
ICLR 2023 | 更适合研究员体质的机器学习鲁棒性论文合集
2023-04-25 | 作者:微软亚洲研究院
编者按:国际学习表征会议 ICLR(International Conference on Learning Representations),被公认为当前最具影响力的机器学习国际学术会议之一。在今年的 ICLR 2023 大会上,微软亚洲研究院发表了在机器学习鲁棒性、负责任的人工智能等领域的最新研究成果。继 ICLR 2023 杰出论文奖得主的独家分享后,本期将带来微软亚洲研究院在机器学习鲁棒性方面的四篇研究成果,其研究主题分别为领域泛化问题、分布外泛化、自适应阈值法与半监督学习中伪标签质量数量的权衡。
FreeMatch: 自适应阈值法

论文链接:https://arxiv.org/abs/2205.07246
代码链接:https://github.com/microsoft/Semi-supervised-learning
近年来,基于阈值的伪标签方法的半监督方法取得了巨大成功。然而,现有方法可能无法有效地利用未标记数据。这些使用预定义或者固定阈值,抑或专门的启发式阈值调整方案的方法将导致模型性能低下以及较慢的收敛。
对此,研究员们首先在理论层面分析了一个简单的二分类模型,得出了理想阈值和模型学习状态之间的关系。进而,研究员们提出了 FreeMatch,其能够根据模型的学习状态,以自适应的方式调整置信度阈值。研究员们还进一步引入了自适应类公平正则化惩罚,鼓励模型在早期训练阶段进行多样化预测。广泛的实验表明,FreeMatch 性能优越,尤其是当标记数据极其稀少时。该工作是 ICLR 2023 大会上半监督学习领域的最高分论文。
