
打破拓扑结构的天花板,深入探究属性图上表示学习的研究蓝海
2023-03-21 | 作者:社会计算组
图是一种通用的数据表示形式,来自不同领域的数据均可以表示为图,例如文本数据可以看成是一维图,图像可以看成是二维图,分子和蛋白质等实体也可以天然地的用图表示。通俗而言:万物皆可图。
而图表示学习(Graph Representation Learning,GRL)能够将图中的节点或者整个图转化为低维可计算的向量,为机器学习模型处理图这种高维复杂的数据形式提供了合适的计算接口。根据粗略统计,近年来,每一年各大顶会上收录的图神经网络(Graph Neural Networks,GNNs)论文数目增长迅速,相关研究与应用也蓬勃发展。
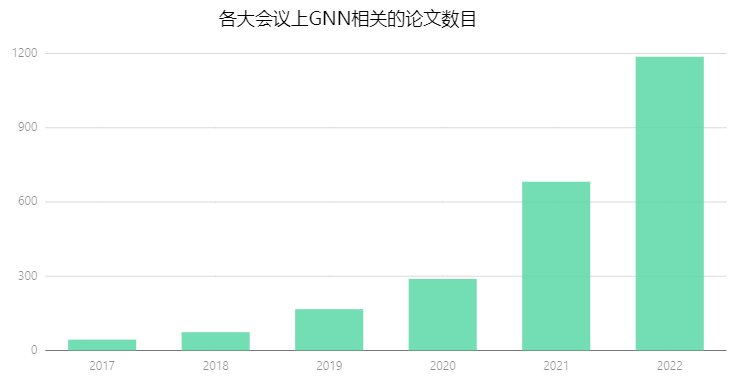
图1:近年来各大会议上 GNN 相关的论文数目
但是,与自然语言处理(NLP)领域的语言模型 LM 和计算机视觉(CV)领域的 ViT (Vision Transformer)相比,GNN 在实际应用中的影响仍相对较弱。对此,微软亚洲研究员社会计算组的研究员们深入探究了目前 GNN 的机制和原理,从根源上分析拓扑结构形成的原因,提出针对节点属性的理解建模有可能比拓扑结构建模更加重要,进而形成了一系列(文本)属性图上的表示学习的工作。
在今天的文章中,研究员们将从新的视角定义和利用拓扑结构,揭示语言模型与拓扑结构之间的关联。
基于拓扑结构建模的图神经网络
目前常见的 GNN 模型一般着眼于挖掘拓扑结构中独特的知识。GNN 模型通常会先将节点表示为一个特征向量,然后设计复杂而精细的聚合函数来捕捉中心节点周围的拓扑结构信息。以知识图谱这个常见的图数据为例,微软亚洲研究院发表在 ICML 2022的 《HousE: Knowledge Graph Embedding with Householder Parameterization》 工作中提出了基于拓扑结构、具有强大综合建模能力的知识图谱表示学习(Knowledge Graph Embedding, KGE)模型[1]。
