
ICML 2022 | 机器学习前沿论文精选!
2022-07-21 | 作者:微软亚洲研究院
编者按:ICML 被认为是人工智能、机器学习领域最顶级的国际会议之一,在计算机科学界享有崇高的声望。ICML 2022 于7月17日-23日以线上线下结合的方式举办。今天我们精选了微软亚洲研究院在此次大会上发表的7篇论文,来为大家进行简要介绍,从强化学习、图神经网络、知识图谱表示学习等关键词带你一览机器学习领域的最新成果!
分支强化学习

论文链接:https://arxiv.org/abs/2202.07995
强化学习(Reinforcement Learning)是一个经典的在线决策模型。在强化学习中,智能体与未知的环境进行交互,以获得最大的累积奖励。传统强化学习是一个单路径的序列决策模型,智能体在一个状态下只选择一个动作。然而,在推荐系统、在线广告等许多现实应用中,用户们往往会一次选择多个选项,每个选项会触发对应的后继状态,例如,在基于类别的购物推荐中,系统往往会先推荐一些商品的一级类别,当某个一级类别被用户点击时,系统会进一步推荐一些二级类别。在一次购物中,用户可能会选择(触发)多条类别-商品路径,如用户可能会触发“办公设备-打印机-激光打印机”和“办公设备-扫描仪-平板扫描仪”这两条路径。
为了处理这种允许多个动作和多个后继状态的现实场景,微软亚洲研究院的研究员们提出了一种新颖的、树状的强化学习模型,名为分支强化学习(Branching Reinforcement Learning)。在分支强化学习中,每个状态下,智能体可以选择多个动作,每个状态-动作对有一个潜在的概率被触发。如果一个状态-动作对被成功触发,那么它会根据其潜在的转移分布转移到一个常规的后继状态;如果这个状态-动作对没有被成功触发,那它则会转移到一个“终止状态”(奖励总是为零的吸收态)。由于智能体可能触发多条状态-动作路径,因此它的历史序列决策呈现出一个树状结构。
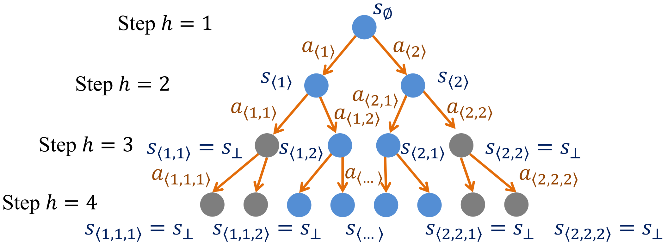
