
WWW 2022 | 一文解读互联网技术国际顶会最新方向
2022-04-19 | 作者:微软亚洲研究院
编者按:国际万维网会议(Proceedings of the ACM Web Conference,简称 WWW)是互联网技术领域最重要的国际会议之一。今年的 WWW 将于4月25-29日在法国里昂以线上会议的形式召开。本届会议共收到了1822篇长文投稿,论文录用率为17.7%,微软亚洲研究院也有多篇论文入选。今天我们为大家精选了其中的六篇进行简要介绍,研究主题关键词包括个性化新闻推荐、图异配性建模、多层推荐推理、日志解析、基于因果学习的可解释推荐、增量推荐算法等,欢迎感兴趣的读者阅读论文原文,一起了解互联网技术领域的前沿进展!
基于多元用户反馈的新闻信息流推荐

论文链接:https://arxiv.org/abs/2102.04903
用户兴趣的准确建模是个性化新闻推荐的核心。大部分已有的新闻推荐方法都依赖于用户点击等隐式反馈来推断用户的兴趣和训练推荐模型。然而用户的点击行为往往十分嘈杂,并且难以反映用户对新闻内容的真实喜好。同时,仅仅优化点击率的推荐模型也难以有效优化用户黏性等指标。
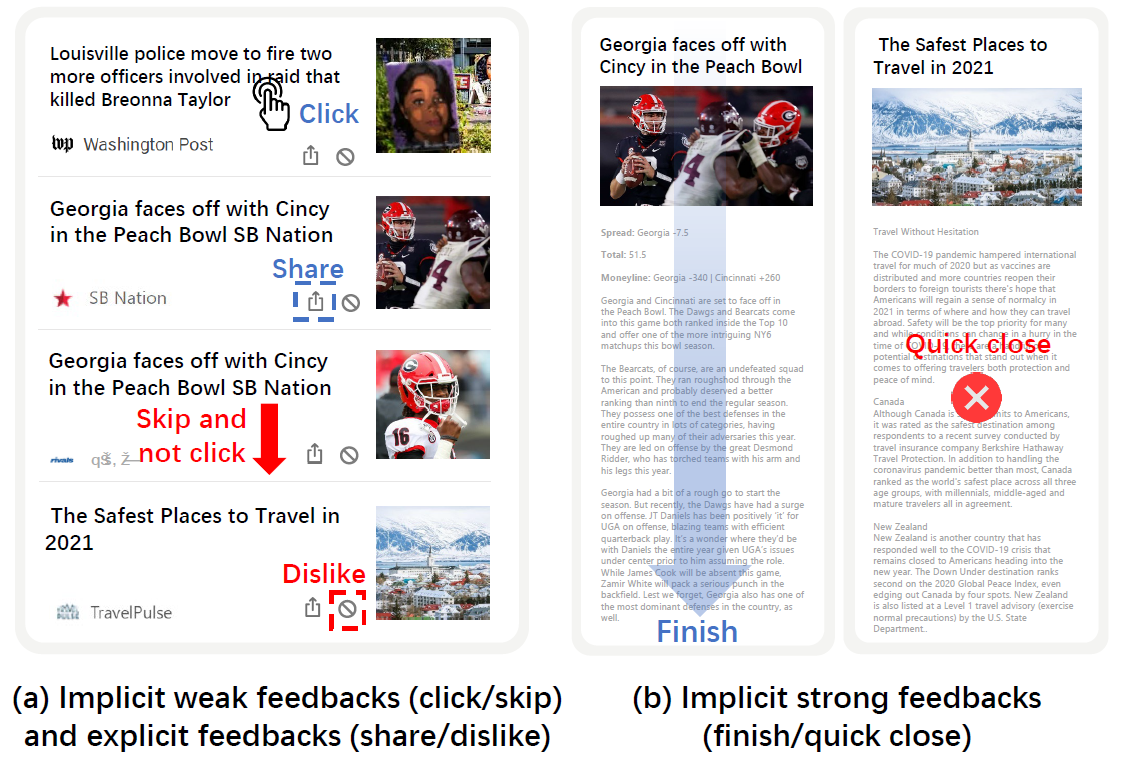
图1:在新闻平台上不同类型的用户反馈示例
其实,在新闻平台上通常存在多样化的用户反馈,如图1所示。除了用户的点击与跳过等较弱的隐式反馈以外,还存在如分享和不喜欢等显式反馈与完成阅读或快速关闭等较强的隐式反馈。这些多样的用户反馈可以为推测用户兴趣提供更为全面的信息。
