
SPINE:高拓展性、用户友好的自动化日志解析新神器
2022-11-11 | 作者:DKI
编者按:在计算机系统与软件的实践和研究中,可靠性是至关重要且经久不衰的课题。如何自动化地分析日志所记录的系统状态并让数据“说话” ,受到了广泛研究。日志解析是自动化日志分析中的关键起步。如何将日志解析应用于大规模复杂的云环境往往面临诸多现实挑战,如数据不均衡,数据漂移等。
为了解决这些挑战,微软亚洲研究院的研究员们提出了支持用户反馈且具有高可扩展性的日志解析方法 SPINE。该方法被软件工程领域顶级会议 ESEC/FSE 2022 接收,并荣获 “杰出论文奖” (ACM SIGSOFT Distinguished Paper Award)。SPINE 是如何提升日志解析效果和性能的呢?让我们从今天的文章中获得答案吧!
在云计算时代,软件系统的可靠性至关重要,一点小问题就可能引发蝴蝶效应,影响百万用户。为了了解并保障软件系统的稳定,日志被广泛用于观测并忠实记录系统的内部状态,是分析与解决系统故障的基础。然而,使用人工分析体量巨大的日志并不现实,因此自动化日志分析日渐兴起,而日志解析是关键且基础的步骤。在实践中,日志数据往往存在着数据量巨大、极度不均衡、数据漂移且没有标注等问题。为了解决这些问题,并将日志解析真正落实到复杂的云环境中,微软亚洲研究院的研究员们和微软 Azure 的工程师们提出了支持用户反馈的大数据场景下的日志解析方法 SPINE,并将其落地到了产品线中。
近日,SPINE 被软件工程领域的全球顶级会议 ESEC/FSE 2022 接收,并荣获 “杰出论文奖” (ACM SIGSOFT Distinguished Paper Award)。

论文链接:https://www.microsoft.com/en-us/research/publication/spine-a-scalable-log-parser-with-feedback-guidance-2/
