
LLM时代,探索式数据分析的升级之路有哪些新助攻?
2023-05-31 | 作者:马平川、丁锐
在这个信息爆炸的时代,数据已经成为我们生活、工作中不可或缺的重要资源。大量的数据犹如一座座金矿,蕴藏着无尽的价值。然而,如果无法从数据中提取出知识和信息并加以有效利用,那么数据本身并不能驱动和引领技术应用取得成功。如何让数据发挥它最大的价值?是数据、知识与智能(DKI)组持续探索的方向,为了实现这一目标,研究员们在探索式数据分析(Exploratory Data Analysis,EDA)领域进行了一系列的研究工作,相关成果已发表在 SIGMOD 2017、SIGMOD 2019、SIGMOD 2021、KDD 2022 和 SIGMOD 2023 等全球顶会上。同时,该系列工作也已应用于 Microsoft Excel,Microsoft Power BI 和 Microsoft Forms 等微软产品中。
今天的这篇文章将为大家介绍 DKI 组与香港科技大学合作完成的在探索式数据分析领域的成果。让我们一起探讨数据分析的外延和内涵在如何演变,一起了解在大语言模型 LLM(Large Language Model)的强力助攻下,运用数据洞察与因果信息来促进探索数据分析的潜力!
什么是数据洞察(Data Insight)?
“Insight” 在中文中可以翻译为“洞察”。而在这数据分析中,“insight” 是指从多维数据中发现的 interesting data pattern(有趣的数据模式),它反映了数据在某种特定视角下的有趣特征。例如,
- 在销售数据中,发现某个特定产品在某个地区的销售额比其他产品高出很多。
- 在医疗数据中,发现某种疾病的新增患者数目随年份增加。
- 在社交媒体数据中,发现某个话题的讨论量存在周期性规律。
一个具体的洞察反应了人们对数据原始信号的某种特定规律的总结。它有如下特点:洞察是服务于数据分析任务的,往往是对原始信号的某种符号化抽象;相比于原始信号,洞察具有更高的分析语义。基于此,形式化的定义洞察以及如何从数据中挖掘潜在的洞察是一个首要任务。此外,可以预见到,由于洞察具有符号化的属性,基于这些属性的代数操作(当然需要有分析语义)可以进一步扩展分析的广阔空间。