为了准确、有效地利用新闻平台上丰富的用户反馈,微软亚洲研究院的研究员们提出了一种基于多用户反馈的新闻推荐方法 FeedRec。图2展示了 FeedRec 中基于异构用户反馈的兴趣建模框架。研究员们分别利用同构和异构的 Transformer 来建模同类型与跨类型用户反馈之间的联系,并且提出了一种从强到弱的注意力机制,利用强反馈指导弱反馈的选择,从嘈杂的用户反馈中蒸馏出准确的正负反馈信号。对于得到的弱正反馈与弱负反馈,研究员们还利用了一个正则损失使得二者能被更好地区分。
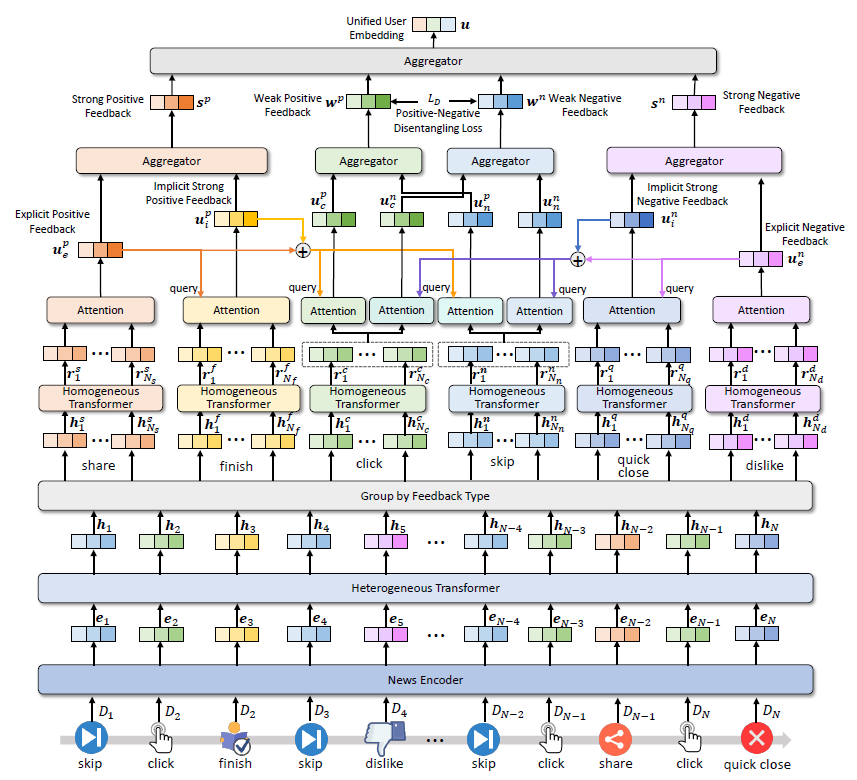
图2:FeedRec 的用户兴趣建模框架
而为了实现更为全面充分的模型优化,研究员们还提出了一种基于多用户反馈的多目标训练方法,如图3所示。研究员们通过联合预测点击率、阅读完成率与停留时间,让模型不仅优化点击率,还能同时优化多种用户黏性指标。
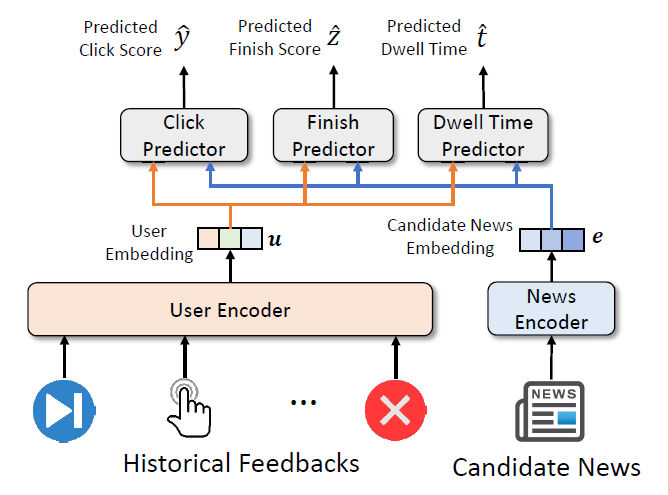
图3:FeedRec 的多任务模型训练框架
研究员们在一个从新闻 App 中收集的数据集上开展了实验。表1的结果显示 FeedRec 可以有效地提升多种点击率指标。表2进一步显示 FeedRec 可以提升多方面的用户黏性,更可能为用户推荐喜爱的新闻内容,改善用户的新闻阅读体验。
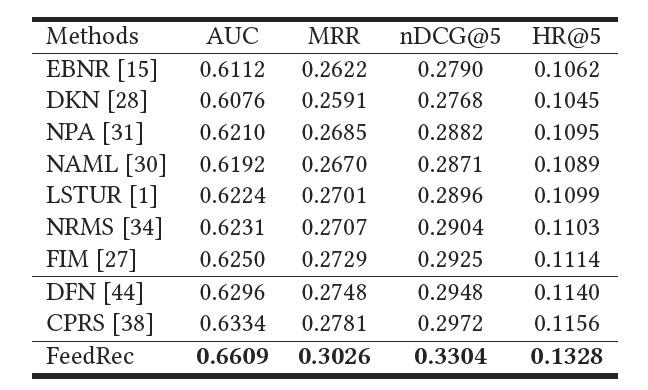
