
代码智能新基准数据集CodeXGLUE来袭,多角度衡量模型优劣
2020-09-29 | 作者:自然语言计算组
编者按:代码智能(code intelligence)目的是让计算机具备理解和生成代码的能力,并利用编程语言知识和上下文进行推理,支持代码检索、补全、翻译、纠错、问答等场景。以深度学习为代表的人工智能算法,近年来在理解自然语言上取得了飞跃式的突破,代码智能也因此获得了越来越多的关注。该领域一旦有突破,将大幅度推动 AI 在软件开发场景的落地。
一直以来,微软秉承为开发者赋能的使命。在2020年 Build 大会上,微软首席执行官 Satya Nadella 表示,“GitHub 拥有超过5000万用户,Visual Studio Code 是最受开发者欢迎的代码编辑器。微软将为开发者打造最完整的开发工具链,结合 GitHub、Visual Studio 和 Azure,帮助开发者实现从想法到代码、从代码到云的转化。”同时,微软在自然语言理解和深度学习领域有着深厚的积累,不只有大数据、大模型、强算力支撑着模型的训练,还有丰富的模型部署及优化经验,帮助人工智能算法真正落地到产品中。
基准数据(Benchmark Dataset)对一个领域的发展至关重要。例如,ImageNet(斯坦福大学)极大地推动了计算机视觉领域的发展,类似包含多种任务的 GLUE(纽约大学)和 XGLUE(https://microsoft.github.io/XGLUE/,微软亚洲研究院自然语言计算组)数据集在自然语言处理领域也产生了非常深远的影响。近年来,统计机器学习算法,尤其是深度学习算法在很多代码智能任务(如代码检索、代码补全、代码纠错)上都取得了不错的进展,但是,代码智能领域仍缺少一个能覆盖多种任务的基准数据,以便从不同角度衡量模型的优劣。
近期,微软亚洲研究院(自然语言计算组)联合 Visual Studio 和必应搜索发布了代码智能领域首个大规模多任务的新基准——CodeXGLUE(https://github.com/microsoft/CodeXGLUE)。该基准可覆盖 code-code、code-text、text-code、text-text 四个类别,包含10个任务及14个数据集,具体有:代码克隆检测、代码缺陷检测、代码完形填空、代码补全、代码纠错、代码翻译、代码检索、代码生成、代码注释生成、代码文档翻译十项任务。其中,有自建数据集,也有在业界已有影响力的数据集。
十项全能评测集上线
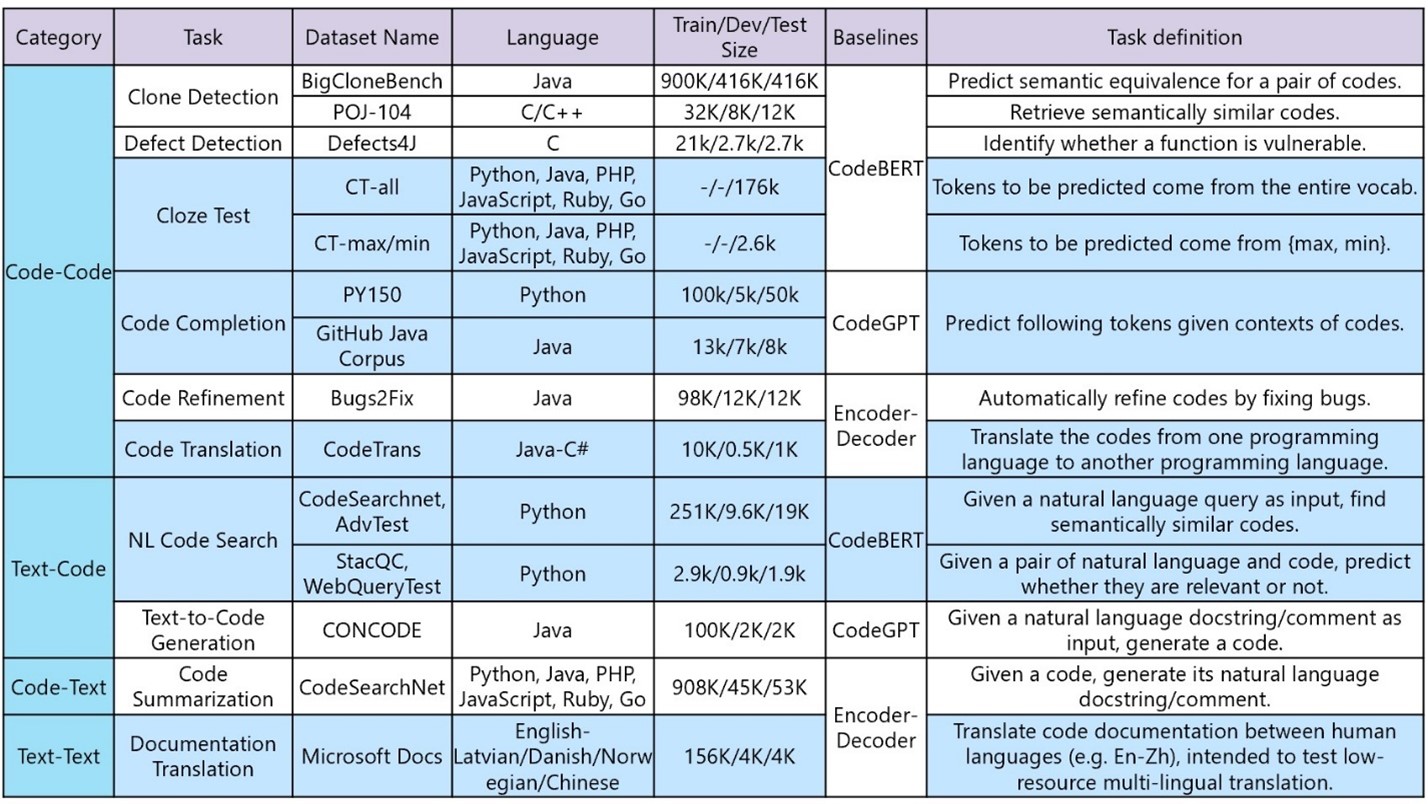