图1:分支强化学习模型示意(当每个状态下允许选择的动作个数为2时)
在分支强化学习这个新的决策模型下,研究员们构建了全新的理论分析工具,包括分支贝尔曼方程(Branching Bellman Equation)、分支价值差异引理(Branching Value Difference Lemma)和分支总方差定律(Branching Law of Total Variance)。研究员们设计了两种计算和采样高效的算法 BranchVI 和 BranchRFE,通过严格的理论分析证明了算法的最优性,并在实验上验证了本文的理论结果。
深入研究置换敏感的图神经网络

论文链接:https://arxiv.org/abs/2205.14368
代码链接:https://github.com/zhongyu1998/PG-GNN
演示链接:https://github.com/zhongyu1998/PG-GNN/blob/main/demo.mp4
图与邻接矩阵的置换不变性是图神经网络(GNN)的首要要求,传统模型通过置换不变的聚合操作来满足这一前提条件。然而,这种高度对称的置换不变聚合方式假定所有邻居结点的地位均等,可能会忽略邻居结点与邻居结点之间的相互关系,进而阻碍 GNN 的表达能力。
与置换不变相反,置换敏感的聚合函数对于结点顺序非常敏感,可以看作是一种“对称性破缺”机制,打破了邻居结点的均等地位。这样一来,聚合函数可以显式地建模邻居结点之间的内在关系(如二元依赖),捕获两个邻居结点之间是否存在连接,从而识别并利用局部的图子结构来提高表达能力。
尽管置换敏感的聚合函数比置换不变的聚合函数具有更加强大的表达能力,但是还需要额外考虑所有n!种置换来保证泛化能力,在计算复杂度上面临着巨大的挑战。为了解决这一问题,本文利用置换群(permutation group)设计了一种新颖的置换敏感聚合机制,通过置换采样策略采样少量具有代表性的置换,捕获邻居与邻居之间的二元依赖,从而高效地提升 GNN 的表达能力:研究员们证明了所提出的方法严格地比二维 Weisfeiler-Lehman(2-WL)图同构测试更强大,并且能够区分一些 3-WL 测试无法区分的非同构图对;此外,相比于传统方法需要考虑所有 n! 种置换,本文所提出的方法能够达到线性的置换采样复杂度。