表1:不同方法的点击预测性能比较
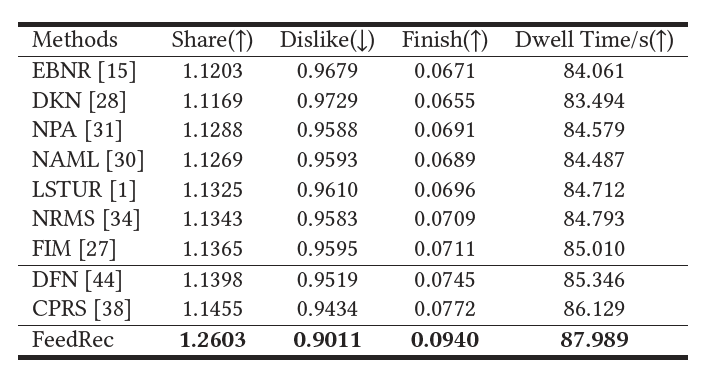
表2:不同方法的用户黏性比较。“↑”代表数值越高性能越好,“↓”代表数值越低性能越好
针对图同配性和异配性同时建模的双核图网络模型

论文链接:https://arxiv.org/abs/2110.15777
图神经网络 (GNN) 由于其强大的图表征能力,被广泛应用于基于图数据的机器学习问题中。对于节点级别的任务,GNN 已被广泛证明有着很强的建模同配(Homophily)图的能力,然而它们建模图异配性(Heterophily)的能力则相对较弱。这一定程度上是因为对同一阶邻居的向量表征,使用了相同的核做变换所致,即使使用类似于图注意力网络(GAT)这样的注意力机制,但由于注意力计算的权重总是一个正值,一个核也无法同时对节点表征之间的相似性和相异性(如正负相关性)进行建模。
针对这个问题,微软亚洲研究院的研究员们通过实证分析发现,无论是在被普遍认为是同配图的数据集还是异配图的数据集上,都存在着相当数量的异配子图,且子图的异配度参差不齐,而传统模型如 GCN 在同配子图上往往表现优异,但在异配子图上发挥较差,这充分说明了能同时建模同配和异配性模型的必要性。研究员们通过理论分析了 GCN 不能有效建模混合了同配和异配性的图的原因,并进一步提出了一种基于双核特征转换和门(Gate)机制的新型 GNN 模型: GBK-GNN。