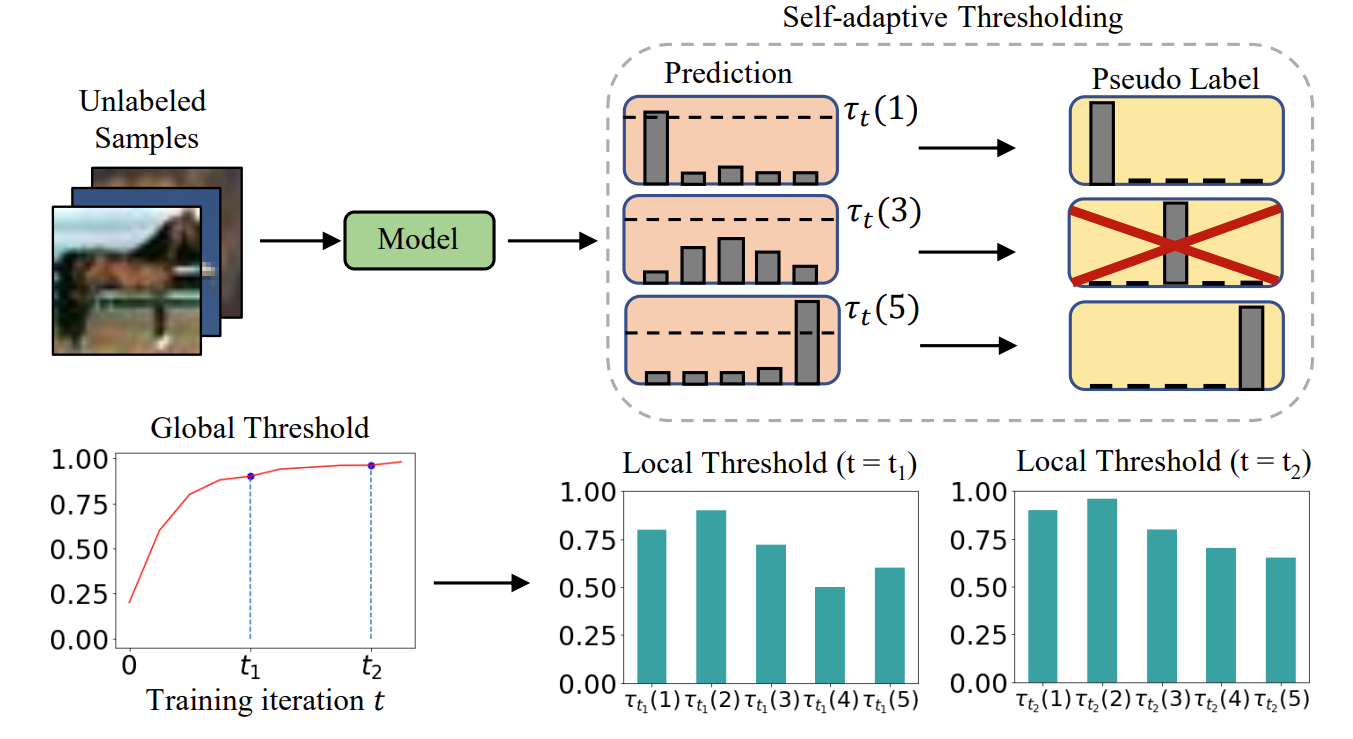
图1:自适应阈值法 FreeMatch 的 Global 和 Local threshold 调整示意图
SIMPLE:针对领域泛化问题的无需微调预训练模型匹配算法

论文链接:https://openreview.net/forum?id=BqrPeZ_e5P
项目主页:SIMPLE: Specialized Model-Sample Matching for Domain Generalization (seqml.github.io)
在人工智能领域中,领域泛化(domain generalization)问题一直备受关注。在领域泛化任务中,大多数现有方法是通过对特定的预训练模型微调(fine-tuning),并开发领域泛化算法来解决该问题。
微软亚洲研究院的研究员们详细研究了预训练模型和分布偏移之间的关系,发现对于领域泛化任务而言,并不存在单一最佳的预训练模型。根据广泛的实证和理论证据,研究员们论证了(1)预训练模型在某种程度上具有普适性,但是不存在能够覆盖所有分布偏移且表现均佳的最佳预训练模型;(2)在分布偏移中的泛化误差取决于预训练模型与未见测试分布之间的匹配度。
基于以上发现,研究员们提出了一种无需再微调的全新的领域泛化算法:SIMPLE。该方法基于模型-样本匹配策略,根据测试样本的特征,选择了合适的预训练模型来进行预测,显著提高了领域泛化的性能。在方法上,SIMPLE 首先将预训练模型的输出空间进行线性转换以适应目标领域。