ESEC/FSE 大会全称为 ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE) ,与 ICSE、ASE 并列为软件工程领域三大顶级会议,在学术界和工业界都具有极大的影响力。今年的 ESEC/FSE 大会有效投稿量为449,最终接收99篇,接收率约为22%,会议将于2022年11月14日至18日在新加坡举办。
日志解析:智能日志分析的关键核心
自动化日志分析在近年来逐渐成为研究热点,例如基于日志的异常检测、故障诊断、故障预测等。几乎所有的自动化日志分析技术,都依赖于日志解析这一关键的前置步骤。经过日志解析,将半结构化文本形式的原始日志转换为结构化的日志数据之后,下游的各类日志分析任务才能自动化地执行。
日志解析可从形式上被定义为:从原始日志信息中提取日志模板和日志参数的任务。日志信息的主体通常由两部分构成:(1) 模板:描述系统事件的静态的关键字,通常为一段自然语言,这些关键字被显式地写在日志语句的代码中。(2) 参数:也称为动态变量,是在程序运行期间的某个变量的值。

图1:日志解析示例
现阶段,大量的自动化日志解析工作致力于准确高效地分离日志中的模板和参数部分。尽管这些日志解析器在公开的基准日志数据集上取得了良好成效,但它们在实际应用中仍然面临诸多挑战。微软的研究员和工程师们通过在实际工业环境中进行的大量例证研究,揭示出其中的两个核心挑战。
大规模、不平衡的日志数据
首先,大多数现有的日志解析器只能在单线程模式下运行。然而,现实世界的日志数据量极为庞大。例如,在例证研究中,仅微软某个内部服务,平均每天就会产出约50亿条日志,合每小时约2亿条。如此规模的数据量超出了任何单一计算核或节点的处理能力,尤其难以满足实时日志分析的需要。
表面上,日志解析似乎是一项很容易并行化的任务。然而,工业实践中日志数据的内在不平衡性将大大降低并行化的效率。这促使研究员们设计一种能够在多个计算单元上进行更有效的横向扩展的日志解析器。
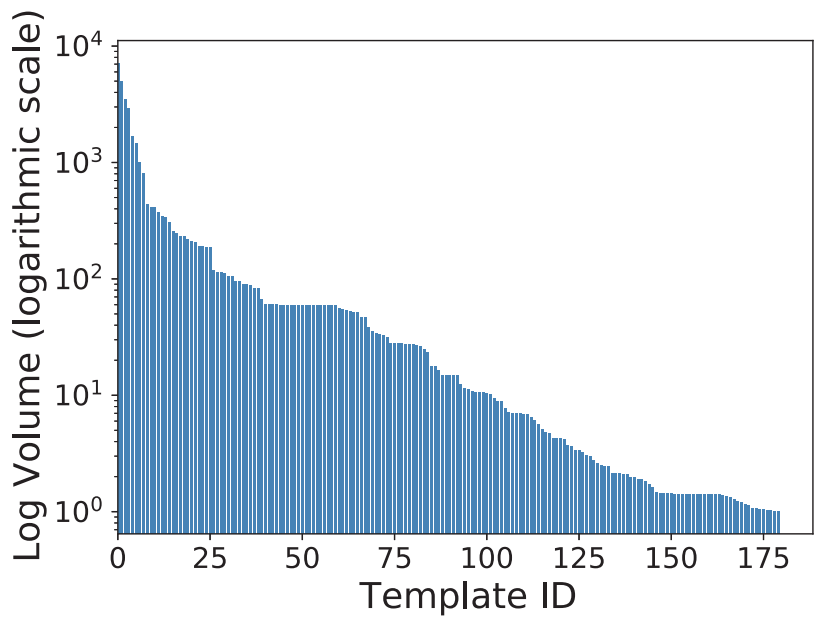
图2:不同日志模板下日志数量分布:X 轴表示模板 ID,Y 轴表示对应于该模板的日志数量(Y 轴为对数标度)。
日志漂移与解析器的快速适应
