
预见AIOps:让云计算更自主、更前瞻、更全面,也更易于管理
2022-12-01 | 作者:微软研究院
编者按:“建立一个可供数百万人每天使用,但只需一名兼职人员管理和维护的系统。”这是吉姆·格雷(Jim Gray)在1999年获得图灵奖时对无故障服务器系统的畅想。他设想了一个自管理的“空中服务器”,可以存储大量数据,并可按需刷新或下载数据。如今,随着人工智能(AI)、机器学习(ML)、云计算的出现和快速发展,以及微软对云智能/AIOps(智能运维)的开发,我们比以往任何时候都更接近这一愿景,并有望超越这一愿景。
在过去15年间,软件行业最重要的范式转变是向云计算的迁移,这一转变给企业、社会和人们的生活都创造了前所未有的数字化转型机遇,并带来了巨大的利益。如今,云计算已经成为全球基础设施的一部分,因此,云计算的服务质量,包括可用性、可靠性、性能、效率、安全性和可持续性等也变得愈发重要。但云计算平台的分布式特性以及超大规模和高度复杂性的特点,贯穿于存储、网络、计算和其他各个方面,给系统的设计、构建和运维带来了巨大挑战。
什么是云智能/AIOps?
云智能/AIOps(简称“AIOps”)旨在通过创新的人工智能(AI)或机器学习(ML)技术,帮助人们有效且高效地设计、构建和运营大规模的复杂云平台及服务。AIOps 有三大支柱,每个支柱都有其各自的目标:
- AI for System:让智能内置于云系统,实现更少的人工干预,并同时保障系统的高可靠、高效率、自控制和自适应。
- AI for Customer:利用 AI/ML 创造无与伦比的服务体验,实现非凡的用户满意度。
- AI for DevOps:将 AI/ML 注入软件开发的全生命周期,以提高开发的质量和效率。
微软杰出首席科学家、微软亚洲研究院常务副院长张冬梅介绍云智能/AIOps研究的主题演讲
AIOps研究始于软件分析
全球咨询分析机构 Gartner 在2017年首次创造了 AIOps(人工智能IT运维)一词。Gartner 称,AIOps 是将机器学习和数据科学应用于 IT 运维问题上。Gartner 的 AIOps 概念仅聚焦开发运维(DevOps),而微软的云智能/AIOps的研究范围更为宽泛,还包含 AI for System 和 AI for Customer 两个方面。
微软在云智能/AIOps方面的研究可追溯到2009年微软亚洲研究院提出的“软件分析(Software Analytics)”研究,这项研究旨在让软件从业者能够通过探索和分析软件相关数据,获取深入且具有指导性的洞见,并应用于与软件和服务相关的数据驱动任务。2014年,微软的研究员们开始将软件分析的研究重点放在云计算上,并将新的研究主题命名为云智能(Cloud Intelligence)。回看过去,软件分析主要是关于软件行业自身的数字化转型研究,例如让从业者利用数据驱动的方法和技术来开发软件、运维软件系统以及提升用户体验。而当下在进行云智能研究时,也同样以数字化转型的观念来看待云计算平台的发展,就是将最先进的 AI 技术内嵌于云计算平台,以服务于云系统、开发运维人员、以及云客户,从而更好地推动云计算平台的智能化发展。

图1:从软件分析到云智能/AIOps
AIOps 中的主要研究领域:检测、诊断、预测和优化
在 AIOps 的三大支柱中,每一个都有许多场景。例如,在 AI for System 方面,包括为高效和可持续服务进行前瞻性预测、监测服务的健康状况和及时发现系统健康问题;在 AI for DevOps 方面,确保代码质量并防止有缺陷的软件被部署到线上;在 AI for Customer 方面,如何有效提升客户体验等。