然后,通过具有模型专业性(specialty)感知的匹配网络为每个测试样本动态匹配合适的预训练模型进行预测。实验表明,SIMPLE 相较于现有方法取得了显著的性能提升,并且通过扩大预训练模型池,SIMPLE 的效果能进一步擢升。与需要微调预训练模型的传统领域泛化方法相比,SIMPLE的训练还达到了1000倍的提速。
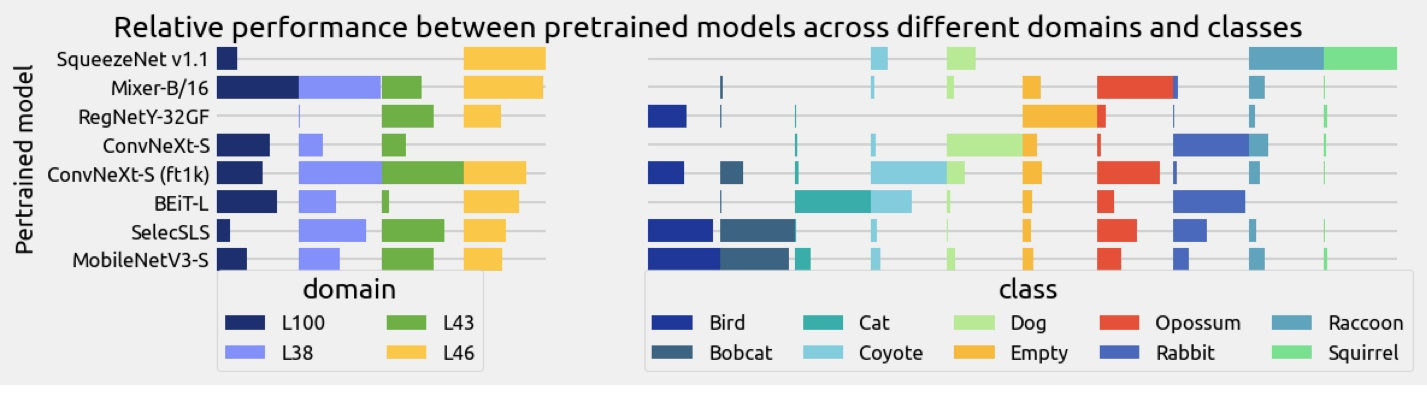
图2:在 TerraIncognita 数据集的不同领域和不同类别中,预训练模型的分类性能比较
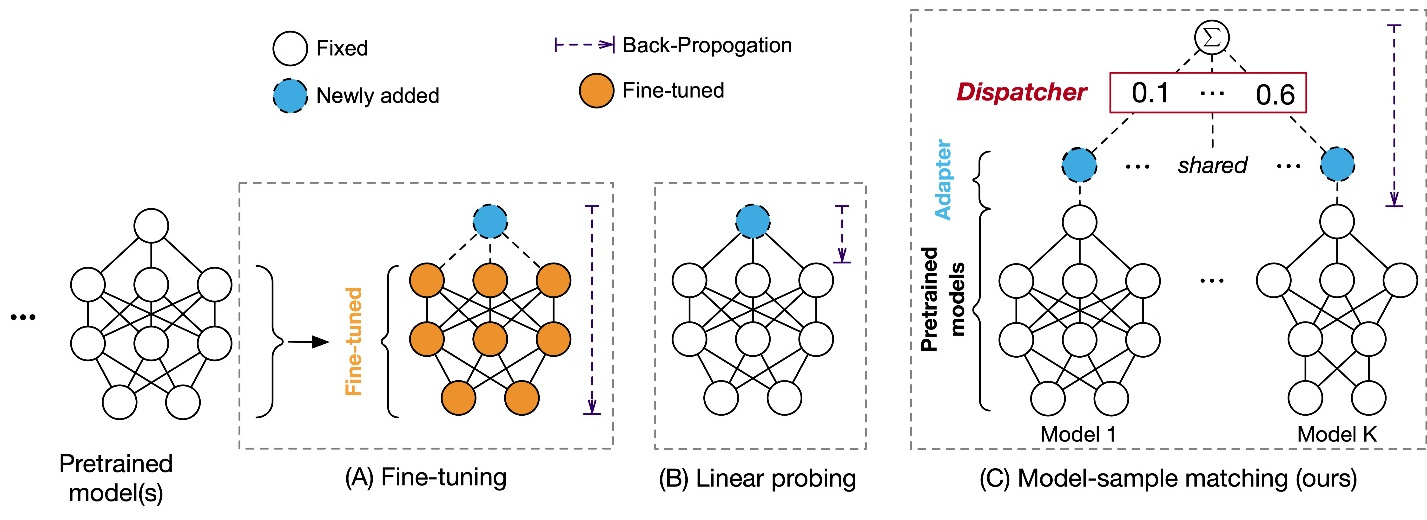
图3:解决领域泛化问题的不同训练范式
DIVERSIFY: 针对动态数据分布的OOD表征学习新范式

论文链接:https://arxiv.org/abs/2209.07027
代码链接:https://github.com/microsoft/robustlearn
分布外泛化(Out-of-distribution generalization)是机器学习中的一个重要问题。有别于传统假设认为数据分布是给定的一个静态分布,真实生活中的数据是动态变化的。例如,人的面部、地区的卫星图、人的声音等,均会随时间动态变化。目前已有的针对静态分布进行 OOD 泛化的研究还无法处理动态分布的情形。因此,本文尝试以时间序列为例,从分布的角度来看待此问题。因为分布动态变化的数据集的复杂性可能归因于存在未知的潜在分布。
