
如何高效、精准地进行图片搜索?看看轻量化视觉预训练模型
2022-07-28 | 作者:微软亚洲研究院
编者按:你是否有过图像检索的烦恼?或是难以在海量化的图像中准确地找到所需图像,或是在基于文本的检索中得到差强人意的结果。对于这个难题,微软亚洲研究院和微软云计算与人工智能事业部的研究人员对轻量化视觉模型进行了深入研究,并提出了一系列视觉预训练模型的设计和压缩方法,实现了视觉 Transformer 的轻量化部署需求。目前该方法和模型已成功应用于微软必应搜索引擎,实现了百亿图片的精准、快速推理和检索。本文将深入讲解轻量化视觉预训练模型的发展、关键技术、应用和潜力,以及未来的机遇和挑战,希望大家可以更好地了解轻量化视觉预训练领域,共同推进相关技术的发展。
近来,基于 Transformer 的视觉预训练模型在诸多计算机视觉任务上都取得了优越性能,受到了广泛关注。然而,视觉 Transformer 预训练模型通常参数量大、复杂度高,制约了其在实际应用中的部署和使用,尤其是在资源受限的设备中或者对实时性要求很高的场景中。因此,视觉预训练大模型的“轻量化”研究成为了学术界和工业界关注的新热点。
对此,微软亚洲研究院和微软云计算与人工智能事业部的研究员们在视觉大模型的结构设计和训练推断上进行了深入探索,同时还对大模型的轻量化、实时性以及云端部署也做了创新应用。本文将从轻量化视觉预训练模型的发展谈起,探讨模型轻量化研究中的关键技术,以及轻量化视觉 Transformer 模型在实际产品中的应用和潜力,最后展望轻量化视觉模型的未来发展机遇和挑战。
视觉大模型层出不穷,轻量化预训练模型却乏人问津
最近几年,深度学习在 ImageNet 图像分类任务上的进展主要得益于对视觉模型容量的大幅度扩增。如图1所示,短短几年时间,视觉预训练模型的容量扩大了300多倍,从4,450万参数的 ResNet-101 模型,进化到了拥有150亿参数的 V-MoE 模型,这些大型视觉预训练模型在图像理解和视觉内容生成等任务上都取得了长足进步。

图1:视觉预训练模型参数量的变化趋势图
无论是微软的30亿参数 Swin-V2 模型,还是谷歌发布的18亿参数 ViT-G/14 模型,视觉大模型在众多任务中都展现了优越的性能,尤其是其强大的小样本(few-shot) 甚至是零样本 (zero-shot) 的泛化能力,对实现通用智能非常关键。
然而,在很多实际场景中,由于存储、计算资源的限制,大模型难以直接部署或者无法满足实时需求。因此,轻量级的视觉预训练模型研究变得越来越重要,且具有很强的实际应用价值。尽管目前有一些工作在探讨轻量级模型,但是这些方法大多是针对特定任务、特定结构设计的,在设计和训练过程中没有考虑到模型的通用性,存在跨数据域、跨任务的泛化局限性。