另一个挑战来自于日志伴随着软件系统的迭代而不断发生变化。研究员们在微软某内部服务中收集了8周的日志,并计算随着时间推移而新出现的日志模板的数量,结果如图3所示。由于持续集成/交付(CI/CD)的开发范式,日志模板的数量会随时间增加,日志解析器也应不断地更新,以适应数据的漂移,否则解析的准确度会随时间流逝而逐渐下降。
遗憾的是,因为缺少足够的有标签数据,现有的日志解析器大多采用无监督的方法,例如聚类、频繁模式挖掘、最长共同子序列提取等来识别日志的公共部分作为模板。这需要大量的人工标注来进行繁琐的模型超参数调整,并且要求用户对日志解析方法的内部原理极为熟悉。因此,研究员们认为日志解析应当降本增效,尽可能地降低用户反馈机制的成本,提高用户体验,以达到快速调整日志解析器参数的效果。
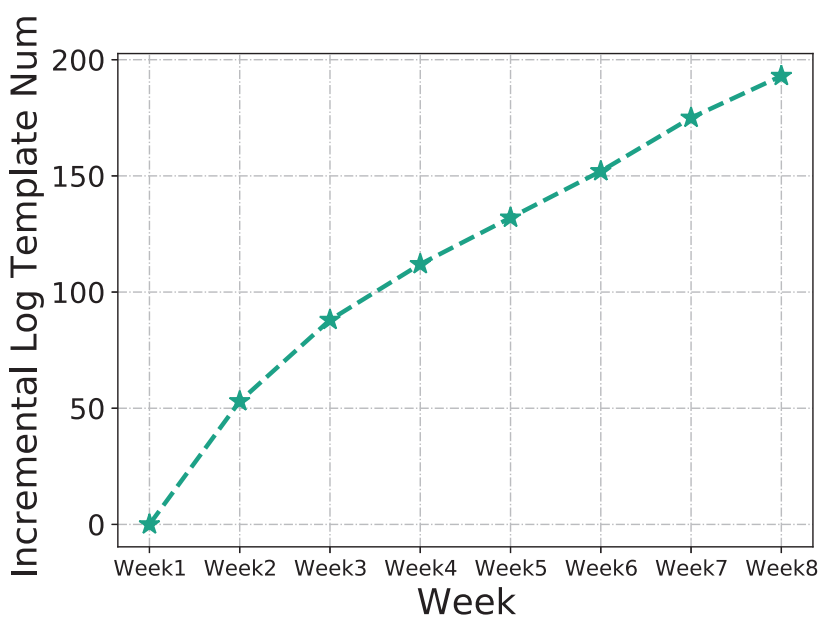
图3:新日志模板数量增加曲线
反馈支持的高扩展日志解析器 SPINE
针对上述问题,微软亚洲研究院的研究员们设计了 SPINE。SPINE 具体分为两个阶段:离线训练阶段(红色箭头)和在线解析阶段(绿色箭头)。在离线训练阶段,SPINE 会基于收集的日志数据训练一个初始模型。随后,在在线解析阶段,应用训练得到的日志解析模型,处理不断更新的在线日志数据。
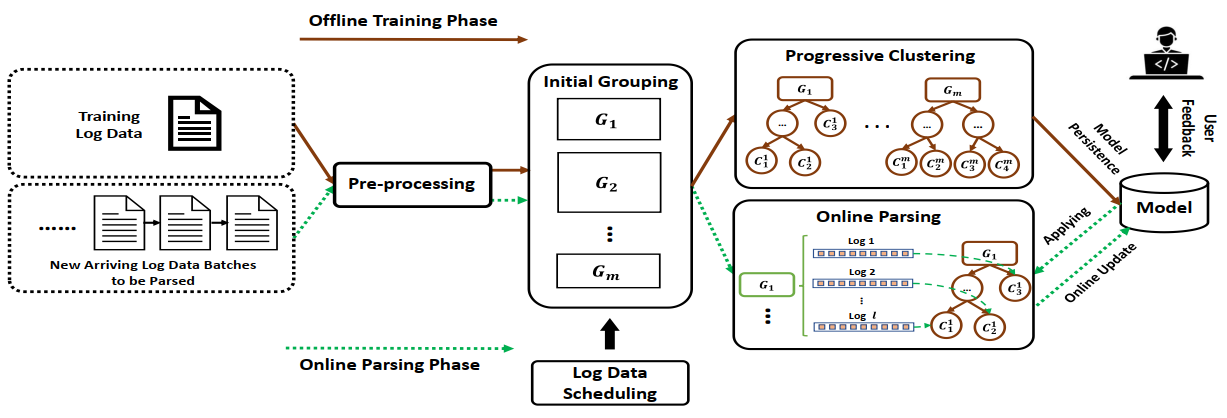
图4:SPINE 模型总体架构图
SPINE 包含四个核心组件:日志数据预处理(Pre-processing)、初始分组(Initial grouping)、渐进式聚类(Progressive clustering)和在线解析(Online parsing)。首先,对原始的日志分词,并进行必要的日志清理。在此之后,初始分组模块会将日志快速分割成粗粒度的、互不重叠的多个日志组(log group)。再将渐进式聚类算法应用于每个日志组 ,把相似的日志进一步划分为细粒度的日志簇(log cluster)。一个日志簇中的日志,可以认为诞生于同一个日志打印语句。因此,可以提取其共同的 token 作为模板,将其余部分视为参数。在线解析阶段,SPINE 会将学习到的模型应用于新到来的日志数据。基于这些日志和模型中已有的日志模版之间的相似度,将其归属为最相似的日志簇中,并解析出其模板和参数。
