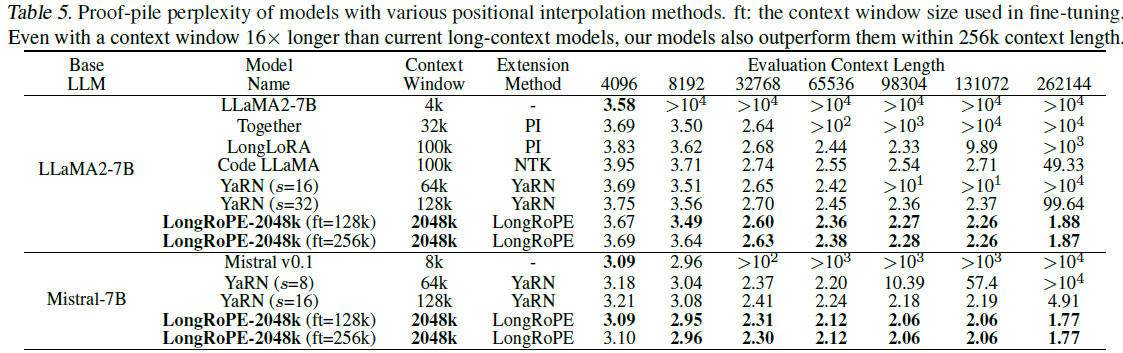
表1:经过不同位置插值方法进行上下文窗口扩展之后的 LLaMA2-7B 和 Mistral 在 Proof-Pile 数据集上的困惑度对比。
接下来,研究员们增加了测试难度,从 Books3 数据集中随机选取20本每本长度超2048k的书,并使用256k的滑动窗口进行评估。在 8k-2048k 的文本长度上,两种模型均取得了与基线相当或更优的困惑度表现。
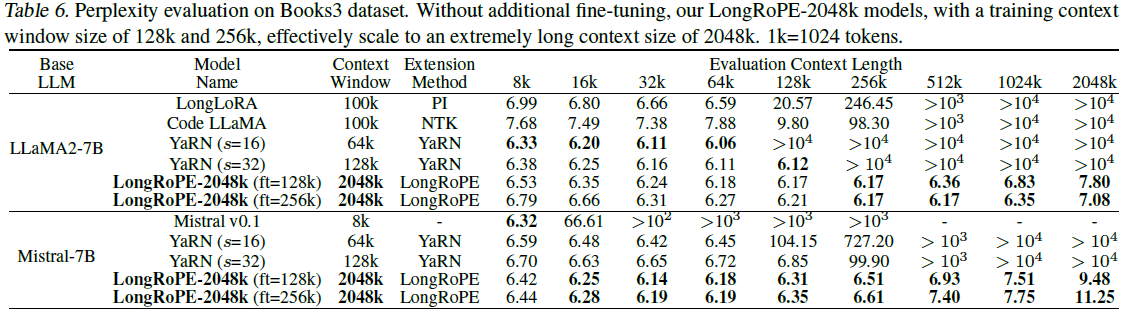
表2:经过不同位置插值方法进行上下文窗口扩展之后的 LLaMA2-7B 和 Mistral 在超长数据集 Books3 上的困惑度对比。
第二项测试是用 Passkey 检索任务评估在海量无关文本中检索简单密钥的能力。具体而言,该任务将在一个很长的文本中随机隐藏一个五位数密码,然后让模型找出该密码。结果显示,现有模型的准确率在文本长度超过128k后迅速下降到0。而 LLaMA2-2048k 在4k-2048k文本长度范围内保持了90%以上的检索准确率,Mistral-2048k 在文本长度达到1800k之前保持了100%的准确率,在2048k时准确率下降到60%。