具体来说,CodeXGLUE 中包含如下十项任务:
1. 代码克隆检测(Clone Detection)。该任务是为了检测代码与代码之间的语义相似度,包含两个外部公开数据集,但任务定义稍有不同。在第一个数据集中,给定两个代码作为输入,要求做0/1二元分类,1表示两段代码语义相同,0表示两段代码语义不同。在第二个数据集中,则给定一段代码作为输入,任务是从给定的代码库中检索与输入代码语义相同的代码。
2. 代码缺陷检测(Defect Detection)。该任务是检测一段代码是否包含可以导致软件系统受到攻击的不可靠代码,例如资源泄露、UAF 漏洞和 DoS 攻击等。该任务中使用了外部公开数据集。
3. 代码完形填空(Cloze Test)。先给定一段代码,但代码中的部分内容被掩盖住,该任务要求预测出被掩盖的代码。研究员们将该任务定义为多项选择题的形式,并构建了两个数据集。在第一个数据集中,被掩盖住的代码可以来自于代码中的任意字符;在第二个数据集中,则试图更有针对性地测试系统对代码 max、min 函数的理解能力。
4. 代码补全(Code Completion),也就是给定已经写好的部分代码。该任务能够自动预测出后续的代码,具体包含两个设置,分别是词汇级别(Token-level)和行级别(Line-level)的补全。顾名思义,前者的任务是补全下一个词汇,而后者的任务是补全一整行代码。词汇级任务使用了两个被外部广泛使用的数据。行级别的任务则是在词汇级别任务的数据上自动构建的数据。
5. 代码翻译(Code Translation)。该任务是把代码从一种编程语言翻译到另一种编程语言。研究员们构建了一个 Java 到 C# 的代码翻译数据集。
6. 代码检索(Code Search)。该任务是为了检测自然语言与代码之间的语义相似度,包含两个数据集,具体定义稍有不同:在第一个数据集中,给定一个自然语言作为输入,任务是从给定代码库中检索与输入自然语言语义最相近的代码,研究人员为该数据新构建了一个测试集,用来更好地测试系统的深层语义理解能力。在第二个数据集中,给定自然语言-代码对作为输入,要求系统做0/1二元分类,1表示语义相似,0表示语义不相似,研究员们同样为该任务构造了新的测试数据集,测试数据的自然语言来自必应搜索引擎,可以更好地反应真实用户的查询习惯。
7. 代码纠错(Code Refinement)。 给定一段有 bug 或者复杂的代码作为输入,该任务要求生成被优化后的代码。该任务中使用了一个外部公开的数据集。
