
CVPR 2023 | 计算机视觉顶会亮点前瞻
2023-06-14 | 作者:微软亚洲研究院
在知识和技术都迅速更新迭代的计算机领域中,国际计算机视觉与模式识别会议(CVPR)是计算机视觉方向的“顶级流量”,引领着学科及相关领域的研究潮流。今天我们为大家带来5篇微软亚洲研究院被 CVPR 2023 收录的论文,主题涵盖手语识别与检索、多模态生成、图像编辑、视频理解任务等。
4月,微软亚洲研究院举办了 CVPR 2023 论文分享会,点击链接直达精彩论文分享回顾。
CiCo:基于跨语言对比学习的域可感知手语检索

论文链接:https://arxiv.org/pdf/2303.12793.pdf
代码链接:https://github.com/FangyunWei/SLRT
最近,手语理解领域中提出了全新的手语检索任务,包含文本-手语视频检索、手语视频-文本检索两个子任务。与传统的视频文本检索不同,手语视频不仅包含视觉信号,作为一种自然语言,它还承载着丰富的语义信息。对此,微软亚洲研究院的研究员们将手语检索同时定义为视频文本检索问题和跨语言检索问题,提出了基于跨语言对比学习的域可感知手语检索算法 CiCo。
根据手语和自然语言的语言特性,CiCo 通过对比学习的方式将文本和手语视频映射至联合嵌入空间,同时学习识别细粒度的手语到单词的跨语言映射。另外,为了缓解手语检索任务的数据稀缺问题,研究员们引入了在大规模手语视频数据集上预训练的域无关手语编码器,并生成了伪标签标注来微调编码器,从而获得适用于目标域的域可感知手语编码器。CiCo 在多个数据集上显著超越了现有方法,例如,在 How2Sign 数据集上取得了 T2V+22.4 和 V2T+28.0 的 R@1 提升。研究员们希望 CiCo 可以成为手语检索中可靠的基准模型。
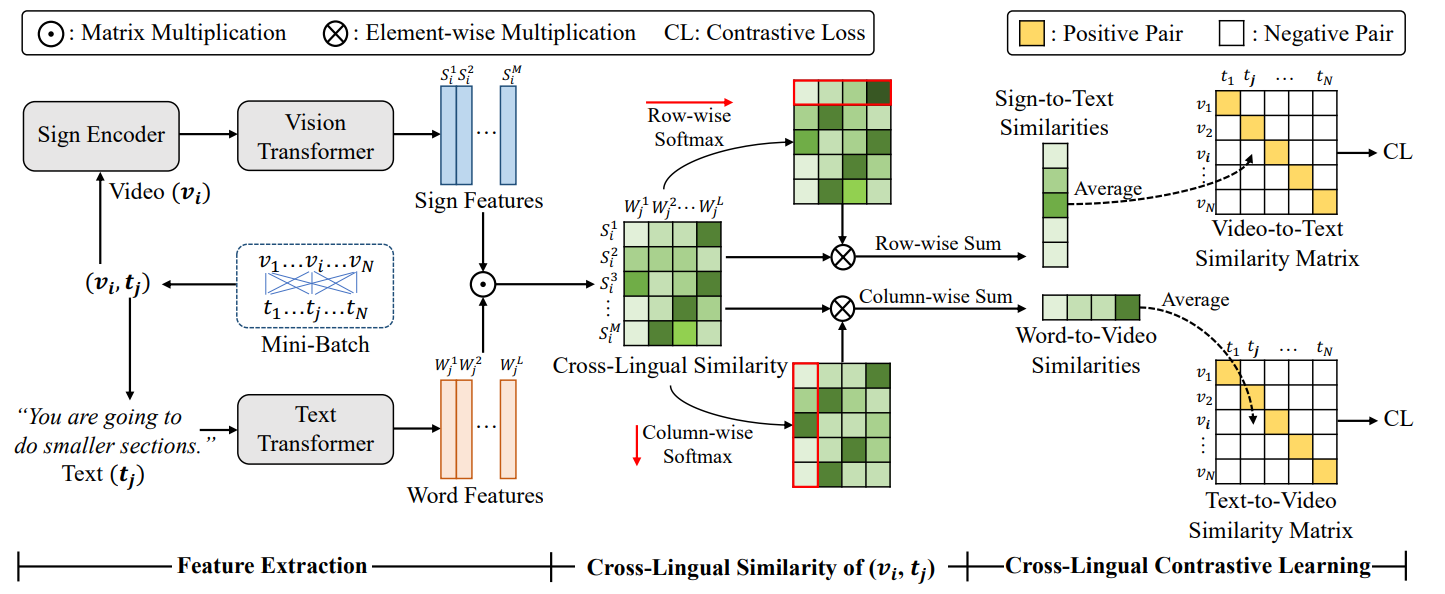
图1:CiCo 的模型框架
自然语言辅助的手语识别