KGE 模型旨在学习知识图谱中实体和关系的表示。这些模型的性能好坏很大程度取决于对 KG 中关系模式(relation pattern)和关系映射属性(relation mapping property)建模的能力。知识图谱中重要的关系模式有:(1)对称,如 is_friend_of 就是一种对称关系;(2)非对称,如 is_father_of 就是一种非对称关系;(3)逆,如 is_teacher_of 和 is_student_of 就是一对互逆的关系;(4)组合,如 is_grandmother_of 就是 is_father_of 和 is_mother_of 的组合关系。关系的映射属性则有一对一关系、一对多关系、多对一关系和多对多关系。
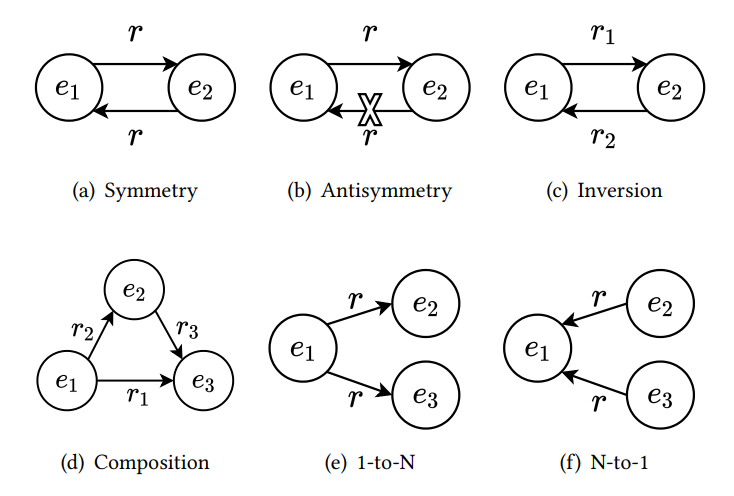
图2:四种重要关系模式和两种复杂的关系映射属性
表1总结了现在有代表性的 KGE 方法的建模能力,其中还包含对这些方法局限性的分析:(1)虽然将关系视为实体间的旋转变换是对多种关系模式建模的有效方法,然而关系的旋转无法突破低维空间(2、3、4维)很大程度地限制了模型的建模能力;(2)还未出现能完美演绎知识图谱中的重要关系模式与复杂映射属性的“六边形战士”模型。
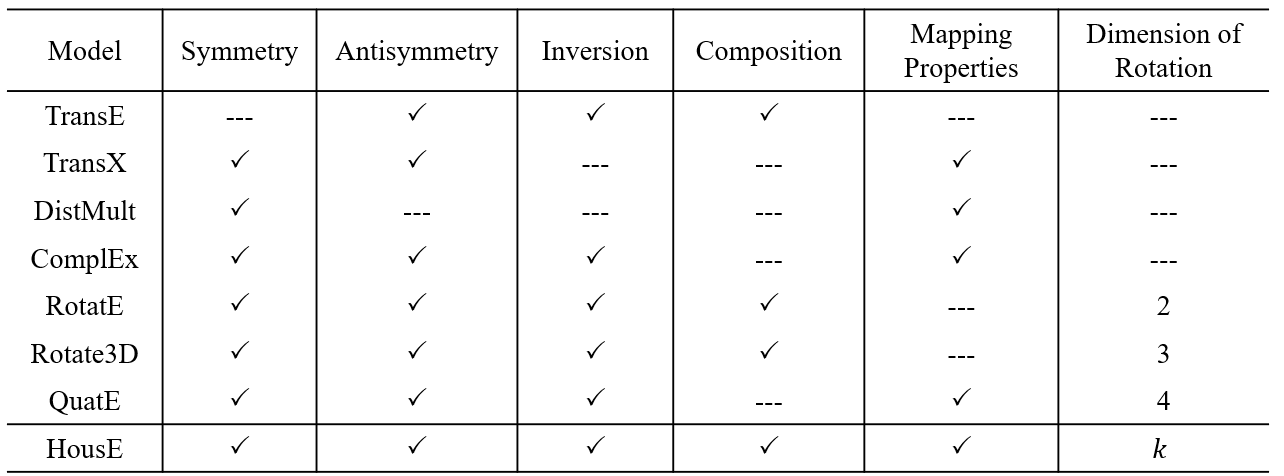
表1:现有典型的 KGE 模型对重要关系模式和复杂映射属性的建模能力
现有方法的局限性促使研究员们思考:如何设计一个具有建模能力更全面的 KGE 模型?为此,本研究引入了 Householder 反射变换作为基本数学工具,并基于此设计了两种线性变换作为知识图谱中的关系表示。在 Householder 框架下,研究员们提出了 HousE。HousE 是现有基于旋转的 KGE 模型的升级版。如表2中所示,HousE 能够自然地将旋转扩展到任意 k 维,并且其建模能力能够覆盖表1中的所有关系模式与映射属性。在多个公开知识图谱基准数据集进行验证的实验表明,HousE 明显优于现有的基准模型。
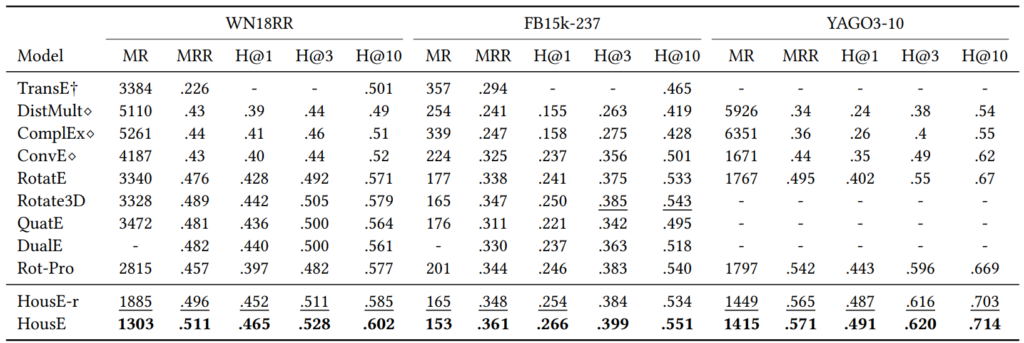
表2:不同 KGE 模型在标准数据集上的效果
基于拓扑结构的建模真的没问题么?