SPINE 可以灵活地扩展到多个并行计算单元,以应对极大规模的工业日志数据。为了应对工业日志数据的极端不平衡性,研究员们设计了一种特殊的日志数据调度算法来平衡不同计算单元上的工作负载,以节约总体运行时间。此外,SPINE 还设计了专门的用户反馈机制来维持在漂移日志数据下的解析精度。
并行化日志数据调度
在前置步骤中,日志被划分成不同的日志组。然而,工业日志数据的不平衡性会导致日志的解析时间往往受制于最大的那个日志组。这一挑战促使了新的调度算法设计的诞生,将日志解析任务更均匀地分配给多个计算单元,以达到最佳性能。假设𝑚个日志组 g_i∈G 被分配到𝑛个计算单元 e_i∈E。理想情况下,每个计算单元将处理相等数量的 avg = ∑_(i=1)^m|g_i |/n 的日志消息,其中 |𝑔𝑖| 是日志组 g_i 的大小。为了实现这一目标,研究员们将数量高于平均水平的日志组分割成更小的子组,使其日志数量接近平均值,同时合并数量少于平均水平的日志组,使其所产生的超集的规模也接近于平均水平。算法细节可参考图 5中的伪代码。

图5:日志数据并行化调度算法
用户反馈融合
SPINE 模型架构中使用了渐进聚类算法进行细粒度的日志聚类。在每个日志组中,日志信息首先被转换为 one-hot 向量,再利用常见聚类方法(例如 K-Means 或高斯混合聚类)对日志向量进行聚类,将其分为两个子组。同样的过程在每个子组上迭代进行,直到满足停止条件。结果可得一棵二叉聚类树,树上的叶子结点即为日志簇,如图6所示。此算法的优点在于:(1)其算法本身具有极高的聚类效率。(2)该算法非常容易控制聚类的粒度。其核心在于是否需要继续沿着聚类树进行二叉分裂。这为用户决定何时停止聚类提供了可能。
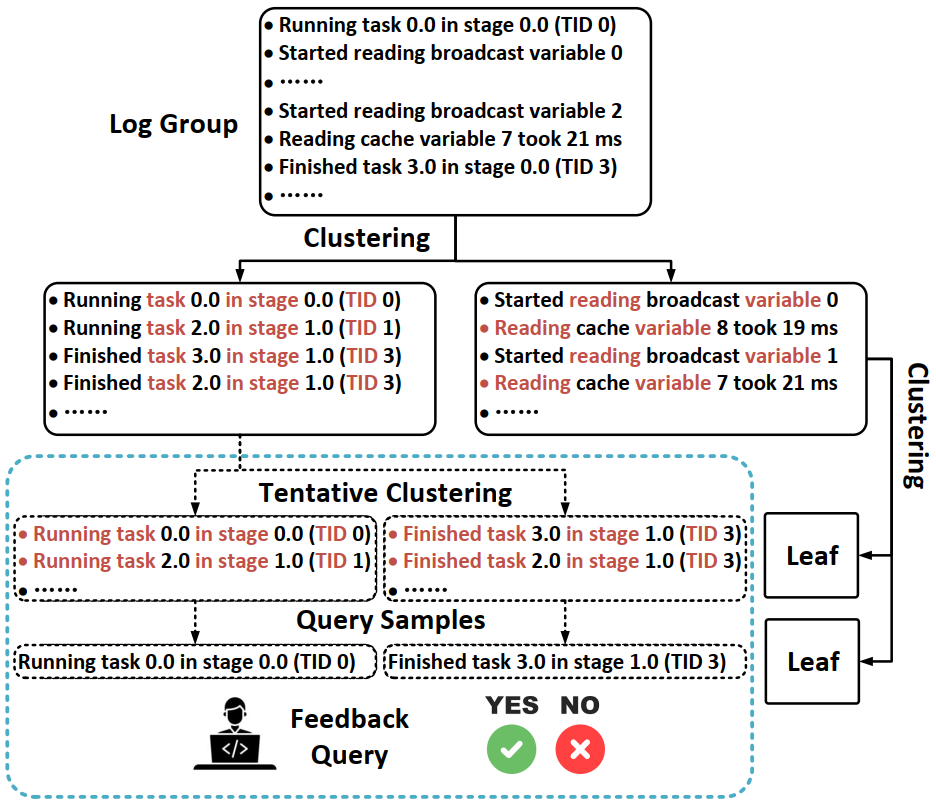
图6: 渐进聚类与用户反馈查询示意图
用户的反馈过程涉及多轮查询,在每一轮中,SPINE 在一定条件下会向用户推荐来自同一日志簇的一对日志,用户对于这对日志是否共享相同的模板给出反馈。用户的反馈有助于SPINE决定是否将相应的日志簇分成两个子簇。随后,SPINE 选择下一个需要反馈指导的日志簇决定是否要拆分。图6显示了一个反馈查询的例子。