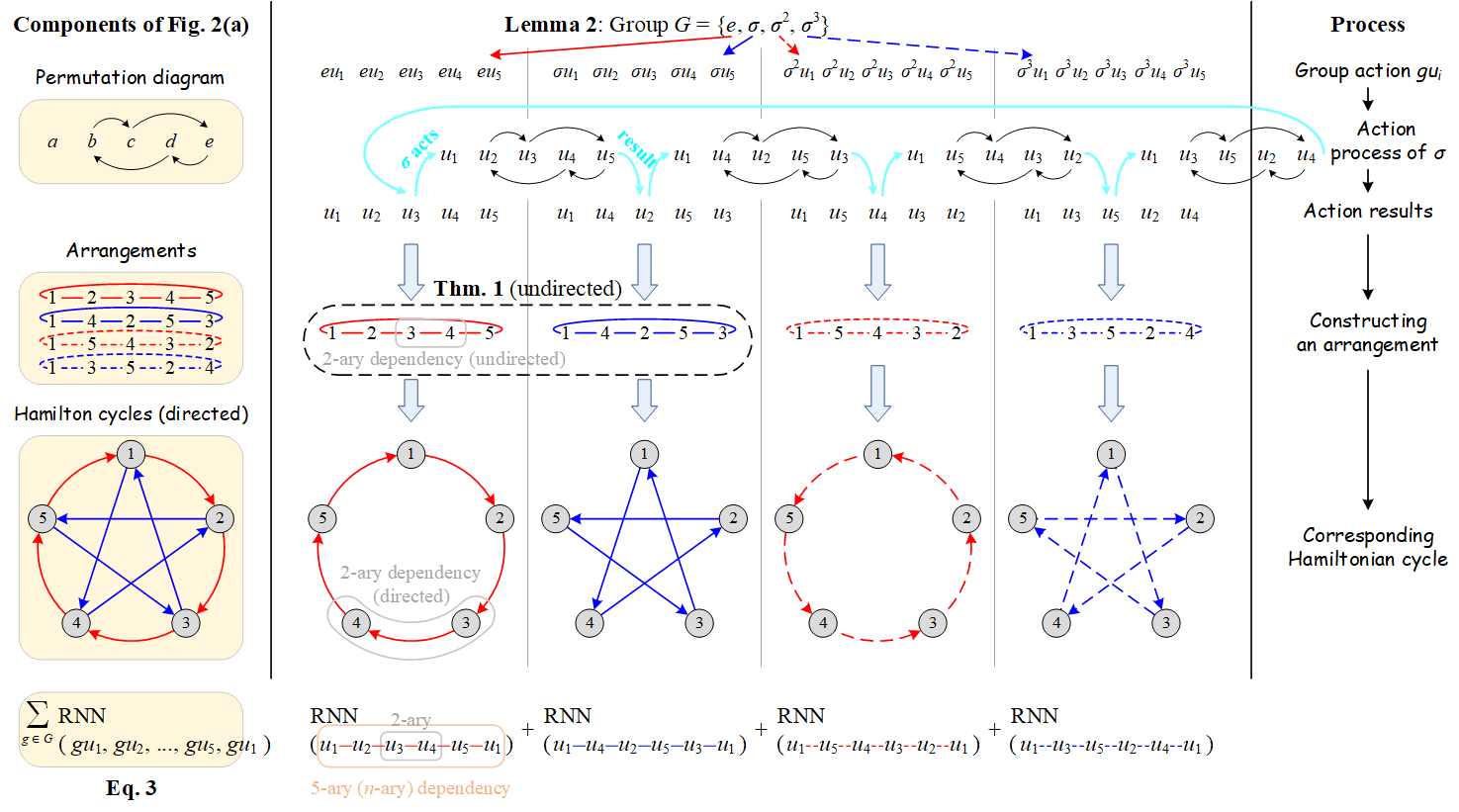
图2:考虑中心结点 v 和5个邻居结点的简单模型示例
综合而言,本文基于置换敏感的聚合机制设计了一种强大而高效的图神经网络,它在保证表达能力的同时,先后借助近似置换不变性的思想与线性置换采样策略,显著降低了计算复杂度。如何利用置换敏感的图神经网络在表达能力上的天然优势,在表达能力和计算复杂度之间寻找均衡,将是未来富有前景的研究方向。
基于Householder参数化的知识图谱表示学习方法

论文链接:
https://arxiv.org/abs/2202.07919
知识图谱表示学习是一种有效缓解知识图谱不完整问题的有效方法。本文对现有知识图谱表示方法的建模能力进行了分析:(1)现有方法中的关系旋转固定于低维空间,这很大程度地限制了模型的建模能力;(2)现有方法无法全面地建模知识图谱中重要的关系模式与映射属性。
为解决以上两个问题,本文引入了 Householder 反射变换作为基本数学工具,并基于此进一步设计了两种线性变换作为知识图谱中的关系表示:(1)由多个 Householder 反射组合而成的 Householder 旋转,可扩展至任意高维空间,实现强大的建模能力;(2)由原始 Householder 反射修改得到的 Householder 投影,可赋予模型建模复杂关系映射属性的能力,同时保持模型对重要关系模式的建模能力。
在此 Householder 框架下,本文得以提出了一个具有更强大、更全面建模能力的 KGE 模型,名为 HousE。HousE 将关系建模为实体间的两阶段变换,如图3所示,对于给定三元组,HousE 首先通过 Householder 关系投影得到关系特定的头尾实体表示,然后在投影后的头尾实体之间建模 Householder 关系旋转。