轻量化视觉模型的关键技术研究
为了实现轻量化视觉预训练模型,微软的研究员们发现了两大关键问题:1)如何设计出通用性更强的轻量化模型结构?2)受制于轻量化视觉预训练模型的有限容量,如何设计高效的预训练方法让小模型也能学习到大规模数据中的有效信息?面对这些难题,研究员们通过坚持不懈的研究和探索,目前取得了一些阶段性成果。
由于提高轻量化预训练模型通用性的核心在于如何在资源受限(参数量,时延等)的情况下强化模型的学习能力,使其能够更好地在大规模数据中学习通用特征,因此,研究员们从以下三个角度进行了深入探索:
1. 轻量化模块设计
轻量、低延时的模块是组成轻量级模型的重要部分。在卷积神经网络中,具有代表性的轻量级模块有MobileNet的反向残差模块(Inverted Residual Block)以及 ShuffleNet 的通道随机交叉单元(Shuffle Unit)。在视觉 Transformer 结构中,由于图像块之间注意力的计算没有很好地考虑相对位置编码信息,因此研究员们设计了即插即用的轻量级二维图像相对位置编码方法 iRPE [1],它不需要修改任何的训练超参数,就能提高模型的性能。此外,针对视觉 Transformer 参数冗余的问题,研究员们设计了权重多路复用(Weight Multiplexing)模块 [2]。如图2所示,该方法通过多层权重复用减少模型参数的冗余性,并且引入不共享的线性变换,提高参数的多样性。

图2:Transformer 中的权重多路复用模块
2. 轻量化模型搜索
网络结构搜索(Neural Architecture Search)可以从模型设计空间中自动找到更加轻量、性能更加优异的模型结构 [3]。在卷积神经网络中,代表性工作有 NASNet 和 EfficientNet 等。在视觉 Transformer 结构搜索中,针对视觉模型中的通道宽度、网络深度以及 head 数量等多个维度,研究员们先后提出了 AutoFormer [4] 和 S3 [5],实现了视觉模型的动态可伸缩训练与结构搜索。在同样模型精度的情况下,搜索得到的新模型具有更小的参数量和计算量。值得注意的是,在 S3 中,研究员们利用 E-T Error [5]以及权重共享超网来指导、改进搜索空间,在得到更高效的模型结构的同时也分析了搜索空间的演进过程,如图3所示。与此同时,模型结构搜索的过程为轻量化模型的设计提供了有效的设计经验和参考。
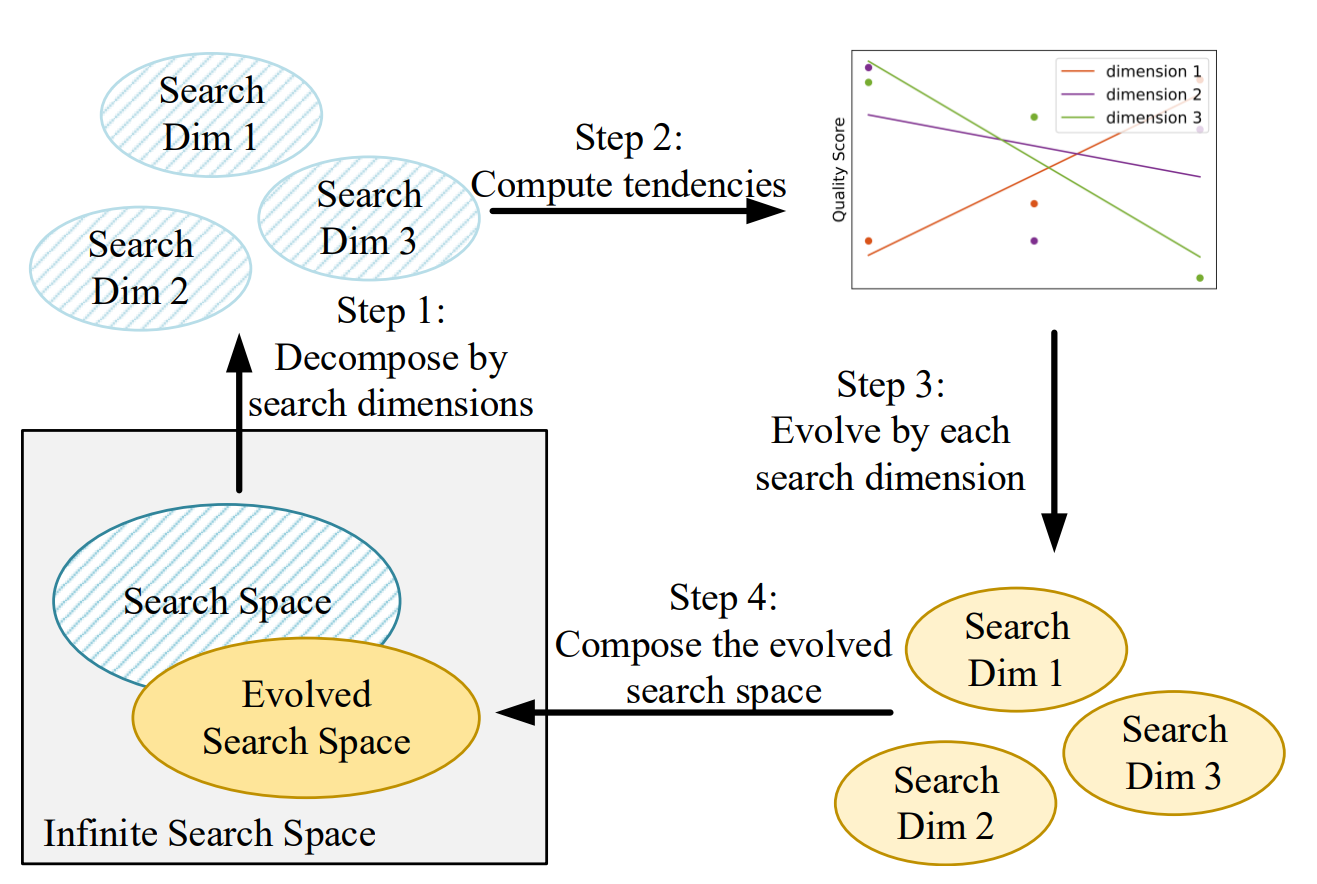
图3:轻量级模型搜索空间进化过程
3. 视觉大模型压缩与知识迁移