QuickInsights 是一种能够快速自动发现多维数据中洞察的技术。它提出了一种统一定义洞察的抽象方法,将之前提出的不同类型的数据模式归到统一架构下,而且 QuickInsights 的挖掘框架的目标是自动发现高质量、高效率的数据洞察。来自 DKI 组的 QuickInsights 技术已经应用于 Microsoft Excel 和 Microsoft Power BI 等微软产品中。
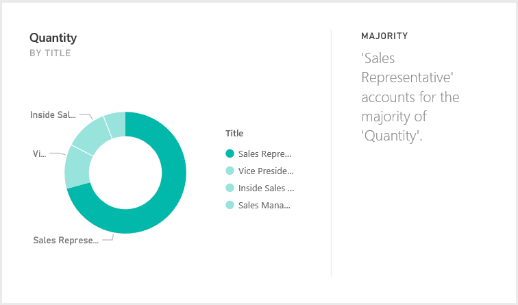
图1:Microsoft Power BI 中的 QuickInsight
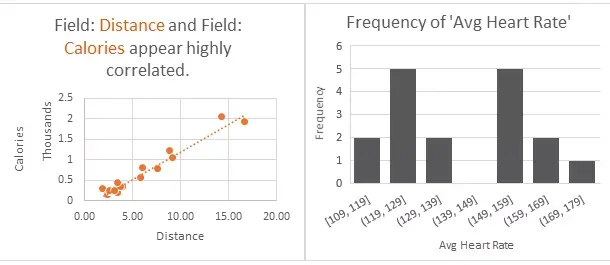
图2:Microsoft Excel 中的 QuickInsight
具体而言,QuickInsight 在以 Analysis Entity(AE,即由
相关论文:
Extracting top-k insights from multi-dimensional data
论文链接:https://dl.acm.org/doi/10.1145/3035918.3035922
Quickinsights: Quick and automatic discovery of insights from multi-dimensional data
论文链接:https://dl.acm.org/doi/10.1145/3299869.3314037
MetaInsight:数据洞察的内涵挖掘之道
在 QuickInsight 的框架下,数据洞察被表征为
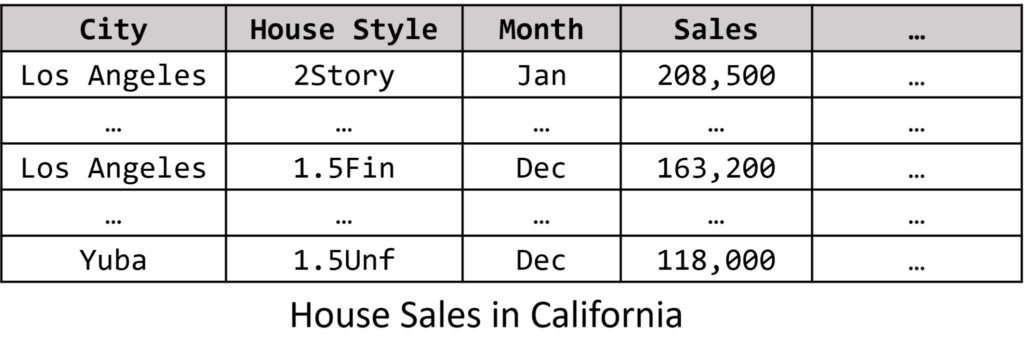

图3:一个典型的探索式数据分析的过程
以一个典型的探索式数据分析的过程为例。如图3所示,假设有一个关于2019年美国加州房屋销售的多维数据。房地产经纪人 Bob 正在分析这个数据集。他首先注意到,与其他月份相比,洛杉矶在4月份的房屋销售量最低。然后,Bob 提出了一个归纳假设(inductive hypothesis):“其他城市的销售情况也同样糟糕。” 通过进一步的数据探索,他了解到这是一个普遍现象,因为还有相当多的其他城市在4月份的销售表现也不佳(commonness,共性)。基于这种共性,Bob 现在开始关注异常情况,他提出了一个验证性质询(validity inquiry):“是不是所有城市在4月份的销售都很差,还是有例外?”经过对加州所有城市的仔细检查,Bob 发现圣地亚哥在7月份的销售情况不佳(exception,异常)。此时,Bob 已经完成了一个探索式数据分析流程,他从数据中得到了以下洞察:首先他提取了一条知识(洛杉矶在4月份的销售表现不佳),并进一步从数据中获得了结构化的知识(除圣地亚哥外,大多数城市在4月份的销售表现不佳)。因此,他希望将这个异常情况(圣地亚哥)作为进一步分析的新起点。