GBK-GNN 的结构如图4所示,其通过两个不同的核分别捕获同质和异质信息,并引入门来进行核的选择。这种方式能避免特征变换后的聚合操作将可区分的特征平滑化,从而能够提高模型对同质性及异质性的建模能力。
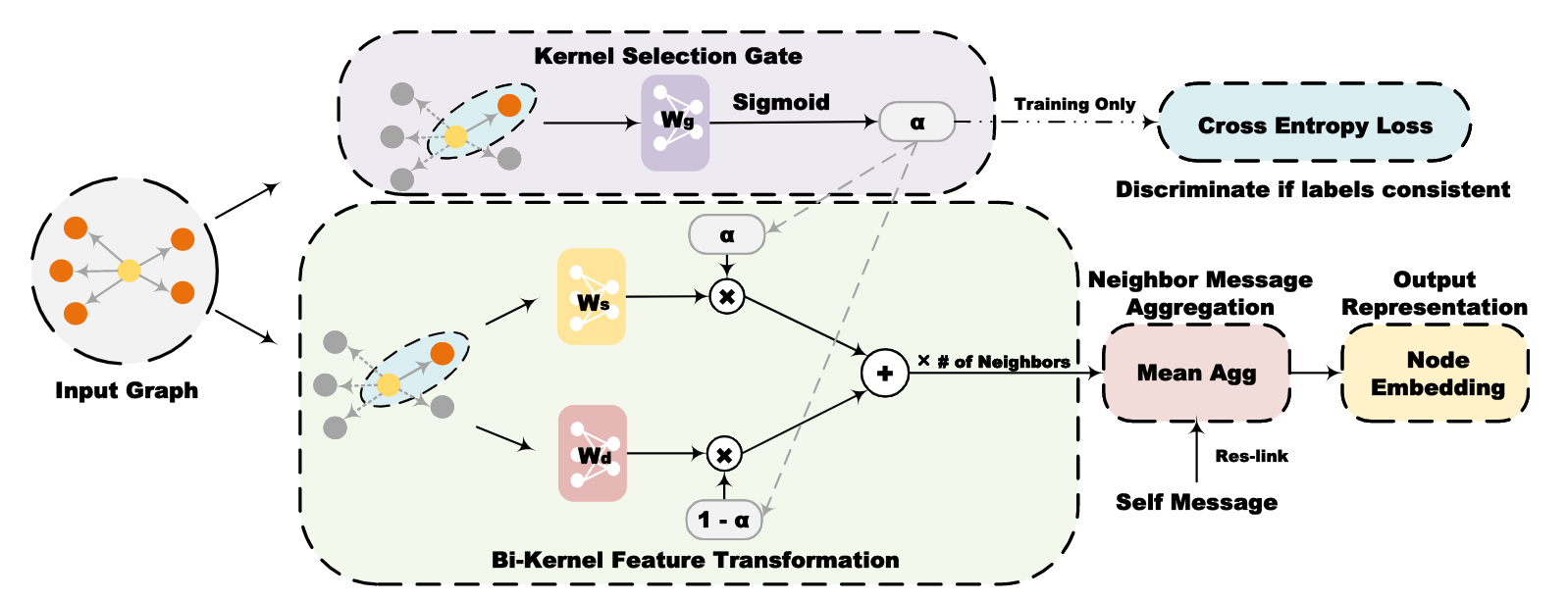
图4:GBK-GNN 模型结构图
研究员们在具有不同同质异质特性的七个真实数据集上进行了广泛的实验。实验结果表明,与其他 SOTA 方法相比,GBK-GNN 有稳定且显著的提升。表3显示了不同模型在各个数据集上的分类准确率。
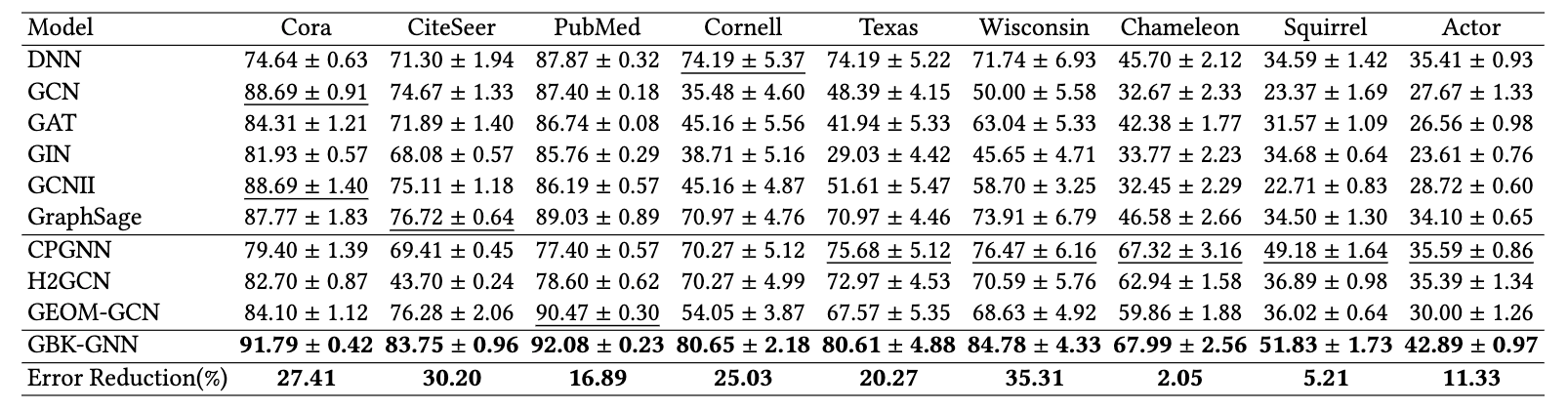
表3:不同数据集上节点分类问题的准确度对比
基于知识图谱的多层推荐推理——从碎片化推荐到高屋建瓴的人类推理

论文链接:https://www.microsoft.com/en-us/research/uploads/prod/2022/03/WWW2022_Multi_level_Reasoning_submission_camera_ready.pdf
知识图谱被广泛应用在推荐、问答等各个领域。一方面,知识图谱中补充的额外信息可以帮助模型更好地做出决策,提高准确性,另一方面,知识图谱上的路径可以提供模型的全部推理步骤,极具解释性。比如推荐模型的一个推理过程可以表示成如下的路径:
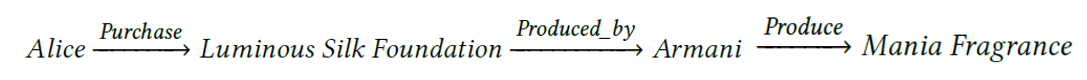