如何尽可能少地标注日志数量,并同时最大限度地提高模型的准确性,是设计反馈机制的核心问题。SPINE 的反馈查询的选择基于饱和度增益(saturation gain)进行的。我们约定,若一个 token 在某一 log cluster 的每条日志消息中都出现过,则视为一个 saturated token。一般来说,平均 token saturation 越高,意味着这组日志共享了更多的单词,所以它们越有可能是来自同一个日志生成语句。饱和度增益是指,如果我们把一个叶子节点分成两个子叶子节点,饱和度的增量。我们计算一个叶子节点 ln 的饱和度增益 G_ln,如公式1所示。该公式反映出继续向下分裂聚类树是否能所带来的更多的 saturated token,从而有较高的提高解析精度的可能性。
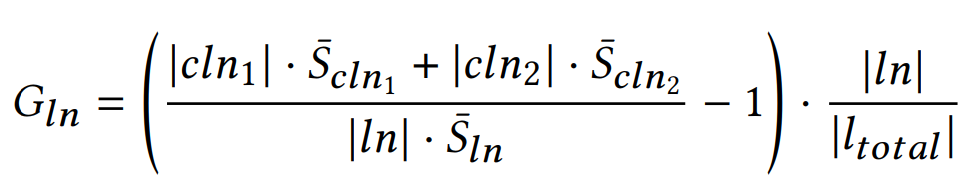
公式 1:饱和度增益计算公式
实验结果
研究员们在16个公开的日志数据集上对 SPINE 进行了大量实验,以回答以下研究问题。
- RQ1: 在没有反馈指导和并行化加速的情况下,基础版本的 SPINE 效果和效率如何?
- RQ2: 有反馈指导的 SPINE 效果如何?
- RQ3: 有并行化加速的 SPINE 效率如何?
基础实验
从对比 SPINE-base 和五个 SOTA 日志解析器的解析精度实验(表1),以及解析运行时间的对比结果(图 7)中可见,SPINE 的效果优于或不逊于 SOTA 方法。另外,在没有并行加速优化的情况下,SPINE 的解析效率也可以达到领先水平。

表1:解析精度对比结果
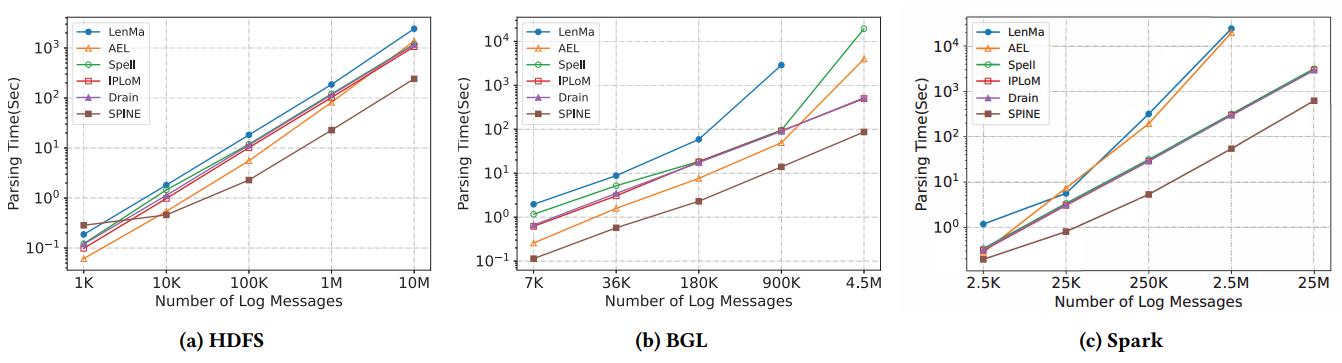
图7:解析运行时间对比结果
用户反馈实验
研究员们将 SPINE-feedback 版本应用于三个日志数据集,即 Linux、Mac 和 OpenStack 后,如表1中所示。注意,在这三个数据集上,原有的日志解析器的解析精度都很不理想。为此,研究员们首先为每个数据集训练了一个初始解析模型,随后查询了具有最高饱和度增益的日志簇的用户反馈。