受人类数据分析过程中意义构建机制的启发,MetaInsight 可抽象出“归纳假设”和“验证性质询”两个关键机制,并由此在 QuickInsight 的基础上,获得更具结构化语义的数据洞察。依靠基本的数据洞察机制,MetaInsight 通过捕捉某个特定数据区域(data scope)原始数据分布的关键特征,可实现该数据区域的知识提取。在此基础上,MetaInsight 对其进行扩展,从而获得一系列语义上有归纳潜力的同质数据区域(homogeneous data scope)。例如,针对上述案例洛杉矶房价的这个数据区域,可以将其扩展为不同城市的房价同质数据区域。基于 QuickInsight 在初始数据区域的发现,进而评估同质数据区域内不同数据区域是否呈现出相似的特征,最终可获得具有结构化语义的 MetaInsight。
在 MetaInsight 中,研究员们还针对 Insight Scoring、Mining 以及 Ranking 等具体问题进行了研究,设计出了一套高效、可行的解决方案。

图4:QuickInsight 和 MetaInsight 的用户使用反馈
一系列的用户研究表明,MetaInsight 能够更好地帮助用户理解数据、启发更深层次的数据探索。
相关论文:
MetaInsight: Automatic Discovery of Structured Knowledge for Exploratory Data Analysis
论文链接:https://www.microsoft.com/en-us/research/uploads/prod/2021/03/metainsight-extended.pdf
XInsight:利用因果知识扩展数据洞察的外延
在数据分析场景中,可解释性是固有的一个需求。人们对各种数据中的现象进行观察,总结出适用概念,提出假设性的机制来解释观测,再提供预测,等等。这些分析过程中可解释性是普遍存在的。
一个典型的场景是对异常数据进行解释。对异常的解释不仅在 MetaInsight 的使用中较为常见,而且更广泛地存在于日常数据分析的场景中。例如在销量数据中,用户希望探知某一年销量下降的原因;在游客数据中,用户希望解析出不同地域之间游客的差异。这种对解释的需求促使研究员们在传统探索式数据分析的基础上,提出了新的数据分析范式——可解释数据分析(Explainable Data Analysis, XDA)。