随着图神经网络的快速发展,GNN 被普遍应用于 NLP、推荐系统、自然科学等领域。例如,在推荐系统中,每个用户和商品都可以看成是图中的两类节点,两者之间的历史交互行为(例如点击、购买等)构成了图上的边。基于图的推荐系统有助于捕捉高阶的协同过滤信号(Collaborative Filtering, CF),因此可以更好的刻画用户的兴趣偏好。
考虑到“万物皆可图”的普适性,难道基于图拓扑结构的建模真的无懈可击么?
其实不然。基于拓扑结构的建模面临着以下几个问题:
(1)不可知性。图拓扑结构的复杂性使得人很难对其进行深入且准确的认知。判断两个序列是否相似,例如两段文本是否相关,并不难。但是判断两个图是否相似或者同构(例如Graph Matching),则是 NP-hard 问题。例如,图3中的两张图看起来区别很大,但实际上是等价的。如果准确理解判断图拓扑结构对人来说都算难题,那么很难期待机器学习模型能够在这种不可知的数据上达到更好的效果。

图3:图匹配问题的一个例子[2]
(2)低计算效率和高资源消耗。图神经网络的一大特征是可以利用高阶的远距离邻居来提供丰富的上下文信息。但同时,这种远距离的依赖带来了“邻居爆炸”(neighborhood explosion)的挑战。假设节点的平均度数为 k,那么 l 跳之内的节点数目为 N=k^1+k^2+…+k^l。GNN 的聚合过程需要 N 个节点的信息来学习单个节点的表示,一方面这需要更大的内存来存储这种指数规模的邻居节点,另一方面也会极大影响模型的训练速度。
(3)拓扑结构的可靠性。例如在社交网络中,由于用户行为的随机性和不确定性,某个社交用户可能错误地关注或点击了一些不相关的其他用户,带来了拓扑结构中的噪声。这类噪声会随着逐条的信息聚合而逐渐增强,使得学习到的用户表示不够准确。
根据以上分析,基于拓扑结构的建模可能并不是最优解,而且 GNN 在如短序列推荐(Session-based recommendation,SBR)等场景中也并不一定有效。例如,短序列推荐(SBR)是针对用户在短期、动态的会话(即用户一段时间内的活动序列)中的行为进行推荐。与传统的基于用户或物品的推荐系统不同,SBR 更注重当前会话中用户的实时需求,从而更好地应对用户兴趣的快速变化和长尾商品的推荐问题。最近的 SBR 研究(SR-GNN[4],SGNN-HN[5]和DHCN[6]等)也出现了大量使用基于 GNN 的模型。但与模型复杂度的指数级增长相比,这些模型在基准测试中带来的性能提升却微乎其微。鉴于这种现象,研究员们的疑问是:基于 GNN 的模型对于 SBR 来说,是过于简单,还是过于复杂了?