这条路径指出,用户 Alice 购买了由 Armani 生产的 Luminous Silk Foundation,因此模型推荐了同为 Armani 生产的 Mania Fragrance 给这位用户。
这种推理过程往往是在实体层知识图谱上进行的(instance-view KG)。如图5所示,实体层知识图谱只含有具体的实体及它们之间的关系(例如 Armani 生产了 Mania Fragrance),并不知道实体之间的高层关联(例如 Armani 和 Prada 都是意大利奢侈品牌)。因此在实体层的推理往往是碎片化的,不能综合用户的多种行为高屋建瓴地分析、推理。这就与分析时陷入细节、抓不住重点很类似。人类更智慧的推理过程往往是高屋建瓴,自顶而下,逐步考虑更多细节的。比如判断一个用户兴趣时,会先总结出 Alice 更喜欢化妆品,而不是球鞋,进而分析 Alice 可能喜欢的具体是属于意大利奢侈品牌的化妆品,从而进行一系列准确推荐。如果模型能借鉴这种高屋建瓴的能力,不仅可以让模型更快收敛到更好的结果,还可以提供令人信服的、概括用户更多行为的解释。
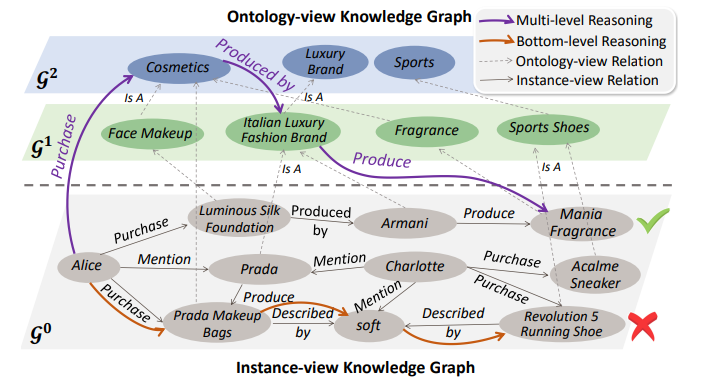
图5:现有方法进行的是底层推理(红线),这种碎片化的推理方式往往只考虑了一个线索(比如 Alice 购买过 Prada Makeup Bags),很容易陷入细节、抓不住重点。与此相比,多层推理(紫线)可以综合用户的多个行为进行高屋建瓴的推理(比如 Alice 购买过、提过的物品往往是意大利奢侈品牌或它们生产的化妆品),不仅可以让模型收敛到更好的结果,还为表示用户的真实兴趣(意大利奢侈品牌)提供了可能,往往能给出更令人信服的解释。