论文链接:https://arxiv.org/abs/2303.12080
代码链接:https://github.com/FangyunWei/SLRT
广泛应用于聋哑人群体的手语是一种通过视觉信号传递信息的语言。然而,大量视觉上相似的手势极大地限制了手语识别模型的准确率。虽然这些手势难以只凭眼力区分,但它们的文本标签(通常为一个单词)却可以提供更多有用的信息。因此,研究员们提出了自然语言辅助的手语识别模型(NLA-SLR)。
首先,对于语义相似的手势,研究员们提出了自然语言感知的标签平滑。如图2(a)所示,在训练过程中计算当前手势标签与词汇表中每个标签的语义相似度,并根据相似度向量生成软化标签作为优化目标。这一技术能够有效正则化模型,降低训练难度。其次,对于语义差别大的手势,研究员们提出了跨模态混合,如图(b)所示通过将训练过程中模型的视觉特征与词汇表中的文本特征一一混合,并设计相应的跨模态混合标签,能够在自然语言的帮助下提高手势的可分性,从而提升模型性能。最后,经过三个广泛使用的标准数据集中的验证, NLA-SLR 均达到了最高的识别准确率。

图2:(a)基于语义相似性的标签平滑;(b)跨模态特征混合。
MM-Diffusion:生成音视频的双模态扩散模型

论文地址:https://arxiv.org/abs/2212.09478
代码地址:https://github.com/researchmm/MM-Diffusion
近年来,扩散模型已经在图像、视频、音频等领域取得了显著的成果。但是目前的研究主要聚焦在视觉或听觉的单模态生成,这样生成出来的内容与真实网络世界的视频依然有较大差距,不符合人们的视听习惯。同时,从研究的角度出发,视频和音频在时序上也是天然对齐的。因此,这篇工作旨在探索音视频双模态同时生成的新方法。研究员们提出了基于双流 U 形网络的多模态扩散模型 MM-Diffusion。该方法不仅在音视频单模态质量的对比超过了当前的最佳方法,还在同步生成视频-音频任务中验证了能提高声、画各自模态的生成质量。