轻量级预训练模型的另一难题在于,由于模型容量有限,难以直接学习大规模数据中包含的丰富信息和知识。为了解决这一问题,研究员们提出了快速预训练蒸馏方案,将大模型的知识迁移到轻量化的小模型中 [6]。如图4所示,和传统的单阶段知识蒸馏不同,快速预训练蒸馏分为两个阶段:1)压缩并保存大模型训练过程中使用的数据增广信息和预测信息;2)加载并恢复大模型的预测信息和数据增广后,利用大模型作为教师,通过预训练蒸馏指导轻量化学生模型的学习和训练。不同于剪枝和量化,该方法在权重共享的基础上使用了上文中提到的权重复用[2],通过引入轻量级权重变换和蒸馏,成功压缩视觉预训练大模型,得到了通用性更强的轻量级模型。在不牺牲性能的情况下,该方法可以将原有大模型压缩数十倍。

图4:快速预训练知识蒸馏
这一系列的研究成果,不仅在计算机视觉的顶级学术会议上(CVPR、ICCV、ECCV、NeurIPS等 )发表了多篇论文[1-6],也通过和微软必应的合作,成功将轻量化预训练模型应用到了图像搜索产品中,提高了实际业务中图像和视频内容理解的能力。
轻量级视觉预训练模型的应用
轻量级视觉预训练模型在实际中有诸多用途,尤其是在实时性要求高或者资源受限的场景中, 例如:云端视频实时渲染和增强、端测图像、视频内容理解。轻量级视觉模型已经在智能零售、先进制造业等领域展现出了广阔的应用前景,将来还会在元宇宙、自动驾驶等新兴行业发挥重要作用。以微软必应产品中的图像内容搜索为例,下面为大家展示一下轻量化视觉模型的实际应用和部署。
目前,基于内容的图片搜索在图片的类别属性理解上已经比较成熟,但对于复杂场景的内容理解仍有很大的挑战。复杂场景的图片通常具有大景深、背景杂乱、人物多、物体关系复杂等特点,显著地增加了内容理解的难度,因而对预训练模型的鲁棒性和泛化性提出了更高的要求。
举例来说,动漫图片的搜索质量在很长一段时间内无法得到有效提升,其主要的挑战包括:绘画线条和颜色比真实场景图片更加夸张,包含更多动作和场景,不同漫画之间的风格内容差异巨大。图5到图7分别展示了“灌篮高手”、“皮卡丘”和“足球小将”三种不同的动漫人物和行为,其漫画风格和内容差别迥异。如何有效地理解漫画图片内容,对视觉预训练模型提出了较高的要求。
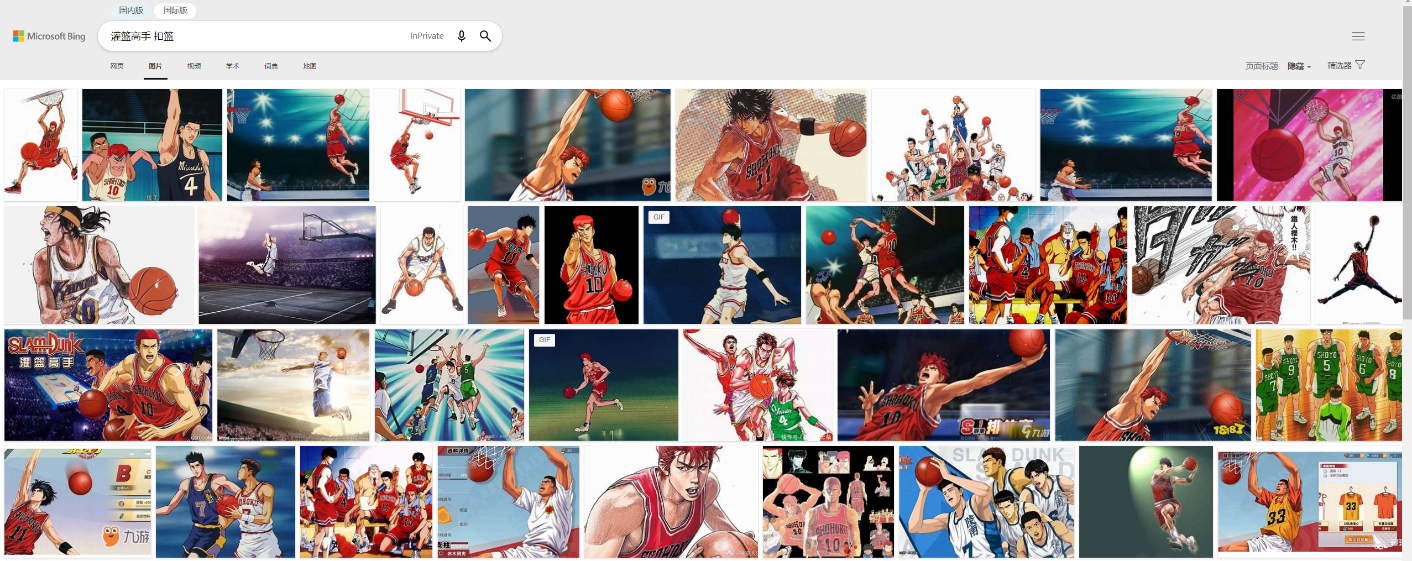
图5:在微软必应搜索引擎中,对灌篮高手的动作理解包括:扣篮,运球,抢断,投篮等

图6:在微软必应搜索引擎中,对皮卡丘行为的理解比如吃苹果、吃西瓜,吃雪糕等

图7:在微软必应搜索引擎中,对足球小将射门动作的特写
上文中提到的轻量级视觉通用模型以及快速预训练蒸馏算法目前已成功应用于微软必应搜索引擎中。借助微软亚洲研究院提供的视觉语言多模态预训练模型,微软必应图片搜索功能增强了对漫画内容的理解,可以返回与用户需求更为匹配的图片内容。