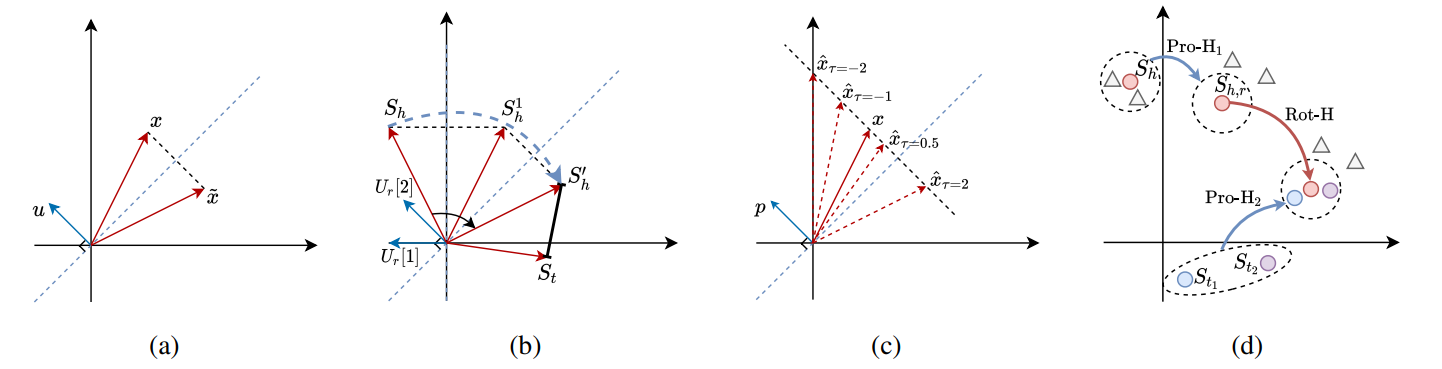
图3:(a) 二维空间中的Householder反射;(b)二维空间中的 Householder 旋转;(c)二维空间中不同 τ 值下对应的 Householder 投影;(d)HousE 图示:为了建模三元组(h, r, t_1)和(h, r, t_2),HousE 首先利用 Householder 投影(Pro-H1 和 Pro-H2)改变实体间的相对距离,然后对投影后的头实体表示 S_(h,r) 进行 Householder 旋转(Rot-H),使其与投影后的尾实体表示尽可能相近。
文章从理论上证明了 HousE 可以建模知识图谱中的重要关系模式和复杂映射属性,并且能够自然地将旋转变换扩展到任意高维空间,是现有基于旋转的知识图谱表示模型的推广。实验上,HousE 在五个公开数据集上均取得了最新的 SOTA 性能,更多实验结果(如细粒度性能分析实验等)也进一步验证了 Householder 框架所带来的强大建模能力。
ClofNet:具有完备局部标架的SE(3)等变图网络

论文链接:https://arxiv.org/abs/2110.14811
群等变性质如置换不变、平移旋转等变性(又称 SE(3) 群等变),是许多 3D 多体物理系统(如分子动力系统)具有的性质。等变图网络是一类满足群等变性质的机器学习模型,常用于 3D 多体物理系统的性质预测、构像生成等任务。群等变模型是指模型的输入输出关于群作用是等变的,即 ϕ_NN (T_g (x))=S_g (ϕ_NN (x)),其中 T_g 和 S_g 是群元素 g 对应的群作用。一个传统设计等变模型的方式是仅作用非线性变换在节点距离上(例如 Radial Nework, Schnet, EGNN 等),并利用邻居节点坐标为标架来表示向量信息。本文指出,这类模型虽然计算高效,但会存在方向退化、表达力不足的问题。本文从等变图网络的表达能力出发,设计了一组 3D 等变局部标架 ClofNet,解决了一类 SE(3) 等变图网络表达力不足的问题。