在所有这些场景中,有四个主要的问题类别,它们一起构成了 AIOps 的主要研究领域:检测、诊断、预测和优化。具体而言,“检测”的目的是及时地识别异常的系统行为或状态。“诊断”的目标是找出服务系统问题的原因并定位其根源所在。“预测”则旨在对系统行为、用户工作负载或 DevOps 活动等进行预判。最后,“优化”是找出最佳策略或决策,以全面优化与系统质量、客户体验和 DevOps 生产力相关的特定性能。
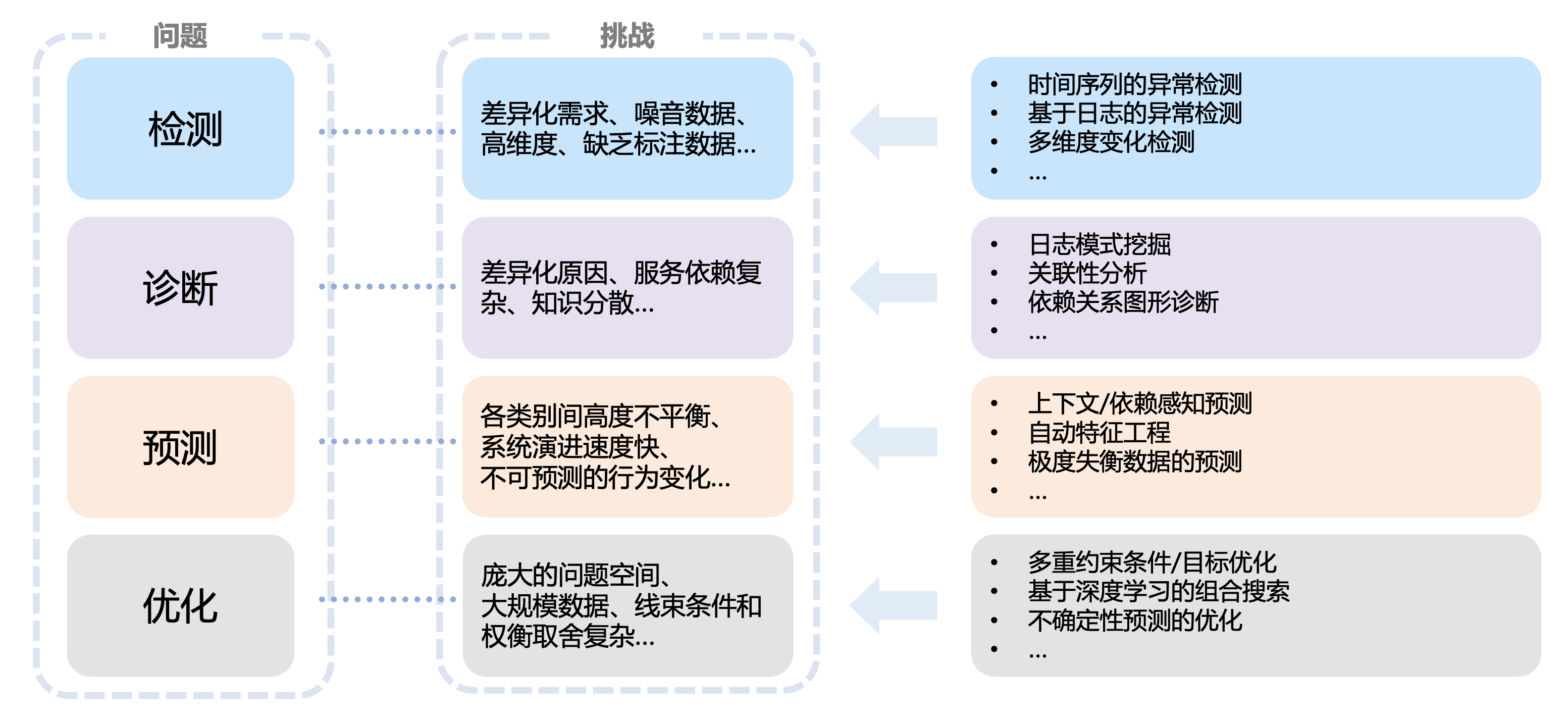
图2:AIOps 的研究领域及面临的挑战
从图2中可以看到,每类问题都面临着各自不同的挑战。以“检测”为例:为了确保服务运行时状况良好,工程师必须不断监控各种指标并及时检测异常情况;在开发过程中,为了确保持续集成/持续发布(CI/CD)等业务实践的质量,工程师需要创建一些机制识别有缺陷的软件版本,并防止它们被部署到生产环境中。这两种情况都需要及时检测,在应用 AI/ML 方法时也存在着共同的挑战。例如,时间序列数据和日志数据是最常见的数据输入形式,然而它们通常是多维度的,数据中可能存在噪声,这都会对可靠的检测构成重大挑战。
微软研究院AIOps的愿景:更自主、更前瞻、更全面、更易管理
微软正在针对 AIOps 的每一类问题进行持续研究,目标是让整个云系统的每一层都变得更自主、更前瞻,更全面、更易于管理。
让云系统更自主
AIOps 致力于让云系统变得更加自动并更有自主性,最大限度地减少人工操作,降低维护成本,结合全局信息做出更合理的决策,从而避免系统问题对用户的影响。为此,要尽可能地实现 DevOps 自动化和自主化,包括开发、部署、监控和问题诊断。例如,安全部署的目的是及早发现有缺陷的软件版本,防止其部署到线上对用户造成重大影响。对于工程师而言,人工识别有缺陷的软件版本是非常耗时耗力的,因为异常行为有多种模式,随着时间的推移这些模式还会发生变化,而且并不是所有的异常行为都是由新版本引起的,这就可能会导致误报。
微软研究院的研究员们借助迁移学习和主动学习技术,开发了一套安全部署解决方案来克服上述挑战。这套解决方案已经运行在微软 Azure 云计算平台中,它在帮助识别缺陷版本方面非常有效,在18个月内,实现了90%以上的准确率和几乎100%的召回率。
相关论文:
An Intelligent, End-To-End Analytics Service for Safe Deployment in Large-Scale Cloud Infrastructure
AIOps 自动自主化的另一种方法是自动根因分析。为了缩短处理时间,工程师必须快速确定云系统故障发生的根源所在。然而,由于云系统结构的复杂性,故障告警通常只包含部分信息,并且一个故障可能同时触发多个服务和组件,因此工程师在采取有效措施之前,不得不花费大量的时间来诊断问题的根本原因。通过先进的对比挖掘算法(contrast-mining algorithms),微软研发了包括多层次故障定位(Hierarchy-aware Fault Localization)和故障影响范围评估(Outage-impact Scope)在内的故障自主诊断系统,在缩短响应时间的同时,提升了故障诊断任务的准确性。这些系统现已集成至微软 Azure 云计算平台和 Microsoft 365(M365)中,提高了工程师在云系统中快速准确处理故障的能力。