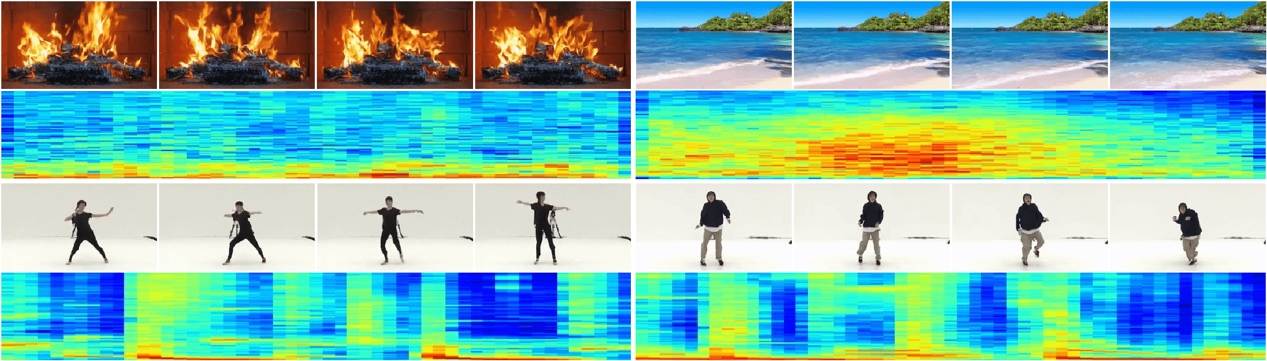
图3:视频-音频生成样例
MM-Diffusion 首先将只能构建单个分布的扩散模型机制扩展到构建多个分布(如图4所示)。由于音视频分布的形状不同、模态差异较大,前向扩散过程的加噪处理需要独立进行,但由于音视频的相关性,反向逆扩散过程则采取了一个统一的音视频模型同时降噪双模态。
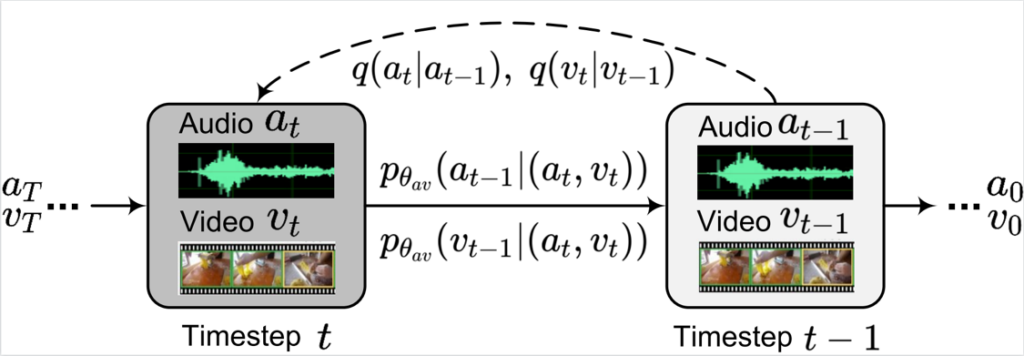
图4:MM-Diffusion 示意图
为了构建适配音视频的统一降噪模型,研究员们提出了双流 U 形网络。如图5所示,双流 U 形网络由音频子网络和视频子网络构成。音频子网络以空洞卷积为主要结构,对音频一维波形数据进行长时序建模;视频子网络采用二维一维卷积层和二维一维注意力机制,对视频三维数据进行时空建模。之后,在若干相交节点对两支子网络做跨模态对齐。然而由于音视频两个模态的像素空间都非常巨大,直接使用跨模态注意力机制对齐并不现实。为此,研究员们设计了基于随机偏移的注意力机制,用局部的注意力机制的运算类推,进而起到全局对齐的效果。
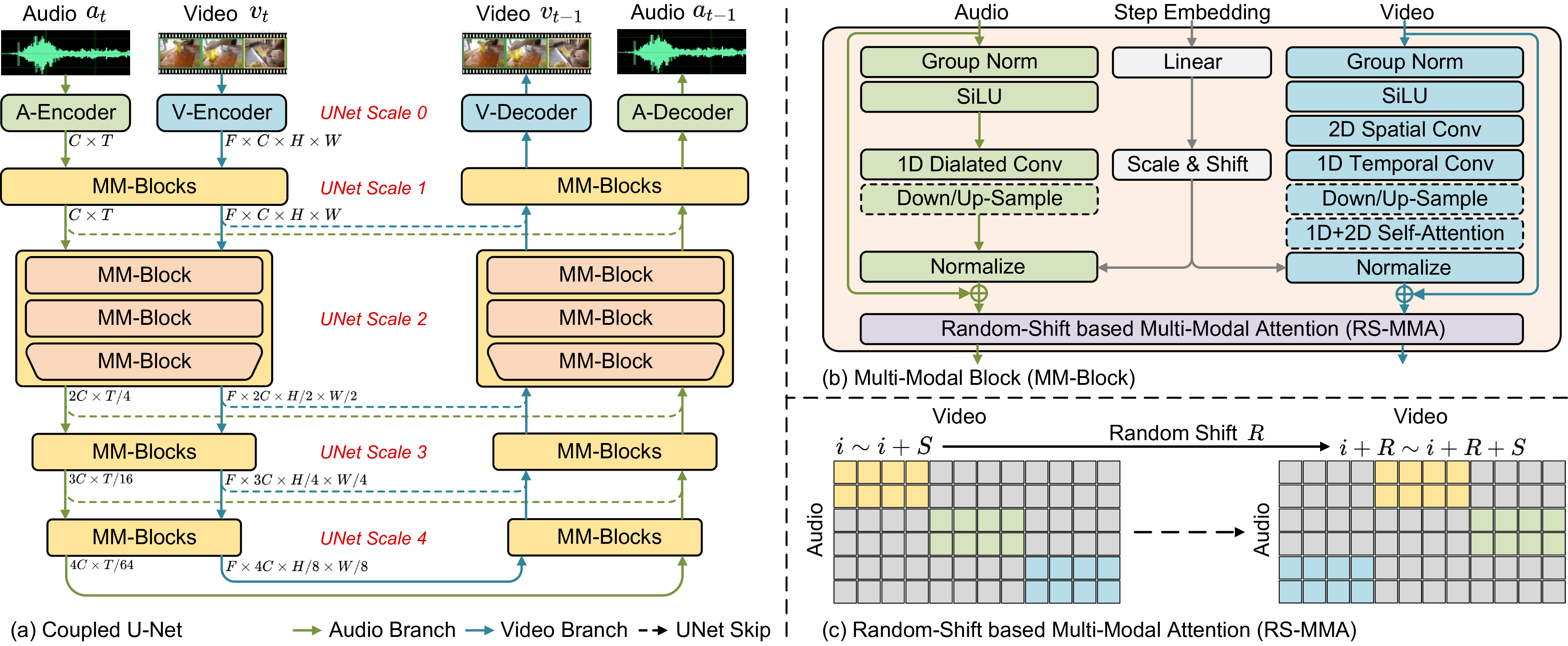
图5:双流 U 形网络模型图
研究员们在不同的数据集上验证了 MM-Diffusion。实验证明,不论是客观指标还是主观评测,MM-Diffusion 均超过了之前可复现单模态生成的 SOTA。该工作同时还证明了对比单模态生成,两个模态同时生成质量会更高,除此之外,研究员们进一步验证了 MM-Diffusion 具备 zero-shot 条件生成的能力(输入视频生成对应音频或反之)。
基于样例的图像编辑

论文链接:https://arxiv.org/pdf/2211.13227.pdf
代码链接:https://github.com/Fantasy-Studio/Paint-by-Example