基于这种发现,微软亚洲研究院的研究员们提出了将实体层知识图谱和概念知识图谱(ontology-view KG)相结合的方法,从而进行多层推理。如图5所示,推理路径上的一个点可以是在任何一个层级,而不是只在底层。因此可以给出更好概括用户所有行为的一个推理路径:
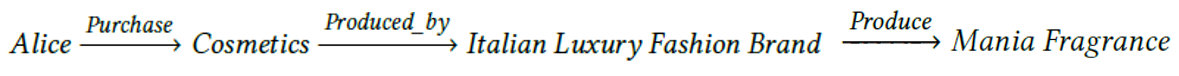
研究员们认为,推理的过程天然就是多层级的,不管在推荐上,还是其他任务(比如问答)上,所以多层级的推理极具研究和应用价值。为此,研究员们提出了一个基于 Abstract MDP 的强化学习框架,并且证明了该方法可以显著提升推荐效果及可解释性。
针对异构日志数据的统一日志解析

论文链接:https://arxiv.org/abs/2202.06569
在大规模的线上服务系统中,程序日志为工程师提供了故障诊断的第一手资料。日志解析(log parsing)技术将半结构化的原始日志转化成结构化数据,为后续的日志自动诊断步骤提供了结构化的日志输入。已有的日志解析器都将日志中公共(common)的部分识别为模板(template), 变化(dynamic)的部分识别为参数(parameter)。然而,这些日志解析器通常忽略了日志中包含的语义信息。另一方面,不同日志源(log source)之间日志结构差异较大,使得现有的日志解析器很难同时精确解析来自不同系统的日志。