为此,研究员们提出了 DIVERSIFY, 用于动态分布的泛化表示学习。通过挖掘数据的潜在分布,利用对抗的形式,DIVERSIFY 获取的特征表示更加多样、鲁棒、有效,并且其有效性也能从理论上得以验证。在多个时间序列公开数据集上的实验结果表明,DIVERSIFY 获得的特征更多样、鲁棒,且所提出的方法对场景依赖度低,更加通用、容易拓展到其他非时间序列数据,如图像和视频中。
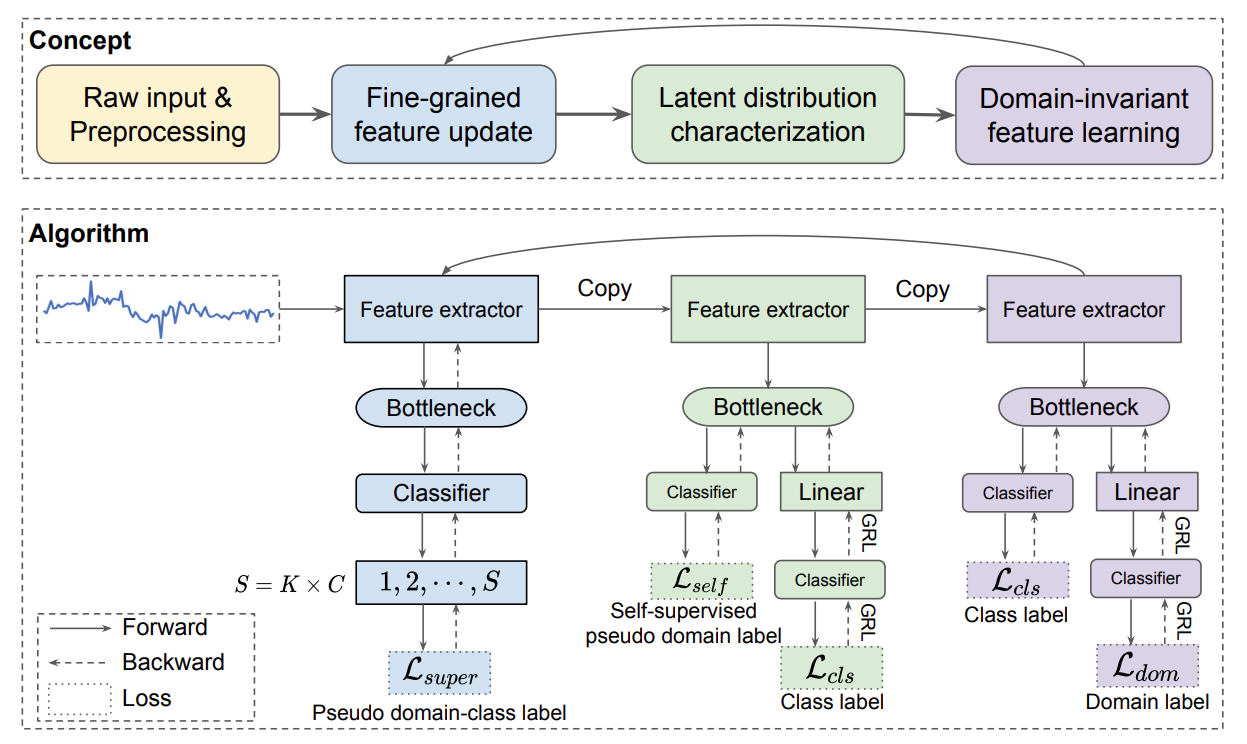
图4: DIVERSIFY 的框架
SoftMatch: 实现半监督学习中伪标签质量和数量的权衡

论文链接:https://arxiv.org/abs/2301.10921
代码链接:https://github.com/microsoft/Semi-supervised-learning
在以往的半监督学习工作中,置信度阈值(confidence thresholding)是比较主流的利用伪标签的方式。比如在 FixMatch 中,置信度高于阈值(0.9)的数据的伪标签会直接引入到训练中。通过设定较高的阈值, 伪标签的质量(即正确性)可以得到保证。
但是,一系列动态阈值的工作如 FlexMatch (NeurIPS'21) 和 FreeMatch (ICLR'23) 指出,过高的阈值丢弃了很多不确定的伪标签,这将导致类别之间的学习不平衡,并且伪标签的利用率较低。动态阈值通过前期降低不同类别或不同数据的阈值,来引入更多的伪标签参与前期训练,但这将不可避免地引入低质量伪标签,因此研究员们提出了 SoftMatch,着重解决如何寻求伪标签数量与质量间的平衡。该工作在图像、文本、长尾分类上均取得了最好的效果。