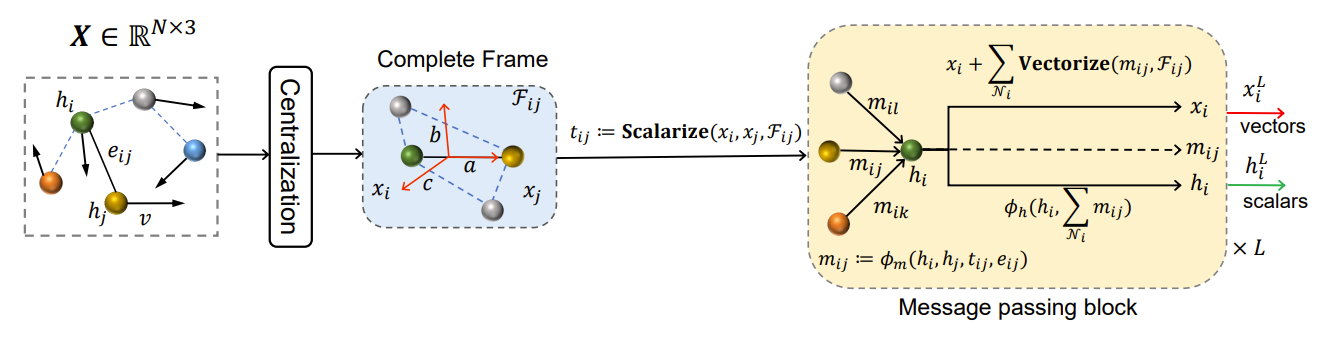
图4:ClofNet 示意图
具体地,对于给定 3D 图,首先对位置坐标进行去中心化,将系统质心移动至原点,这一操作保证了结果的平移不变性。然后给定相邻粒子对位置坐标 (x_i,x_j),建立局部等变标架 (a_ij, b_ij, c_ij ),其中 a_ij=(x_i-x_j)/(||x_i-x_j||), b_ij=(x_i×x_j)/(||x_i×x_j ||), c_ij=a_ij×b_ij。由于叉乘运算的性质,(a_ij, b_ij, c_ij)构成了一组相互正交的 3D 标架。在构建局部标架后,ClofNet 将节点 i, j 对应的张量信息向标架投影,得到一组标量 s_ij=Scalarize(X_i, X_j, (a_ij, b_ij, c_ij)),例如节点 i 的坐标投影后获得标量⟨x_i, a_ij⟩,⟨x_i, b_ij ⟩,⟨x_i, c_ij⟩。标量信息经神经网络作用,输出局部标架的系数,并用局部标架的线性组合表示输出向量,此步骤称为 Vectorization。可以证明,ClofNet 在 SE(3) 群等变函数空间具有一致的表达力。
模型在多体物理系统轨迹预测和 3D 分子结构生成任务上进行了测试。结果表明,ClofNet 显著降低了样本复杂度,并提升了模型预测精度和生成效果。
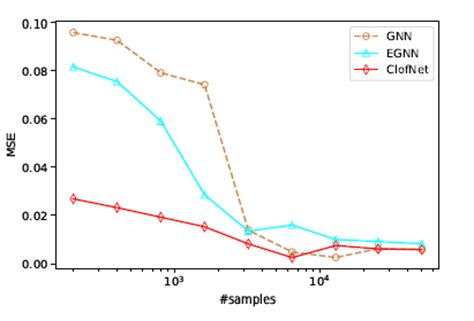
图5:不同训练样本量下的均方误差结果
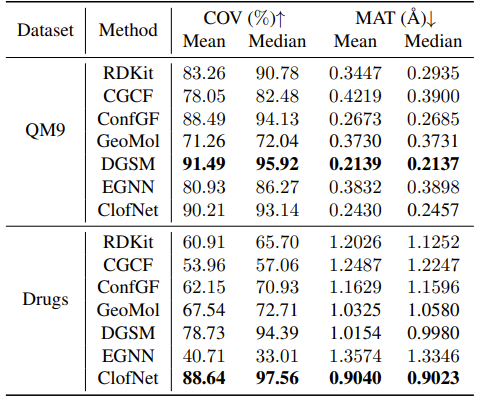
表1:不同算法在数据集 GEOM-QM9 和 GEOM-Drugs 上的实验结果
神经架构搜索中干扰问题的分析与解决

论文链接:https://arxiv.org/abs/2108.12821