为了回答这个问题,研究员们尝试剖析现有的基于 GNN 的 SBR 模型,并分析它们在 SBR 任务上的作用。如图4所示,典型的基于 GNN 的 SBR 模型可以分解为两个部分:GNN 模块和 Readout 模块。分别在这两个部分上应用 Sparse Variational Dropout(SparseVD)在训练模型时计算参数的密度比(density ratio)。

图4:基于 GNN 的 SBR 模型的建模范式
可以从图5左图中 GNN 模块的密度比看出,随着训练趋于稳定,该密度比趋于0。而右图所表示的 Readout 模块显示随着训练的进行,注意力池化权重的密度比可以保持在一个较高水平。在其他数据集和其他 GNN-based SBR 模型上,也出现了相同的趋势。因此得出结论:GNN 模块的参数很有可能是冗余的。
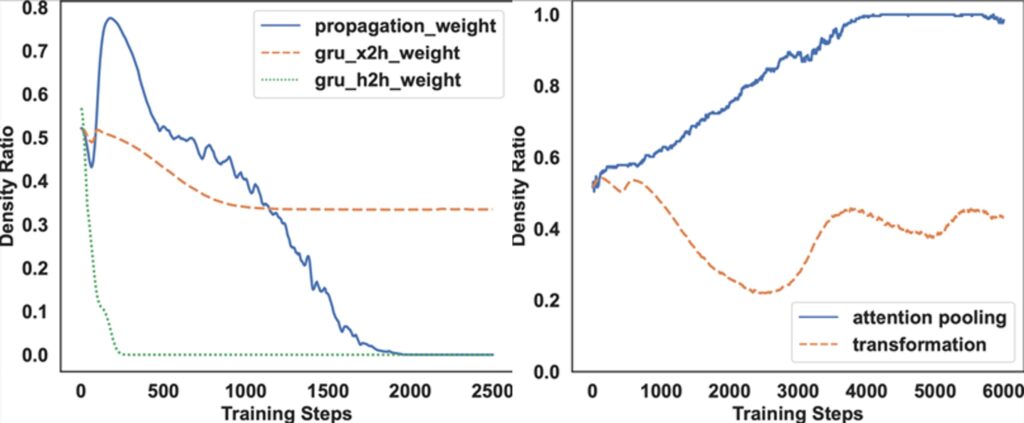
图5:SBR 模型中不同模块的参数重要度分析
基于上述发现,研究员们提出了以下用于 SBR 的更简单但更有效的模型设计准则:
(1)不强调复杂的 GNN 设计,更倾向于删除 GNN 传播部分,仅保留初始嵌入层;
(2)SBR 模型应该更加关注基于注意力的 Readout 模块。由于注意力池化权重参数保留了较高密度比,研究员们推测,在基于注意力的 Readout 方法上进行先进的架构设计将会更有效。由于放弃了对 GNN 传播部分的要求,Readout 模块应该承担更多模型推理上的责任。考虑到现有基于实例视图(instance-view)的 Readout 模块的推理能力不足,所以需要设计具有更强大推理能力的 Readout 模块。
因此,研究员们提出了一个名为 Atten-Mixer 的模型,相关论文发表于 WSDM 2023,并获得了 Best Paper Runner-up 奖项[3]。如表4的实验结果所示,即使移除了 GNN 模块,Atten-Mixer 在多个常用的数据集上的实验结果仍优于复杂的基于 GNN 的模型。
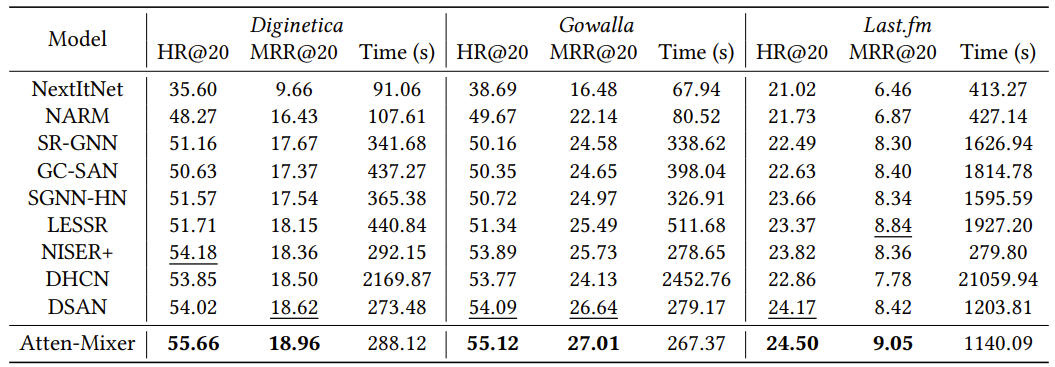
表4:不同的 SBR 模型在常见数据集上的效果
节点属性建模可能更加重要
节点和边是构成图的关键元素。其中节点代表了其内在的天然属性,边刻画了图的拓扑结构。目前常用的 GNN 更多关注于对拓扑结构的建模,忽视了对节点属性的理解。例如,GCN/ GAT/ GraphSAGE 等通用的 GNN 模型通常会将节点利用先验知识或者预先训练好的编码器转变为节点表示向量。这些初始的节点表示向量在后续的 GNN 聚合过程被视为静态不可学习的参数,这种学习范式中的节点属性建模和拓扑结构建模是相互独立的,并不能进行端到端的图表示学习。另外,节点属性建模一般是基于先验知识或者预先得到的编码器,无法保证其得到的节点特征能够和下游的图挖掘任务保持一致,因此微软亚洲研究院的研究员们从节点属性建模出发,开辟了新途径。
不同于以往的二步式学习范式,研究员们尝试对节点属性和拓扑结构进行协同训练(co-training)。从图衍变的角度来看,节点属性有可能比拓扑结构更加重要。拓扑结构中的每一条边都有其存在的原因,而节点之间的关联关系是边形成的根本原因和内在动力。例如在图6中,左图表示了一个已经存在的社交网络和一个新用户 Alex,每个用户都有社交属性和偏好,Alex 在加入社交网络之后,大概率会关注和自己属性类似或者兴趣爱好相同的其他用户(例如同事或者同学)等,进而形成了社交网络上的拓扑结构。