处理可解释数据分析的第一个要素是需要利用变量之间的因果关系。现有的工具往往基于相关性来生成数据的解释,但相关性并不意味着因果关系。基于相关性的数据解释往往会让用户产生因果的幻觉(illusion of causality),进而导致错误的数据理解和决策。
解释可以被分为因果(causal explanation)和非因果(non-causal explanation)两类。因果解释通过寻找因果因素来解释结果。例如图5,在一个模拟的肺癌数据集中,患者的地理位置(反映地区控烟政策)和压力程度会影响他们是否吸烟,吸烟会进一步影响肺癌的严重程度,而肺癌严重程度又会进一步影响患者是否接受手术和五年存活率。
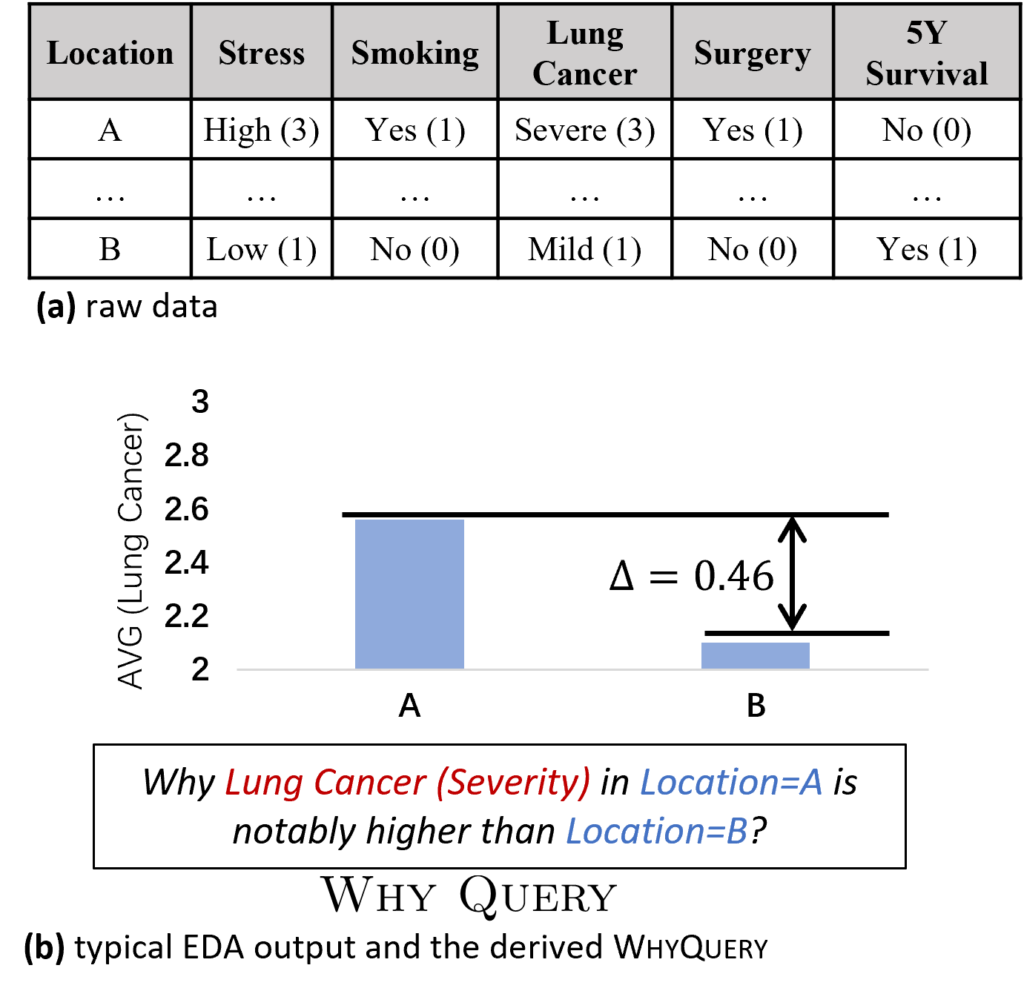
图5:肺癌数据集、不同地区的肺癌差异以及对应产生的 Why Query
吸烟为患者为什么患有不同严重程度的肺癌提供了解释。这是一个因果解释。相比之下,非因果的解释仅通过统计相关性来解释结果。例如,在肺癌数据集中,手术对肺癌严重程度有影响。但这并不是因果关系解释。因果关系解释还能让用户进行反事实思考(counterfactual thinking)和可行决策(actionable decision)。例如,戒烟可以降低肺癌的严重程度,而取消手术并不能改变肺癌的严重程度。这意味着,因果关系解释可以帮助用户制定更具针对性的决策,从而更好地解决实际问题。
基于这些发现,研究员们提出了 XInsight,旨在提供更可解释的数据洞察,减少因果关系的幻觉所带来的误解。XInsight 首先利用因果发现(causal discovery)定性地寻找数据内部变量之间的因果关系。基于定性的因果关系,XInsight 提出了 XTranslator,将因果图(causal graph)上的因果语义转化为可解释数据分析(eXplainable Data Analysis,XDA)的语义。根据 XDA 层面的语义信息,XInsight 再进一步利用实际因果性(actual causality)框架定量地分析每个变量内部不同取值对数据差异的影响,最终获得解释。
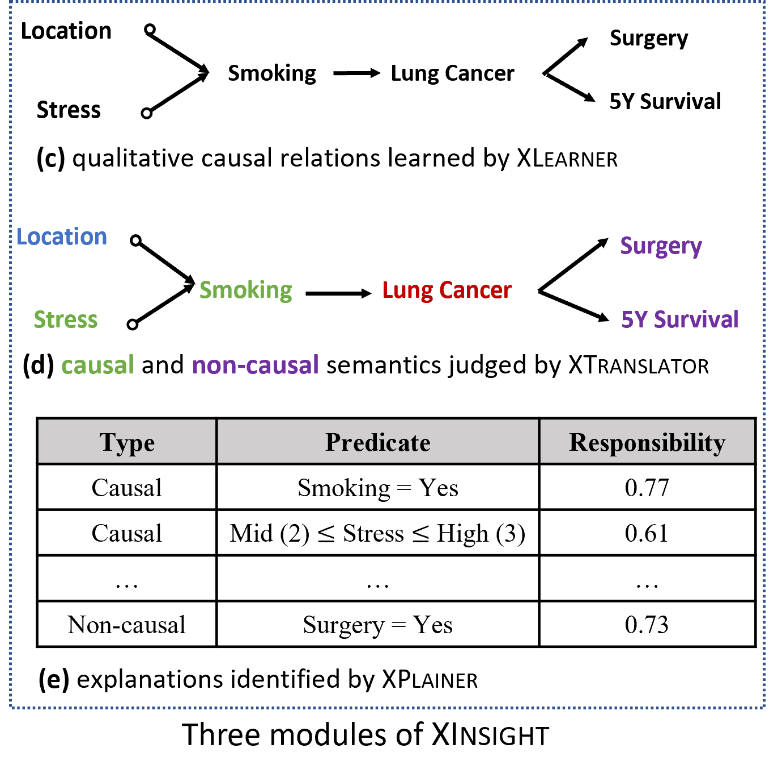