在当前的自动架构搜索技术中,权重共享作为一种最为流行的核心技术被广泛应用。权重共享通过复用之前训练的子结构的部分权重来减少从零开始训练不同子模型的代价。然而,由于不同子模型的共享权重梯度更新时存在干扰,如图6和图7所示,所以真实的子模型的准确率和最后估计的子模型的准确率之间的相关度往往比较低,严重影响了神经架构搜索技术的性能和适用性。
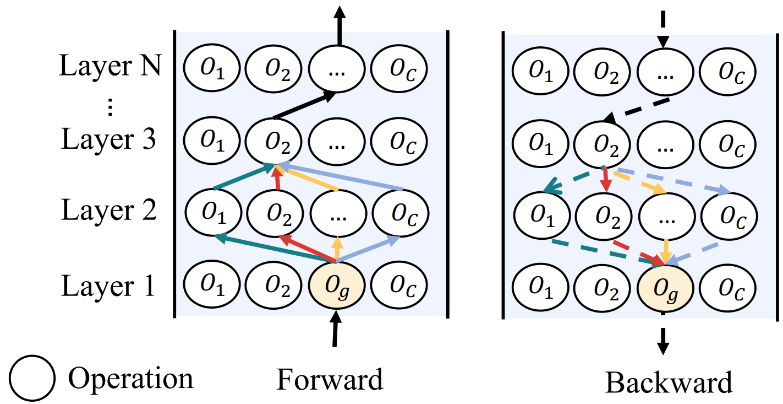
图6:不同架构在权重上的梯度干扰示意
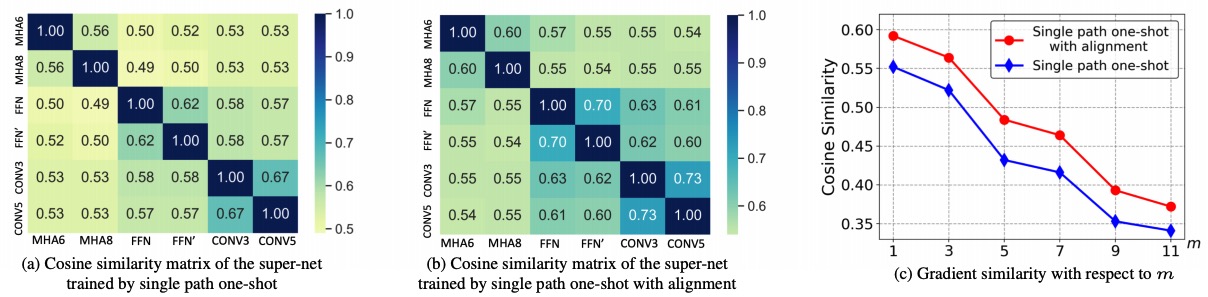
图7:不同子模型在共享权重的梯度相似度
在这个工作里,研究员们深入研究了权值共享中的干扰问题。通过采样不同的子模型并计算这些子模型在共享的部分权值上的梯度,研究员们观察到了两个现象:1)共享权值上的梯度的干扰程度和两个子模型之间的不同网络层结构的数量是正相关的;2)两个子架构在共享网络结构上的输入和输出值越相似,他们之间的干扰就越小。
从以上两个观察出发,本文提出了 MAGIC-AT 技术来有效缓解干扰问题,它包括两项关键技术:
1)MAGIC-T:与之前的随机采样子模型进行梯度更新的工作不同,本文提出了一个渐进子架构修改的采样范式。在每一次临接的梯度更新步数之间,让其采样的子架构仅仅存在一个网络层结构的差别以最小化不同邻接梯度更新的干扰。
2)MAGIC-A:强制让不同子模型在共享网络结构上的输入输出尽可能相似来进一步减少他们之间的干扰。
研究员们首先在一个复杂的 BERT 搜索空间中验证了本文提出的两项关键技术都能够提升超网络的排序性能,并且两种技术结合能够得到进一步的提升。接着,研究员们使用 MAGIC-AT 在 BERT 语言模型(如表1所示),SQuAD 自然语言理解任务以及大规模图像分类问题 ImageNet 上做了神经架构搜索,实验证明 MAGIC-AT 搜索得到的架构一致且显著的超过之前的工作,证明了本文方法的有效性。
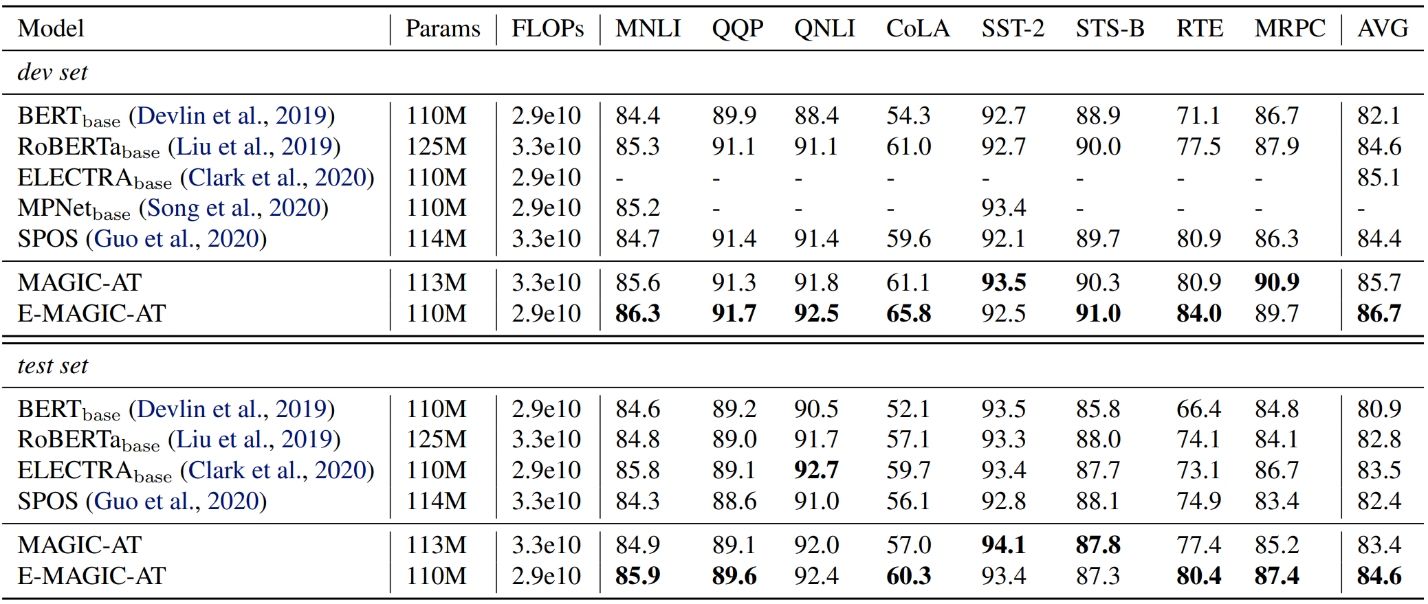
表2:MAGIC-NAS 搜索的 BERT 语言模型在 GLUE 数据集上的效果
监督离策略排序

论文链接:https://arxiv.org/abs/2107.01360