8. 代码生成(Text-to-code Generation)。给定自然语言注释作为输入,该任务要求自动生成函数的源代码。该任务中使用了外部的公开数据集。
9. 代码注释生成(Code Summarization)。给定一段函数代码作为输入,该任务要求自动生成对应的自然语言注释。该任务中使用了外部公开数据集。
10. 文档翻译(Documentation Translation)。该任务的目的是自动将代码文档从一种自然语言翻译到另一种自然语言,如从英文翻译到中文。该任务中构建了新的数据集。
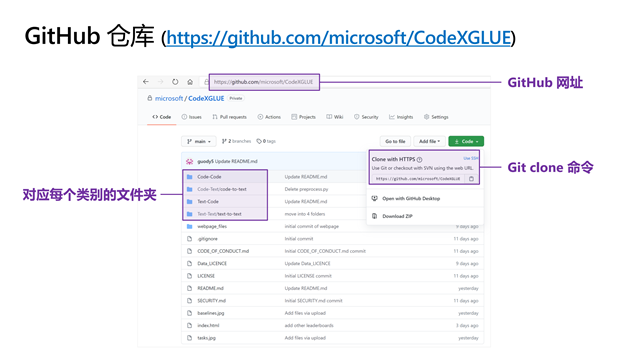
CodeXGLUE 发布在 GitHub 上,参赛者可首先通过 Git Clone 命令下载全部资源。最外层目录对应了四个任务分类,即 Code-code、 Code-text、Text-code 和 Text-text。研究员们为每个任务和数据集都创建了子文件夹,其中包括数据、代码、评测脚本以及说明文档。对于来自外部的公开数据集,则提供了数据下载的脚本;同时,对于需要做预处理的部分数据,也提供了预处理的脚本。
三大基线系统模型:CodeBERT、Encoder-Decoder和CodeGPT
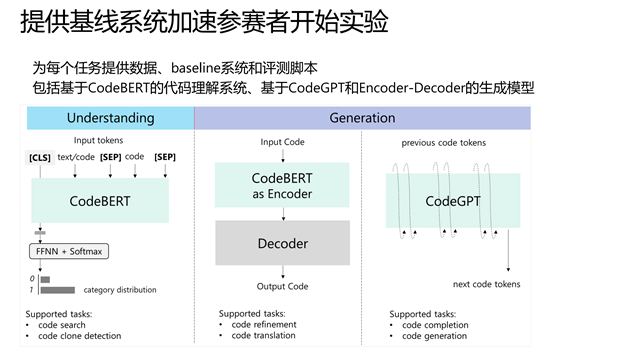
为了让参赛者更容易参与到 CodeXGLUE 中,研究人员为每个任务搭建了目前较为流行的、基于神经网络的基线系统(Baseline)。这些基线系统可以被归为三类:第一类是基于 CodeBERT 预训练模型的系统,能够支持如分类、检索等代码理解任务;第二类是基于 CodeGPT 预训练模型的系统,能够支持代码补全和代码生成任务;第三类是编码器-解码器模型(Encoder-Decoder),能够更好地支撑如代码翻译、代码纠错等生成任务。下图给出了三类基线系统的总况,接下来将分别对每个基线系统进行介绍。
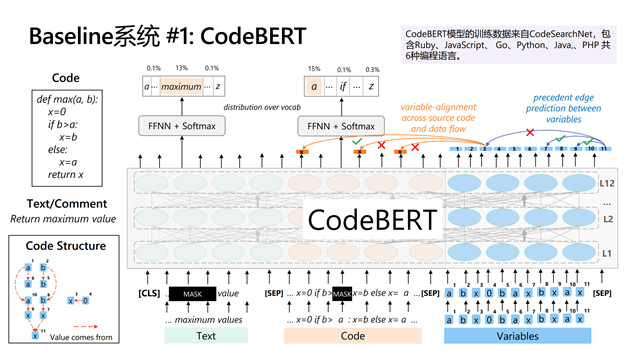
基于 CodeBERT 预训练模型的系统:在自然语言处理领域,BERT 在诸多自然语言理解任务中都展现了非常出色的性能。BERT 的基本思想是把模型的学习过程分为预训练(Pre-training)和微调(Fine-tuning)两个步骤。在预训练阶段,BERT 会从海量无标注的文本中通过自监督优化目标,如语言模型和掩码语言模型,学习通用的词汇上下文语义表示;在微调阶段,已经训练好的模型参数会在下游任务的标注数据上进行微调。受 BERT 的启发,研究员们为参赛者提供了 CodeBERT 模型,即面向编程语言的预训练模型。