相关论文:
Fast Outage Analysis of Large-scale Production Clouds with Service Correlation Mining
HALO: Hierarchy-aware Fault Localization for Cloud Systems
Onion: Identifying Incident-indicating Logs for Cloud Systems
让云系统更具前瞻性
AIOps 通过引入“前瞻性设计”的概念,让云系统变得更具前瞻性。前瞻性系统设计是在传统系统中添加了基于机器学习的预测组件。预测系统通过对大量历史数据的学习获得预测模型,并结合当前的系统状态,以预测系统的未来状态。例如,预测某个服务器集群下一周的资源容量状态,磁盘是否会在未来几天内出现故障,或者未来一小时内需要创建的特定类型虚拟机的数量。
了解了未来的状态,就能够主动避免对用户的负面影响。例如,工程师可以把未来将会出故障的计算节点上的服务实时迁移到健康的计算节点上,以减少虚拟机的停机时间,或者在未来一小时预配置特定类型和数量的虚拟机,以减少配置虚拟机所需的等待时间。此外,AI/ML 技术还可以使系统随着时间的推移不断学习来调整以达到适应当前系统的最优决策。
作为前瞻性设计的范例之一,微软研究院的研究员们构建了一个名为 Narya 的系统,它能够主动处理潜在的硬件故障,以减少服务中断并把对用户的影响降至最低。运行在微软 Azure 云计算平台中的 Narya,可以对硬件故障进行预测,并使用增强学习算法来决定采取何种最优化的处理措施。
相关论文:
Correlation-Aware Heuristic Search for Intelligent Virtual Machine Provisioning in Cloud Systems
Intelligent Virtual Machine Provisioning in Cloud Computing
Predictive and Adaptive Failure Mitigation to Avert Production Cloud VM Interruptions
让AIOps在云堆栈中的应用更全面
AIOps 还可以扩展到整个云堆栈,从底层的基础设施层(如网络和存储)到服务层(如调度器和数据库)再到应用层,从而让 AIOps 变得更全面。广泛应用 AIOps 的好处在于可显著提高整体诊断、优化和管理能力。
构建在 Azure 之上的微软服务被称为第一方(1P)服务。微软 1P 服务的范例包括 Office 365 等大规模的成熟服务、Teams 等相对较新但规模较大的服务,以及 Windows 365 Cloud PC 等即将推出的服务。1P 服务中的单个实体可以看到并控制云堆栈的各个层,通常会占用大量的资源,比如广域网(WAN)流量和计算资源等,是应用更全面的 AIOps 方法的重要场景。
作为将更加全面的 AIOps 方法应用于 1P 设置的示例,由 Azure、M365 和微软研究院联合开发的 OneCOGS 项目考虑了三类广泛的优化机会:
1. 使用跨层信号对用户及其工作负载进行建模,例如使用用户的消息活动与固定工作时间的对比来预测 Cloud PC 用户何时将处于活动状态,从而提高准确性,实现系统资源的合理分配。
2. 通过应用程序和基础架构的联合优化,实现成本节约等好处。
3. 控制数据和配置的复杂性,实现 AIOps 的通用化。