为了显示 SPINE 反馈机制的有效性,实验中研究员们使用了两个基线推荐策略。第一个基线是一个随机策略(表示为 random),即随机地从任意一个日志簇中抽出一对日志推荐给用户标注。第二条基线表示为 LNS,即仅仅考虑叶子节点的大小进行推荐。实验结果如图8所示。随着反馈次数的增加,以上策略都可以在 SPINE 模型架构上提高解析的准确性。与其它两个基线相比,SPINE-feedback 取得了最高的准确度提升。例如,Linux 和 OpenStack 日志数据集上的解析准确率可以在不到10次的用户反馈后提高到0. 90以上。即使是在非常复杂的 Mac 日志数据集上,解析准确率也可以从0.78提高到0.85以上,而这仅仅需要20次用户反馈即可。
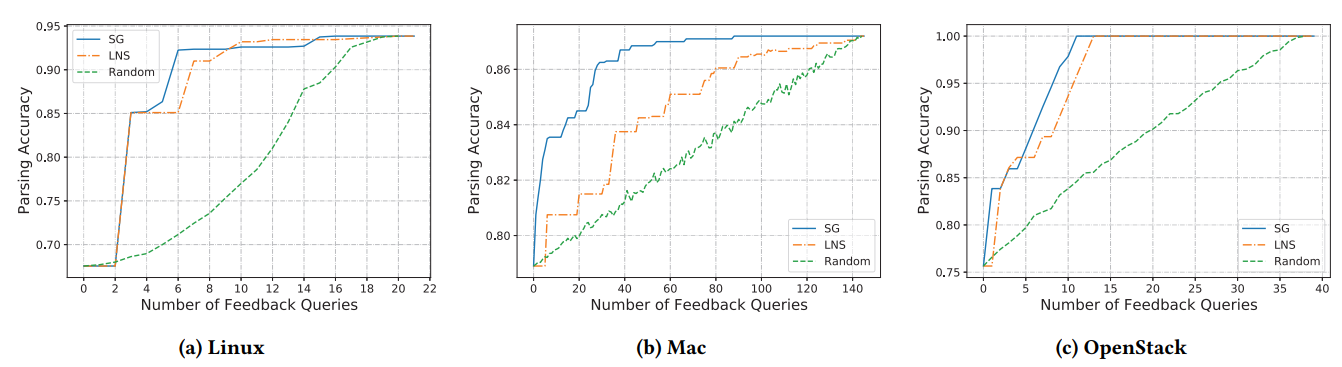
图8:用户反馈实验结果
并行化实验
在三个最大的数据集——HDFS、BGL 和 Spark 上,研究员们评估了日志数据调度方法的有效性。研究员们在不同数量的计算单元下运行 SPINE-parallel,并记录了其吞吐量(每秒处理的日志数量)变化,其结果如图9所示。
SPINE 日志调度方法可以显著提高解析的效率。例如,SPINE-parallel 在 BGL 数据集上可以实现5倍左右的吞吐量提升,大约每秒处理225,000条日志。对比简单的 BestFit 方法,SPINE 的日志数据调度算法可以更充分地利用更多的计算单元,以到达更高的效率。

图9:并行加速实验结果
参考文献
[1] Towards automated log parsing for large-scale log data analysis.
[2] Onion: identifying incident-indicating logs for cloud systems.
[3] Public datasets for log parsing. https://github.com/logpai/logparser
[4] Tools and benchmarks for automated log parsing