许多最新的研究成果在基于文本的图像编辑领域都取得了巨大成功。然而,就像俗语所说“一图胜千言”,相比文本,图像能够更加形象、直接地表达用户所期待的图像编辑结果。因此,研究员们首次探索了基于参考图像的图像编辑任务,以实现更精确的图像编辑。
为了实现这个目标,研究员们通过自监督的训练方式解耦和重组原始图像与参考图像。然而,直接重组会导致生成结果含有明显的伪影。研究员们分析了出现伪影的原因,并且提出了一个压缩瓶颈和强大的数据增广策略,以避免网络直接复制和粘贴参考图像。同时,为了保证编辑过程的可控性,研究员们为参考图像设计了一个任意形状的掩膜,并利用 Classifier-free guidance 来提升生成结果与参考图像的相似度。在使用时,整个框架仅需要一次扩散模型的去噪过程,无需任何迭代优化。研究员们证明了该方法性能的优越,且能够在真实世界的图像上进行可控的高保真编辑。

图6:根据示例进行编辑可自动地将参考图像融合到源图像中,从而达到高质量的编辑效果
流式视频模型

论文链接:https://arxiv.org/abs/2303.17228
代码地址:https://github.com/yuzhms/Streaming-Video-Model
视频理解包含基于序列(sequence-based)和基于帧(frame-based)两类任务,它们通常分别采用两种独立架构进行建模。基于序列的视频任务(如动作识别)使用视频主干网络直接提取时空特征,而基于帧的视频任务(如多目标跟踪,MOT)则依赖于图像主干网络提取空间特征。相较之下,研究员们提出了一个统一了视频理解任务的新颖的流式视频架构(Streaming Video Model),该架构既解决了视频主干网络因显存消耗无法处理长视频的问题,又弥补了图像主干网络在时序建模方面的不足。