图6:社交网络中关注关系形成的一个示例
大家可以简单理解为:拓扑结构可能会受到其他外界因素(例如用户行为和偏好)等的影响有所偏差,但是始终受节点属性的影响和制约。拓扑结构和节点属性之间的关系有些类似于“先有鸡还是先有蛋”的困境(The Chicken-and-egg Conundrum)。从另外一个角度来看,如果没有拓扑结构的话,节点以及其自身的属性信息其实还是会存在,例如社交网络中某个用户没有关注任何人,他依然是社交网络中的一个实体。但是,如果没有了节点,拓扑结构就会消失,正所谓“皮之不存毛将焉附”。因此,研究员们认为节点属性建模更加重要。
那么问题又来了:如果节点属性建模是拓扑结构建模的基础的话,那么拓扑结构是不是就没用了呢?
这个答案是否定的。
首先,由于节点属性经常会不完整或者遗失,所以拓扑结构可以从节点之间的关系上对其进行补充。其次,拓扑结构是从用户行为等其他层次刻画节点之间的关联关系,这种关联关系会有自己独特的知识,并不一定和节点属性相似性完全一致,因此不如“全都要” ,同时对节点属性和拓扑结构联合建模。
如何做到节点和边的联合表示学习?研究员们着眼于文本属性图(Text Attributed Graph, TAG)上的表示学习,以融合中心与邻域文本特征的图节点向量表示为破局之法。为了同时训练节点内的文本和节点间的拓扑结构,一个直接的方式是利用预训练语言模型(LM)对文本进行建模,然后利用 GNN 对 LM 学习得到的节点表示进行基于拓扑结构的融合。
如图7左图所示,针对中心节点 c 以及其邻居节点 N1 和 N2,分别利用多层 Transformer 架构对其包含的文本信息进行建模,然后利用 GNN 聚合生成的表示向量作为最终中心节点的表示。下游的图分析任务(例如节点分类)的优化目标得到的梯度会反传回来同时更新 LM 和 GNN,形成一个端到端的表示框架。相关工作已入选 SIGIR 2021[7]、EMNLP 2021[8] 等会议。同时,该系列工作也在赋能微软必应(Bing)搜索、必应(Bing)广告、Shopping feeds 等微软产品为其提质增效。
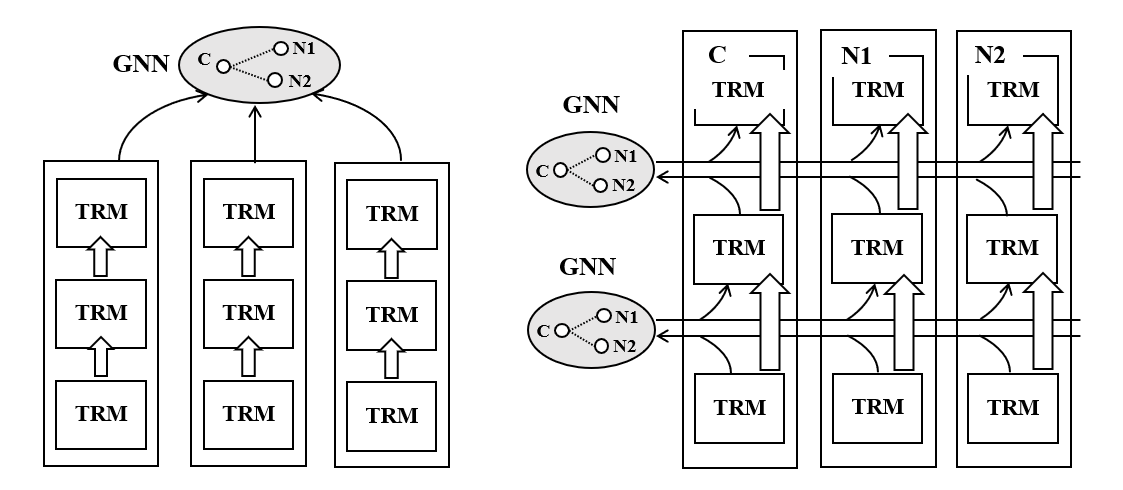
图7:松耦合和紧耦合的 LM-GNN Co-training 范式
虽然模型能够实现联合建模,但拓扑结构和文本属性仅仅是通过级联方式进行了松耦合。对此,研究员们进而提出了紧耦合的 LM-GNN 共同训练范式(LM-GNN Co-training模型)。如图7右图所示,紧耦合范式采取了层级化的 LM-GNN 整合方式:在每一层中,每个节点先由各自的 Transformer Block 进行独立的语义编码,编码结果汇总为该层的特征向量(默认由 CLS 所关联的 hidden state 来表征);各节点的特征向量汇集到该层的 GNN 模块进行信息整合;信息整合的结果被编码至对应各个节点的图增广(graph augmented)特征向量中,并分发至各个节点;各节点依照图增广特征向量进行下一层级的编码。