图6:XInsight 的模型框架
举一个使用 XInsight 进行数据洞察的例子,如图7所示。在前面展示的肺癌数据集中,分析师观察到一个有趣的现象:“区域 A 的患者肺癌的平均严重程度比区域 B 高得多”,然后提出可能出现此现象的归因。通过 XInsight 可以得出一个因果关系的解释,即“吸烟”是肺癌严重程度的定性因素,并且强调“吸烟=是”(Smoking=Yes)及其作为定量解释的责任(responsibility)。用户能够据此更深入地理解不同区域患者肺癌严重程度之间的差异,并针对吸烟这一因素提出相应的干预措施,如制定更严格的烟草控制政策、推广禁烟宣传等,以达到更好的防控效果。
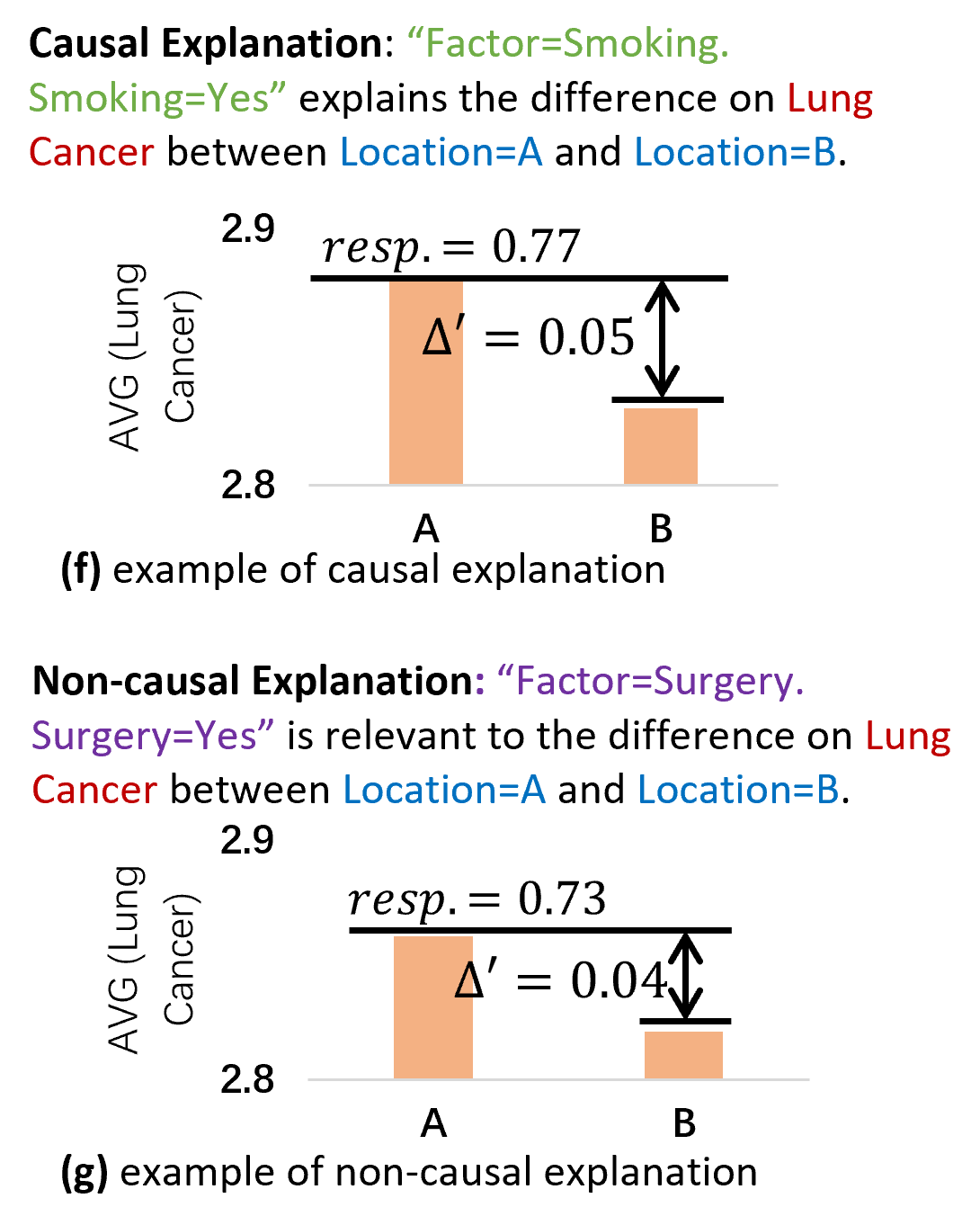
图7:因果解释和非因果解释
尽管 XInsight 功能强大,但想要发挥出每个模块的理想功能,仍具有相当大的挑战。首先,大多数现实世界的数据集是在不考虑因果充分性(causal sufficiency)的前提下收集的,即我们观察到的变量集合包含了所有的重要因果关系,没有遗漏任何关键的潜在变量。此外,在现实世界中,数据集中往往有一些数据与其他数据相关,比如学生的成绩由学习情况决定。这种数据间的关系称为函数依赖(Functional Dependency,FD),尤其是当它们从关系数据库中实例化时,函数依赖关系更为常见。但是这些 FD 有可能会让分析师误以为数据之间存在因果关系,但实际并没有。这就违反了忠实性假设(faithfulness assumption),这对于许多想要从数据间发现因果关系的算法是一个关隘。简单而言,忠实性假设是指在因果结构学习中,所有的统计依赖性都与某个因果关系相对应。为了应对这些挑战,研究员们建立了 FD-induced Graph 理论。XLearner 会使用 FD-induced Graph 从数据中选择一组不会违反忠实性假设的变量,并采用 FCI (fast causal inference)算法来处理因果不充分(causal insufficiency)的数据,然后将 FCI 的结果与 FD-induced Graph 中的因果关系相结合,进而获得最终的因果图。
其次,从因果原语(causal primitive,即因果图中的结构关系)到 XDA 语义(例如,变量是否提供因果解释)的转换尚未得到充分研究。因此目前尚不清楚如何确定变量 X 是否可以在给定上下文的情况下解释目标,以及 X 是否可以提供因果或非因果解释。XTranslator 从因果图中的各种因果原语(例如,m-separation,祖先/后代关系)出发,提供了一种系统性地将它们翻译成 XDA 语义的方法。