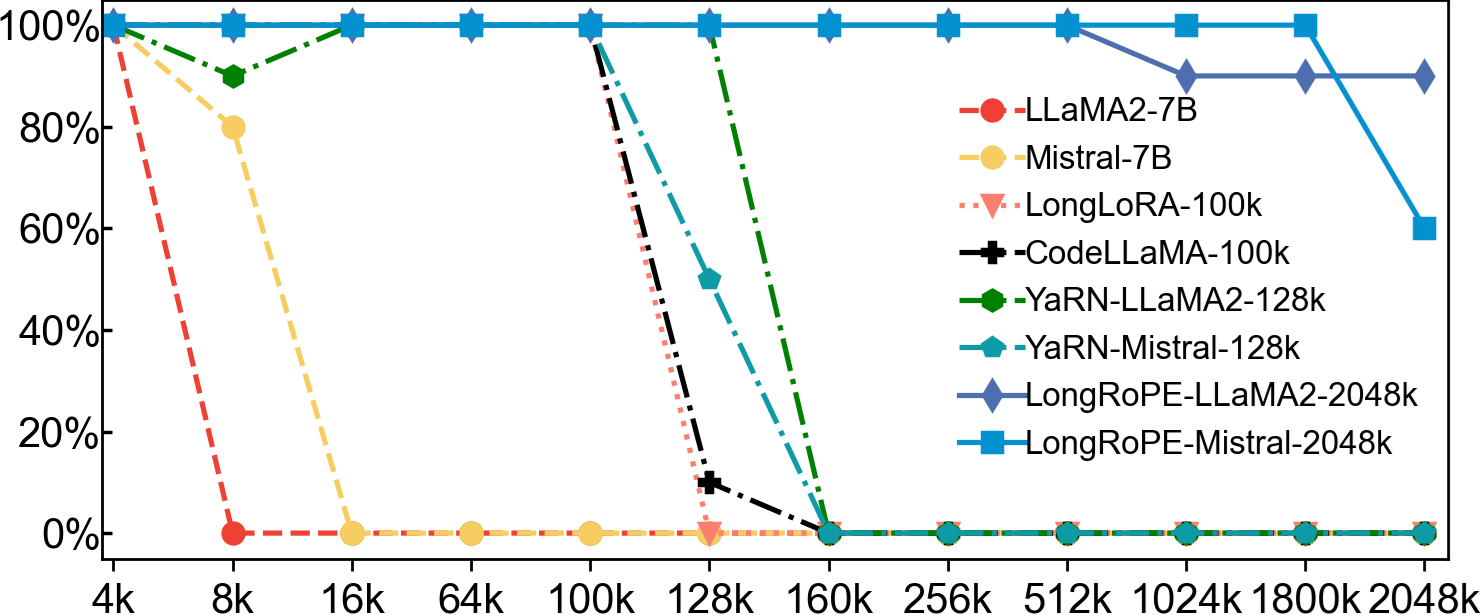
图3:不同长文本大模型在不同上下文长度下的 Passkey 检索精度。
第三项测试是在短4096上下文窗口长度内评估标准大语言模型基准测试上的表现。这项测试的主要目的是检验模型上下文窗口被扩展后,在原有任务上的表现是否会遭受负面影响。LongRoPE-2048k 模型在原始上下文窗口大小的任务上,其表现与原始模型相当甚至更优。
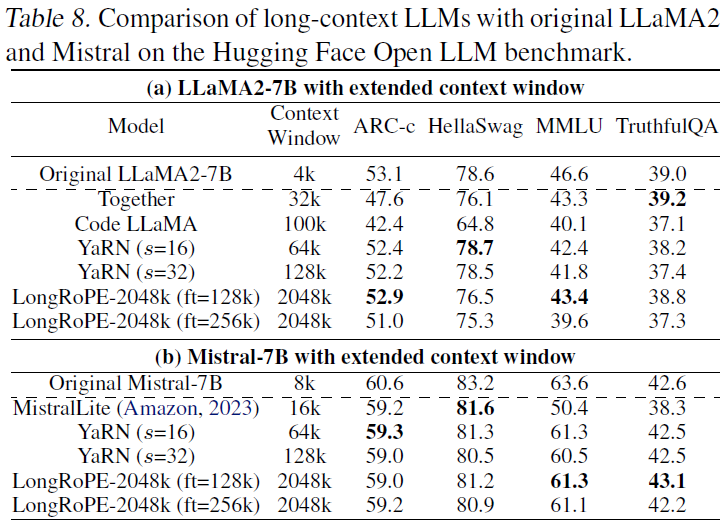
表3:不同长文本大模型在 Huggingface Open LLM benchmark 上的表现。
综上所述,LongRoPE 可以广泛应用于基于 RoPE 位置编码的大模型,并在最新的主流大模型上得到了验证。LongRoPE 仅对位置编码进行了轻微修改,保持了模型的原始架构,并且可以重用大部分现有的优化技术。
未来,研究员们计划将进一步探索 LongRoPE 在其他大模型架构中的应用,并继续研究实现通往无限上下文窗口的目标的技术。