相较于此前的松耦合架构,紧耦合在 LM 编码阶段便充分参照了邻域信息,从而大大提升了各节点文本表示的质量。同时,考虑到节点间的信息交互是借由特征向量在极其轻量 GNN 模块中进行,每层整体的运算开销与单纯利用 Transformer Block 进行各节点独立的编码相差无几。相关的研究工作已在 NeurIPS 2021[9]、KDD 2022[10] 等会议发表。
虽然与之前的 GNN 模型相比,LM-GNN Co-training 模型能够在文本属性图上取得优越的效果,但是这种训练方法大大提高了训练的难度。如图7所示,联合训练需要同时对中心节点和 k 个邻居节点的文本信息进行建模,相当于 (1+k) 次 LM 的前向计算和梯度的后向传递。考虑到预训练语言模型的参数量,这种计算复杂度和资源消耗难以承受。一种简单的方式是减少邻居节点的数目 k,但是会带来拓扑结构信息的丢失。因此,如何在保证效率的前提下进行 LM-GNN 的有效共同训练,是一个亟需解决的问题。
因此,研究员们提出了一个交替训练的框架[11]。如图8所示,在 LM 训练阶段,GNN 学习到的拓扑结构知识能够有效地转移到 LM 中,使其能够了解拓扑结构和下游任务的相关信息。而在 GNN 训练阶段,上一次训练得到的融合拓扑结构信息的 LM 能够为 GNN 提供更高质量的初始节点特征,有助提升其性能。上述两个阶段相互增强,进而可以得到高质量的节点表示向量。上述学习范式的时间复杂度约等于单个 GNN 和单个 LM 的训练复杂度之和,所以能够有效处理大规模节点属性图上的表示学习。该研究入选了 ICLR 2023(Notable-top-5%),并且在 OGBN leaderboard[12] 上登顶多个数据集的首位。
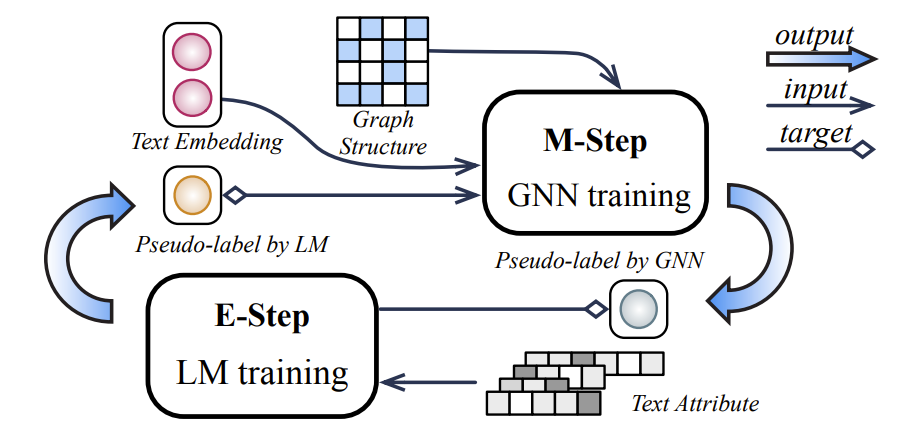
图8:交替学习的 LM-GNN 训练范式
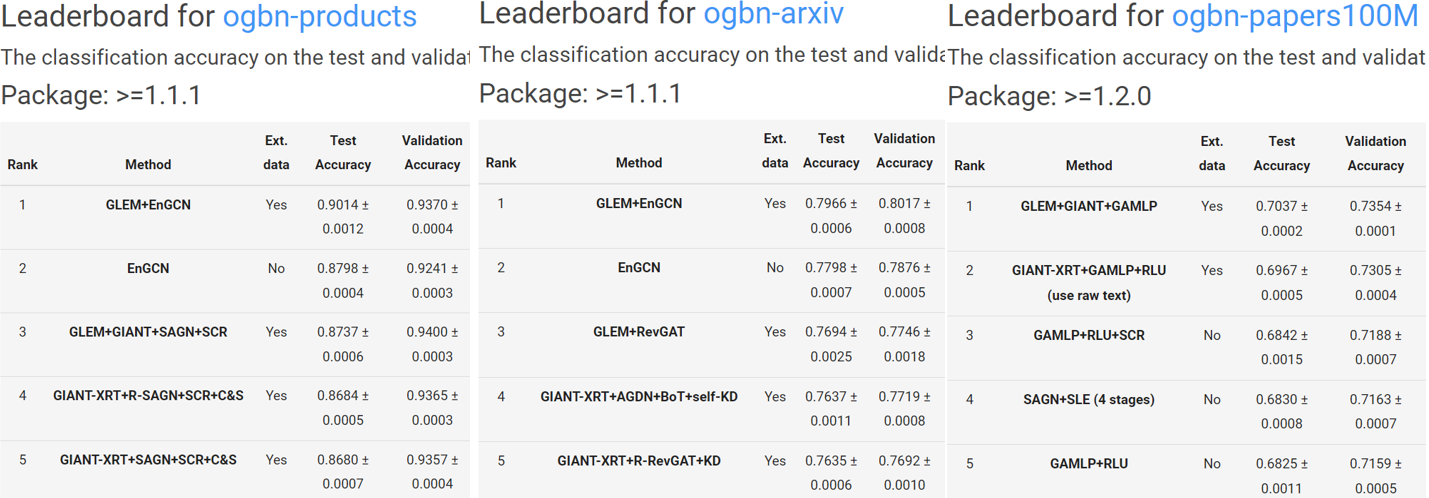
图9:GLEM 在 OGBN leaderboard 上取得了多个数据集的第一名
大规模语言模型也许是图表示学习的未来
基于上述的一系列研究工作,微软亚洲研究院的研究员们证明了节点属性建模有可能比拓扑结构建模更重要。随着最近 ChatGPT 所带来的强大认知能力的涌现,一个问题也随之而来:大规模语言模型(LLM)能否成为处理图数据的基础模型?研究员们也对这个问题进行了初步的探究和展望。
这里举一个简单的例子。TUDataset 是图分类任务中经常使用的数据集,其中一个任务是给定一个化合物,根据结构组成判断其是芳香族还是杂芳族。不同于主流 GNN 的做法,如图10所示,研究员们利用 ChatGPT 作为基准模型,将化合物转化成 ChatGPT 能够理解的语言,然后询问该输入的图是否属于芳香族。令人惊讶的是,ChatGPT 给出了正确的判断结果和原因解释。

图10:ChatGPT 能够正确处理化合物图的一个例子
从表面来看,图和语言是不同的两种表示形态,它们两者之间也许会有难以逾越的鸿沟。但是,如果从人类的认知来看,当面对这种化学分类问题的时候,人类也是将其转化成隐式的语义信号,然后与自己学习到的知识进行对比,进而最终得到判断结果。因此,语言模型对图的处理可能更加符合人类的认知习惯。