离策略评估(Off-Policy Evaluation, OPE)旨在利用由其他策略产生的数据评估目标策略的性能。OPE 在许多实际应用中至关重要,如交易、广告、自动驾驶、药物试验等等。在这些应用中,通过与真实环境交互的在线评估策略方式可能花费成本巨大。
现有的 OPE 方法主要基于分布纠正(distribution correction)、模型估计(model estimation)和价值函数估计(Q-estimation),关注的是精确估计策略的回报,采用的是无监督估计方法。本文发现这些方法与现实需求和条件存在差异。首先,在许多应用中,OPE 的最终目标是从候选策略中选择较好的策略,而非精确估计每个策略的回报。其次,人们通常可以知道一些已在真实环境中部署的策略的性能,但是这部分信息未被利用。因此,本文定义了两个新问题:监督离策略估计(Supervised Off-Policy Evaluation, SOPE)和监督离策略排序(Supervised Off-Policy Ranking, SOPR),分别利用离策略数据集以及已知策略的回报或排序来估计目标策略的性能或性能排序。其中,SOPR 不需精确估计策略性能,更加容易并且更具实际应用价值。
本文还进一步提出了一种基于监督学习的策略排序算法,利用策略表示和策略排序标签训练了一个策略打分模型,并基于策略得分对策略排序。对于策略表示,由于不同策略可能函数形式不同输入特征不同,且不一定具有参数,因此难以采用策略参数表示策略。对此,本文提出利用状态-动作数据和一种分层 Transformer 编码器学习策略表示,其中状态出自离策略数据集,动作由策略在状态上决策产生;然后通过对数据进行聚类,在类内和类间分别编码;最后将策略表示映射为分数,利用排序损失函数优化模型。该算法名为 SOPR-T,T 代表 Transformer。本文利用 Mujoco 环境的公开数据集对所提算法进行了验证,并与 OPE 基线算法对比,结果表明 SOPR-T 在排序相关度(Rank correlation)和后悔值(Regret value)上的表现均优于基线算法。