与此同时,微软必应搜索引擎庞大的索引库对于检索效率有非常高的要求。微软亚洲研究院提供的快速预训练蒸馏方法有效地将预训练大模型的索引能力迁移到轻量化模型中,在识别准确率上将现有模型提升了14%,同时极大地优化了模型的计算效率,实现了百亿图片的快速推理。
未来的机遇与挑战
模型轻量化是人工智能未来应用落地的核心。随着视觉技术、算法、算力和数据等不断完善,模型的复杂度急剧攀升,神经网络计算的能耗代价越来越高。轻量化视觉模型高效的计算效率和低廉的部署应用成本,能够在未来更多的实际产品中发挥巨大优势。除此之外,本地化的轻量级预训练视觉模型在支持更多服务的同时,还能够更好地保护用户数据和隐私。用户的数据将不再需要离开设备,即可实现模型服务等功能的远程升级。
当然,研究人员也意识到轻量级预训练视觉模型所面临的挑战:一方面在模型结构设计上,如何在模型参数量和推理延时的限制下达到模型的最优学习能力,一直以来都是学术界和工业界密切关注的问题。虽然目前已经沉淀了不少有效的模型结构,在通用近似定理(UAT)、神经网络结构搜索(NAS)等领域也取得了长足的发展,但是现有的轻量级预训练视觉模型和视觉大模型之间仍有差距,有待进一步优化和提升。另一方面在训练方法上,学术界和工业界针对视觉大模型提出了自监督、图像分类和多模态等多种训练方法,显著提升了模型的通用能力。如何针对容量有限的轻量级模型设计更有效的训练方式,还需要进一步的研究和探索。微软亚洲研究院的研究员们将不断推进轻量级预训练视觉模型的科研进展,也欢迎更多科技同仁共同交流、探索该领域的相关技术。
参考文献
[1] Rethinking and Improving Relative Position Encoding for Vision Transformer, ICCV 2021.
[2] MiniViT: Compressing Vision Transformers with Weight Multiplexing, CVPR 2022.
[3] Cyclic Differentiable Architecture Search, TPAMI 2022.
[4] AutoFormer: Searching Transformers for Visual Recognition, ICCV 2021.
[5] Searching the Search Space of Vision Transformer, NeurIPS 2021.
[6] TinyViT: Fast Pretraining Distillation for Small Vision Transformers, ECCV 2022.
本文作者:彭厚文,延浩然,李弼翀,傅建龙,魏思宁