最后,在获取量化解释时,同样存在挑战。现有的数据库因果关系(DB Causality)主要用于数据溯源,通常以元组(tuple)作为解释。相比于元组,谓词级解释(predicate-level explanation)更加简洁易懂,所以在 XDA 的场景中可能更为理想,由此也需要对原有的数据库因果关系理论进行适配。此外,数据库因果关系理论中,对一个潜在解释的定量分析具有相当高的计算复杂度(NP-Complete),由此也需要一个快速且有理论保证的近似算法来加速计算。XPlainer 针对数据分析中不同的聚合函数(aggregate function)设计了针对性的近似优化算法,既满足了数据分析的实时性要求,也提供了理论保证。
在实验中,研究员们在多个公共数据集、私有数据集和合成数据集(synthetic dataset)上都验证了 XInsight 的有效性。例如在航班延误数据集中,如图8所示,XInsight 发现了雨季(Rain=Yes)是不同月份航班平均延误时间差异的原因。
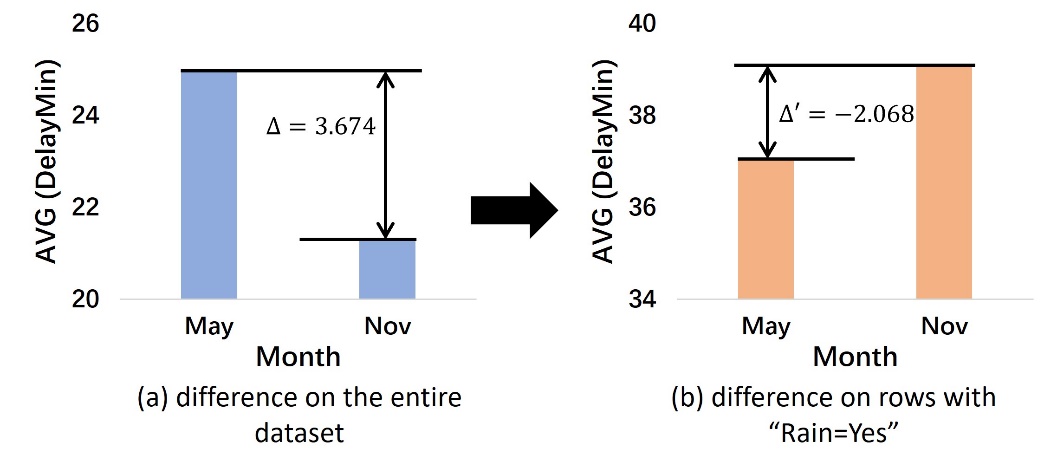
图8:XInsight 检测出雨季可以对航班延误进行解释
相关论文:
XInsight: eXplainable Data Analysis Through The Lens of Causality
论文链接:https://arxiv.org/abs/2207.12718
从意图出发:LLM导航的数据探索
MetaInsight 和 XInsight 所展现出的自动化数据探索工具的巨大潜力,都是基于某个特定的数据洞察,从而触发了数据分析意图(data analysis intent),它们的输出是数据分析意图在数据中的一种体现。但是,从另一个角度来看,这表示现有的解决方案的智能程度仍存在不足,MetaInsight 和 XInsight 还需要依赖人类数据分析师来找到特定的触发条件,并且在多数情况下,单一的数据洞察往往不能满足用户的真实需求。