现有的 GNN 模型在处理图分析任务的时候,一般会根据它的性质,比如碳原子的电子极性属性等,把节点转化成固定的表示向量,然后再根据 GNN 的聚合函数学习到图的表示。GNN 的训练信号来源于少量的标注数据集。但是,目前这种通用的实验设置天然具有两大缺陷:(1)节点属性的大量缺失。例如,碳原子可能除了电子极性之外还有别的特性,如质子数目和电子数目等。如果利用简单的经验知识仅仅将其部分属性转化为节点表示向量,那么就会忽略掉大部分的节点属性信息。(2)就像 Kate Bowler 说过的,Everything happens for a reason。图的构建和表现出来的化学性质都是有原因的,这种原因可能已经在化学课本或者资料上被准确定义了。而目前这种实验设置抛弃了准确定义的先验知识,完全依赖于少量的标注数据中的微弱信号进行推理,等价于自我抛弃了豪华的机甲套装而强行拿着长矛盾牌进行出战。
那么,为什么大规模语言模型有助于解决上述问题呢?其原因在于处理方式更加符合人类认知,毕竟返璞归真可能会更加贴近事物的本质。(1)在 LLM 里输入图时,节点是被直接表示为其原始文本,比如“碳原子”和“氮原子”。如果 LLM 足够强大,那么它的知识里已经有能力记住碳原子在维基百科、化学教材里提到的特征,这样能够提供更全面更强大的节点属性;(2)在 LLM 预训练学习的过程中,它梳理了大量的化学书籍并熟悉了很多背景知识,因此它进行判断的依据不仅仅是依靠标注数据,而是人类已经总结好的宝贵知识。
LLM 和 GNN 的对比可以类似于:两个人同时参加化学考试,在做一个分类题的时候,GNN 是把其他几十个分子以及对应的标签给列出来,从0开始推断里面可能包含的知识;而 LLM 则是记忆了很多已有的知识,然后基于知识对当前的分子进行判断。某种程度上来说,LLM 是站在了巨人的肩膀上,并且也更加符合我们人类的认知和行为习惯。
因此,研究员们相信,LLM 有希望在图表示学习领域成为未来。但是,目前也存在这一些困难和挑战。最主要的挑战可能在于图结构的多样性,例如在社交网络中学习得到的知识可能很难应用于化学分子的判断中,所以能否有一个通用的 LLM 模型来处理不同类型的图上五花八门的分析任务,还值得科研人员深思。
[1] Li R, Zhao J, Li C, et al. House: Knowledge graph embedding with householder parameterization[C]//International Conference on Machine Learning. PMLR, 2022: 13209-13224.
[2] Savage N. Graph matching in theory and practice[J]. Communications of the ACM, 2016, 59(7): 12-14.
[3] Zhang P, Guo J, Li C, et al. Efficiently Leveraging Multi-level User Intent for Session-based Recommendation via Atten-Mixer Network[C]//Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining. 2023: 168-176.
[4] Wu S, Tang Y, Zhu Y, et al. Session-based recommendation with graph neural networks[C]//Proceedings of the AAAI conference on artificial intelligence. 2019, 33(01): 346-353.