在本篇论文中,微软亚洲研究院的研究员们提出了 UniParser,用于捕获异构日志间的相似部分。Uniparser 利用 Token Encoder module 和 Context Encoder module 来学习日志单词(token)及单词上下文(context)的范式。Context Similarity module 用来表征日志范式的相似之处。研究员们在16个公开的日志数据集上进行了对比实验,UniParser 的精度大幅度超越了其他日志解析器。
UniParser 的结构如图6所示:
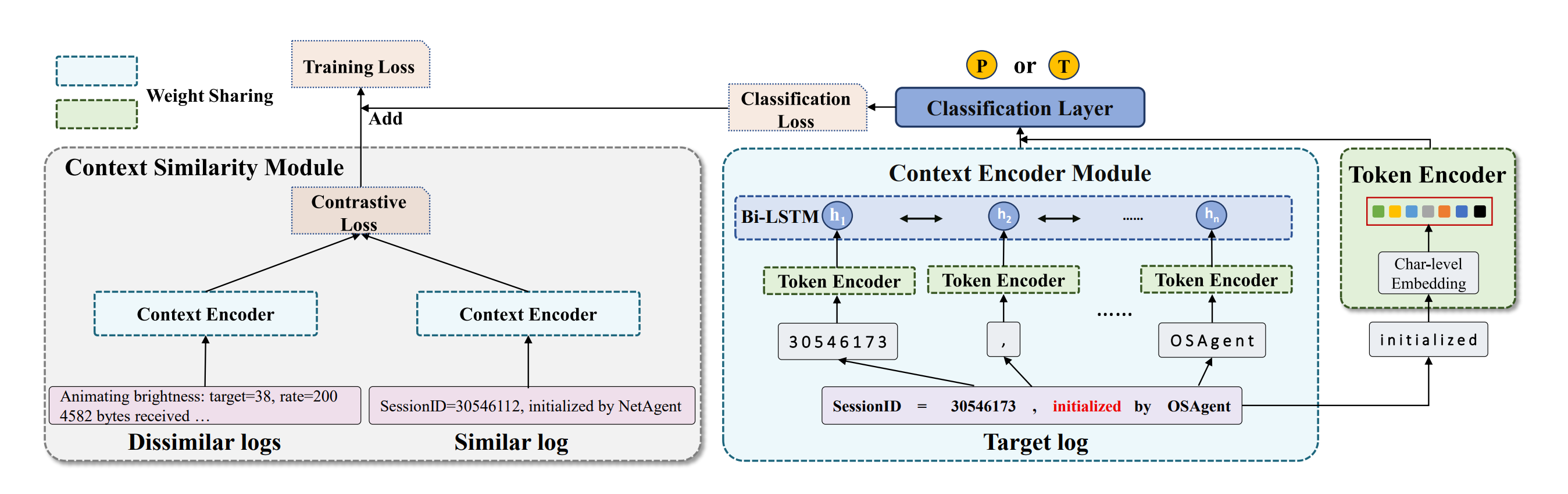
图6:UniParser 结构图,包含 Token Encoder Module,Context Encoder Module,Context Similarity Module
实验结果,如表4所示:
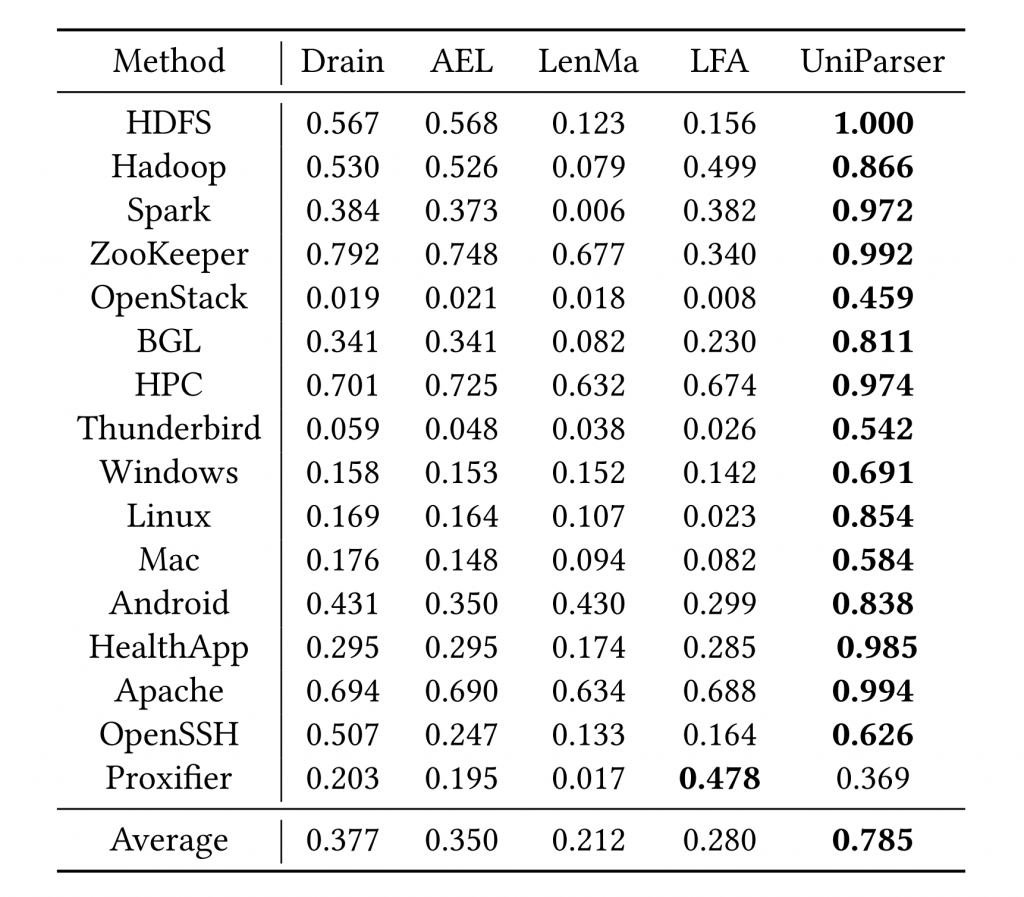
表4:UniParser 和其他日志解析器的比较
基于评论合理化的准确与可解释推荐算法

论文链接:http://recmind.cn/papers/r3_www22.pdf