以一位教育分析师 Alice 为例。她正在通过探索式数据分析,试图了解学生数学成绩的总体趋势。Alice 花费了数十分钟手动筛选和排序数据,并绘制了数学成绩随时间的变化图,发现数学成绩整体上升。接下来,她希望比较不同学校学生的表现,所以她又花费了更多的时间手动筛选数据,对比了 A、B、C 三所学校的学生数学成绩。她发现 A、B 两校的数学成绩呈现上升趋势,而 C 校在2020年出现了一个异常值。Alice 好奇地决定深入研究这个异常值。她花费了大量时间来回探索数据,通过各种变量进行筛选和分组,最终发现当排除 “Take-home” 考试时,C 校2020年的异常值便不再存在。于是,她记录下这一发现,并得出结论:这个异常值是由于 C 校在2020年改变考试形式所导致的。

图9:数据探索示例
正如上面的例子所展现的,数据探索远比提供一个特定的数据洞察要复杂,它既依赖于数据分析师的专业能力,同时也需要对特定数据集中的用户意图和领域知识有所掌握。为了解决这些问题,研究员们提出了一种更为智能的数据洞察工具 InsightPilot。InsightPilot 能够通过自动化的方式,帮助用户更高效地从数据中挖掘有价值的信息,减轻数据分析师的工作负担。相较于 MetaInsight 和 XInsight 等,InsightPilot 不仅可以自动执行数据分析任务,更能主动地从数据中寻找有价值的洞察,并为用户提供更全面、精准的数据分析结果。前面的示例中,Alice 需要花费大量时间对数据进行手动筛选、排序和分组。然而,借助 InsightPilot,这些繁琐的任务将被大大简化,节省了分析师的时间,让他们可以专注于深层次的数据洞察。
为了实现更为自动化的数据探索,InsightPilot 将数据探索的过程抽象为由 context-intent-analysis 组成的序列,即利用大语言模型(LLM)理解已有的数据洞察(context)、提出一个合理的数据分析意图(intent),并由 Insight Engine 将意图转化为具体的数据分析(analysis)。通过利用数据分析的结果对数据洞察进行更新,让 LLM 推荐新的数据分析意图,从而迭代形成若干个由 context-intent-analysis 三元组完成的序列,从而使 InsightPilot 完成整个数据探索的过程。
图10演示了如何将 InsightPilot 应用于 Alice 的场景。首先,用户通过用户界面用自然语言提出一个问题:“请展示学生数学成绩中值得挖掘的趋势。”然后,Insight Engine 会根据用户的问题从数据中生成初始洞察,并以自然语言的形式呈现给 LLM。例如,一个根据用户问题生成的洞察可能是:“学校 A 的平均成绩排名第一。”针对用户的问题,LLM 从初始洞察中选择与用户问题最相关的洞察,因此选择了“学生的数学成绩随着时间的推移呈上升趋势。”