[5] Pan Z, Cai F, Chen W, et al. Star graph neural networks for session-based recommendation[C]//Proceedings of the 29th ACM international conference on information & knowledge management. 2020: 1195-1204.
[6] Xia X, Yin H, Yu J, et al. Self-supervised hypergraph convolutional networks for session-based recommendation[C]//Proceedings of the AAAI conference on artificial intelligence. 2021, 35(5): 4503-4511.
[7] Li C, Pang B, Liu Y, et al. Adsgnn: Behavior-graph augmented relevance modeling in sponsored search[C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2021: 223-232.
[8] Bi S, Li C, Han X, et al. Leveraging Bidding Graphs for Advertiser-Aware Relevance Modeling in Sponsored Search[C]//Findings of the Association for Computational Linguistics: EMNLP 2021. 2021: 2215-2224.
[9] Yang J, Liu Z, Xiao S, et al. GraphFormers: GNN-nested transformers for representation learning on textual graph[J]. Advances in Neural Information Processing Systems, 2021, 34: 28798-28810.
[10] Pang B, Li C, Liu Y, et al. Improving Relevance Modeling via Heterogeneous Behavior Graph Learning in Bing Ads[C]//Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2022: 3713-3721.
[11] Zhao J, Qu M, Li C, et al. Learning on Large-scale Text-attributed Graphs via Variational Inference[J]. ICLR, 2023.
[12] https://ogb.stanford.edu/docs/leader_nodeprop/
[13] https://chrsmrrs.github.io/datasets/docs/datasets/