CodeXGLUE 中的很多任务同时涉及到文本和代码,因此该系统提供了在 code-text pair 上预训练的 CodeBERT 模型。该模型在训练过程中同时会把代码和文本作为输入,这样的设置可促进模型学习文本和代码之间的语义交互(相关论文:CodeBERT: A Pre-Trained Model for Programming and Natural Languages,https://arxiv.org/abs/2002.08155)。由于代码严格遵循编程语言的语法规范,所以代码的内容具有很强的结构性,基于这点考虑,研究人员进一步提出了一种融合代码结构的预训练模型,如下图所示。具体来说就是利用代码的数据流信息,并围绕数据流提出了两种新的预训练任务。模型的具体细节可参见论文:GraphCodeBERT: Pre-training Code Representations with Data Flow (https://arxiv.org/abs/2009.08366 )。
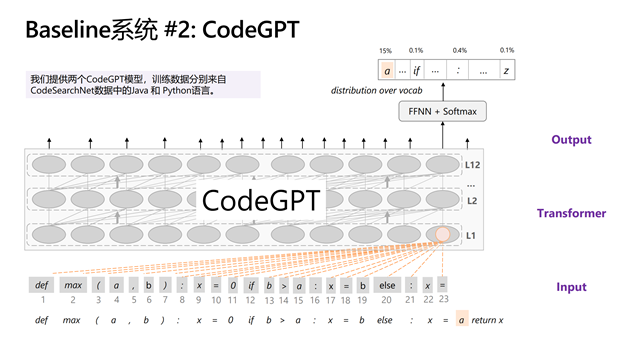
基于 CodeGPT 预训练模型的系统:GPT 模型在自然语言生成任务上取得了非常出色的效果,也有学者发现在编程语言上预训练 GPT 模型在代码生成任务上表现得很不错。为了帮助参赛者更快地搭建模型,研究员们分别在 Python 和 Java 两种编程语言上预训练了 GPT 模型,称之为 CodeGPT(如下图所示)。模型的训练数据来自CodeSearchNet,训练目标是传统的语言模型。参赛者只需在下游任务中对 CodeGPT 进行微调,即可在代码生成和补全任务上取得当前最好的性能。
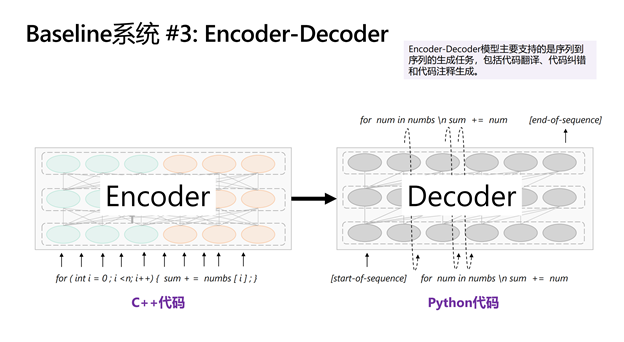
编码器-解码器模型系统:为了支持如代码翻译、代码纠错等 Sequence-to-sequence 生成问题,该系统提供了基于 Transformer 的 Encoder-Decoder 框架。下图展示了一个 C++ 到 Python 的代码翻译样例,Encoder 端接收了 C++ 的代码作为输入,Decoder 端序列化地输出了 Python 代码。模型的框架也支持在 Encoder 端使用 CodeBERT 初始化模型参数,以更好地表示代码的语义。
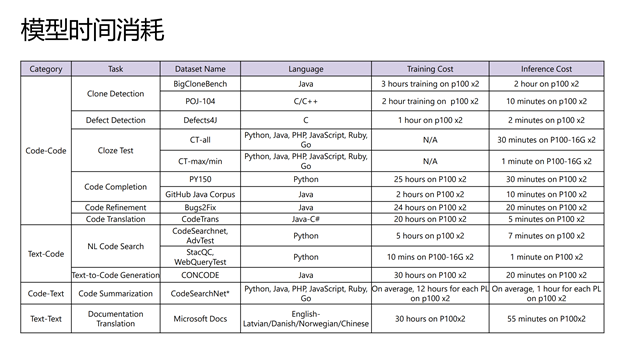