用于云计算平台和 1P 服务的 AIOps 方法、技术及实践,同样适用于云堆栈上的第三方(3P)服务。若要实现这一目标,就需要进一步的研究和开发,让 AIOps 方法和技术变得更通用和更易适配。例如,在运行云服务时,检测多维数据中的异常以及随后的故障定位,就是常见的监控和诊断问题的方法。
基于 Azure 云和 M365 的实际需求,微软的研究员们提出了 AiDice 技术和 HALO 技术,前者可以自动检测多维时间序列中的异常,后者是一种层次感知方法,使用从云系统中收集的运行数据对故障组合进行自动定位。除了在 Azure 和 M365 中部署 AiDice 和 HALO 之外,研究员们还与产品团队合作,正在开发可供第三方服务使用的 AiDice 与 HALO AIOps 服务。
相关链接:
Efficient incident identification from multi-dimensional issue reports via meta-heuristic search
让云系统更易管理
通过引入分层自治的概念,AIOps 让云系统变得更易于管理。层级包括了从自动日常操作的顶层,到需要深厚的专业知识来应对罕见和复杂问题的底层。由于系统的复杂性,AI 驱动的自动系统管理通常无法处理所有不同类型的问题,因此,研究员们通过构建针对每一层的 AIOps 解决方案,让云平台可以更简便地管理复杂系统中不可避免的长尾罕见问题。此外,分层的设计也确保了自主系统从开发阶段起,就能够评估确定性和风险,并在自动化故障或平台面临前所未有的情况时具有安全回滚的保障,例如2020年由新冠疫情导致的意外的需求增加。
分层自治的范例之一是微软的研究员们构建的安全的节点在线学习(Safe On-Node Learning,SOL),这是一个在顶层服务器节点上进行安全学习和驱动的框架。另一个范例是,研究员们正在探索如何预测运维人员在处理故障时应执行的命令,同时考虑在顶层自动化无法防止故障发生时,衡量与这些命令相关的确定性和风险。
相关论文:
SOL: Safe On-Node Learning in Cloud Platforms
AIOps已在Azure和M365中大显身手
AIOps 是一种迅速兴起的技术趋势,也是结合系统、软件工程和 AI/ML 等领域的跨学科研究方向。通过多年的云智能研究,微软研究院在检测、诊断、预测和优化等方面积累了丰富的经验和成果。通过与 Azure 和 M365 团队的密切合作,相关研究成果也已经在云系统中进行部署,在改善 Azure 和 M365 的可靠性、性能和资源效率的同时,也提高了产品开发人员的生产力。此外,微软研究院正在与学术界和工业界的同行展开合作,推进 AIOps 的研究和应用实践。例如,在各方的共同努力下,以 AAAI 2020、ICSE 2021 和 MLSys 2022 等顶尖学术会议为依托,微软研究院的研究员们已经组织了三期 AIOps 研讨会。
展望未来,微软相信云智能/AIOps作为一个全新的创新维度,将发挥越来越重要的作用,使整个云系统变得更加自主、前瞻、全面和易于管理。云智能/AIOps 终将助力实现人们对于云计算的未来愿景。
本文作者:微软杰出首席科学家、微软亚洲研究院常务副院长张冬梅,首席研究员林庆维;微软印度研究院副院长 Venkat Padmanabhan,首席研究员 Ranjita Bhagwan;微软 Azure 杰出工程师 Ricardo Bianchini,高级研究工程师 Dan Crankshaw