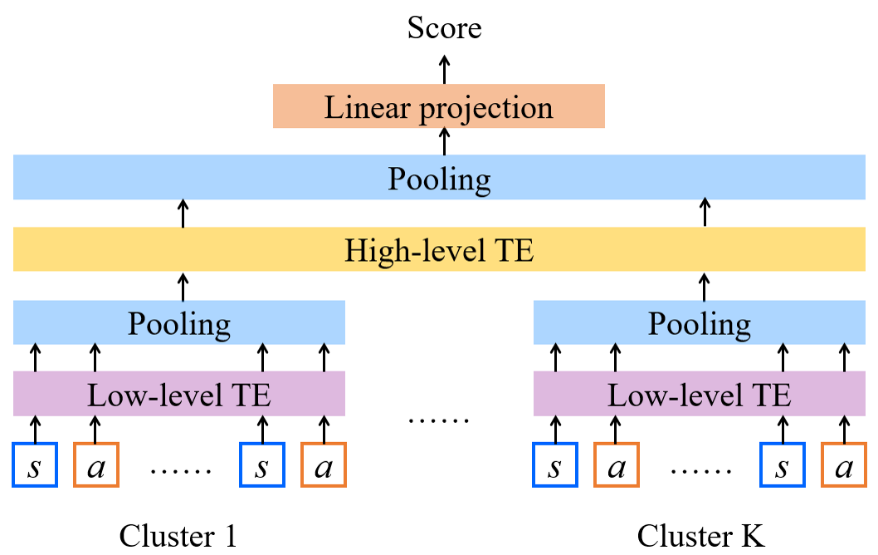
图8:基于分层 Transformer 编码器的策略打分模型
捕获异质图中的全局同质节点

论文链接:
https://arxiv.org/abs/2205.07308
在具有异质性(Graph heterophily)的图中,相邻节点间更倾向于有不同的标签。业界称具有相同标签的节点记为同质节点,不同标签的节点记为异质节点。当用传统 GNN 方法(GCN、GAT等)去学习异质图节点的表示时,会导致当前节点的表示被邻域中更多的异质节点所误导,从而学习到错误的表示。现有的研究尝试通过增大邻域的范围去捕获更多的同质节点来指导当前节点的学习。但这其中存在一个挑战:该使用多大范围的邻域?微软亚洲研究院的研究员们给出的解决方案是:使用全局邻域,即使用整张图。
为此,研究员们提出了一个新的 GNN 模型 GloGNN,其架构如图10所示,输入包括节点特征和邻接矩阵,经融合得到初始的节点特征矩阵。在之后的每一层中,GloGNN 基于一个系数矩阵来对节点特征矩阵进行更新。该系数矩阵刻画了整张图中所有节点间的相关性,由一个同时考虑节点特征和拓扑结构的优化函数求解得到,并且引入 Woodbury Formula 优化求逆过程和调整矩阵乘法顺序将更新过程的时间复杂度降低为线性复杂度。此外,研究员们还提出了升级版的 GloGNN++,其不仅考虑节点之间的相关性,也关注节点特征中每一维的重要性。最后,本文从理论和实验两方面证明了方法的有效性。

图9:GloGNN 架构
理论方面,通过对更新过程中的系数矩阵和节点特征进行 Grouping Effect 分析,验证了方法设计的合理性。实验方面,研究员们在15个不同领域、规模、异质性的数据集上与代表性的11种 GNN 方法进行了比较,并做了大量的效率分析和可解释性分析,结果表明本文提出的 GloGNN 和 GloGNN++ 可以有效且高效地从整张图中捕获同质节点。