研究人员在两个 P100 GPU 上计算了每个数据集上进行模型训练和推理的时间,如下表所示。可以看出,模型训练时长在一小时到三十小时内,推理的过程则更快,最快的数据仅需要几分钟,最耗时的需要两个小时。这样的资源消耗通常是可以被大部分参赛者所接受的。
全新评测指标CodeBLEU,定义模型优劣标准
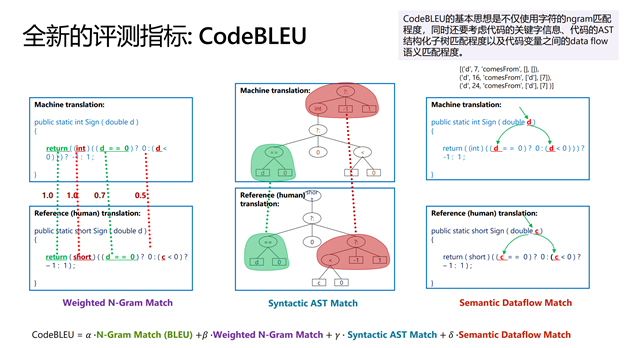
评测指标的选取至关重要,它定义了区分模型优劣的标准。目前,业界大多使用 BLEU 评价生成代码的质量,其基本思想是计算生成代码和标准答案代码 ngram 的匹配程度。然而,代码蕴含着丰富的语法和语义结构,BLEU 无法捕捉代码的结构特性。因此,微软亚洲研究院的研究员们提出了 CodeBLEU 来更好地评价自动生成代码的质量。CodeBLEU 的基本思想是不仅使用字符的 ngram 匹配程度,还要同时考虑代码的关键字信息、AST 结构化子树信息以及代码变量之间的数据流信息。CodeBLEU 的最终结果由各个子部分加权求和获得。
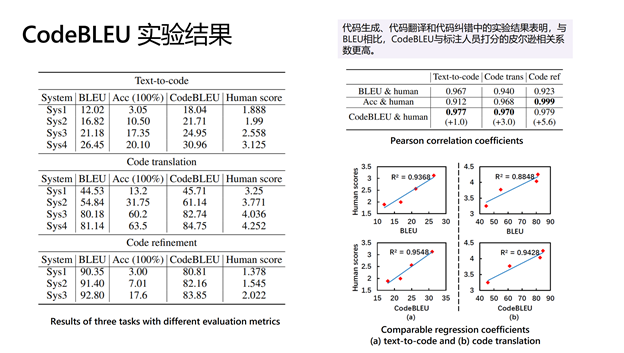
为了验证 CodeBLEU 指标的有效性,研究人员分别在代码生成、代码翻译和代码纠错上进行了实验。不仅为每个任务提供了多个系统的模型输出,并分别使用 BLEU、CodeBLEU 评测各个系统,此外还请了熟悉编程语言的人工标注人员为每个模型的输出打分。通过下图可以看出,CodeBLEU 与标注人员打分的皮尔逊相关系数更高,从而验证了该指标的有效性。更多细节,请参见论文:CodeBLEU: a Method for Automatic Evaluation of Code Synthesis (https://arxiv.org/abs/2009.10297 )。
为了方便研究人员使用,微软亚洲研究院的研究员们还为每个任务和数据集提供了基线系统。欢迎学术界和工业界的同行来了解和使用 CodeXGLUE,也欢迎大家提供宝贵的意见和建议。
CodeXGLUE团队成员:
Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Daya Guo, Duyu Tang, Junjie Huang, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, Shuai Lu, Shujie Liu, and Shuo Ren.
CodeXGLUE:https://github.com/microsoft/CodeXGLUE