图10:如何利用 InsightPilot 实现图9中的数据探索过程
接下来,当 LLM 选择了一个相关洞察后,Insight Engine 会对这个洞察进行分析,并向 LLM 提供可行的分析意图选项。在这个示例中,LLM 在“理解”和“归纳”两种意图中最终选择了“归纳”。然后,在收到选定的分析意图后,Insight Engine 将执行相应的查询语句并用一组新的洞察来回应分析意图。为了总结所选的洞察,Insight Engine 会尝试按照不同学校和考试形式来总结数学成绩的趋势。它发现:“除了学校 C,大多数学校的学生数学成绩随着时间的推移呈上升趋势。学校 C 在2020年出现了一个异常值。”为了进一步探索数据,LLM 将再次选择洞察和分析意图与Insight Engine交互。此时,LLM要求 Insight Engine “解释学校 C 在2020年的异常值。”
这种基于洞察和意图的交互将持续进行,直到 LLM 对探索结果满意或达到最大 token 数限制。在数据探索结束后,Insight Engine 将输出已探索洞察,由 LLM 将它们总结成一个有意义且连贯的报告呈现给用户。
相比于使用 LLM 直接理解数据,InsightPilot 借助了 MetaInsight、XInsight 等解决方案来完成数据分析任务,为 LLM 提供结果,保障了数据探索的可靠性。
相关论文:
Demonstration of InsightPilot: An LLM-Empowered Automated Data Exploration System
论文链接:https://arxiv.org/abs/2304.00477
数据分析是一个以人为本的应用领域。希望通过上述的案例分析可以从研究的视角启发大家。从认识论角度来讲,人类探索世界的边界在不断扩大,理解世界的内涵也在丰富,这个道理同样适用于数据分析。而从效用角度来讲,数据分析的目标是完成实际生产生活中各种由数据驱动的任务,这些任务是多环节多角度构成的,但目前的数据分析工具,往往是散落在某个环节,从某个角度来解决一个局部问题,是辅助性的。因此,数据分析的舞台是足够大的,相信未来会有更多相关的科研成果诞生,进一步探索数据分析的智能化!