具体而言,本文的流式视频模型由一个时序感知空间编码器(temporal-aware spatial encoder)和一个与任务相关的时序解码器(temporal decoder)组成。编码器为每个视频帧提取包含时序信息的空间特征,而解码器则负责将帧级特征转换为基于序列任务的特定输出。与使用图像主干网络的基于帧的架构相比,流式视频模型的时序感知空间编码器利用了来自过去帧的附加信息,提升了特效的强度和稳健性。与使用视频主干网络的基于片段的架构相比,流式视频模型分离了帧级特征提取与片段级特征融合,减轻了计算压力,同时适用于更灵活的使用场景,如长视频推理或在线视频推理。本文的模型基于视觉 Transformer 构建,其中帧内使用自注意力(self-attention)以提取空间信息,帧间使用跨注意力(cross-attention)以融合时序信息。
文章中提出的流式视频模型在 Kinetics400, Something-Something v2 等动作识别数据集上取得了 SOTA 的性能,在 MOT17 多目标跟踪数据集上也取得了有竞争力的结果。这些实验都证明了流式视频模型在两类任务上的通用性和有效性。
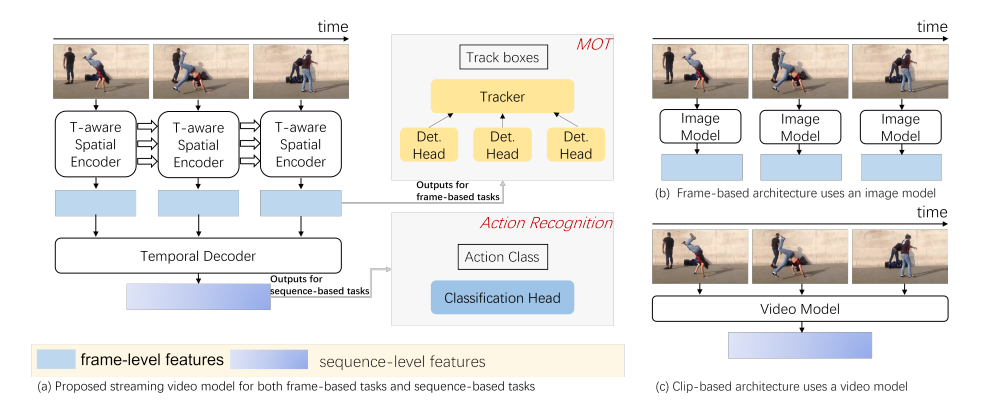
图7:流式视频模型的示意图(左侧),以及与传统的基于帧的架构和基于片段的架构进行的比较(右侧)
随着人工智能技术的快速发展,确保相关技术能被人们信赖是一个需要攻坚的问题。微软主动采取了一系列措施来预判和降低人工智能技术所带来的风险。微软致力于依照以人为本的伦理原则推进人工智能的发展,早在2018年就发布了“公平、包容、可靠与安全、透明、隐私与保障、负责”六个负责任的人工智能原则(Responsible AI Principles),随后又发布了负责任的人工智能标准(Responsible AI Standards)将各项原则实施落地,并设置了治理架构确保各团队把各项原则和标准落实到日常工作中。微软也持续与全球的研究人员和学术机构合作,不断推进负责任的人工智能的实践和技术。