为了提升推荐算法的精度和解释能力,推荐系统引入了诸如评论或图片等额外数据进行信息补充,通过自然语言处理、计算机视觉等技术对评论文本、商品图片进行多模态学习,还设计了相应的协同过滤算法给出基于相关关系的推荐和解释。然而,基于相关性建模设计的算法存在建模假性相关关系的隐患,建模了假性相关的模型在泛化能力以及解释能力上相对而言难以赢得用户的信任。
本文所提出的 R3(Recommendation via Review Rationalization)是一个期望从评论中剔除假性相关特征的模型,由因果特征挖掘模块、因果特征预测模块以及关联特征预测模块三个模块组成。其中,因果特征挖掘模块用以从评论特征全集中挖掘因果特征以减小假性关联特征的干扰;因果特征预测模块仅基于因果特征挖掘模块挖掘到的因果特征进行推荐预测;关联特征预测模块则同时基于因果特征和其余关联特征进行预测来验证原因特征挖掘模块挖掘到的因果特征是否能使其余关联特征与预测结果条件独立。通过在不同分布的数据集上的大量实验表明,R3 挖掘到的因果特征在保持高准确性推荐结果的同时也具有较高的泛化能力和解释能力。
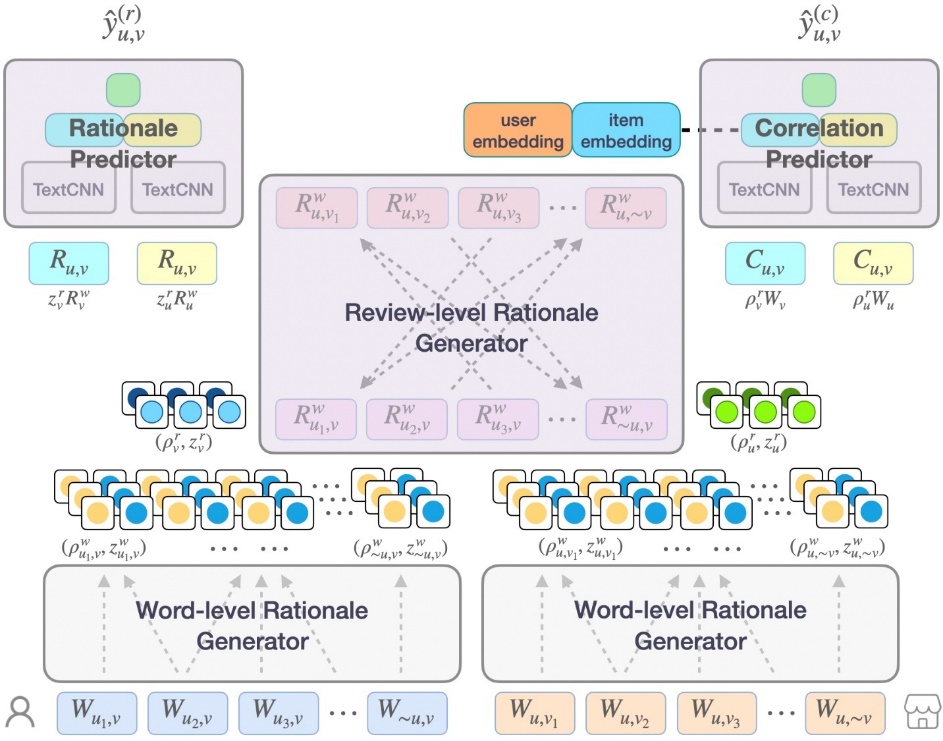
图7:R3 模型示意图
基于图信号处理的快速增量推荐算法

论文链接:http://recmind.cn/papers/fire_www22.pdf
在推荐系统中,随着新用户、新物品以及用户和物品新交互数据的不断产生,推荐算法不能仅靠重新训练模型来应对新数据出现的问题,而是应该基于最近训练好的的模型以增量更新的形式来处理新数据。现阶段,图神经网络已成为捕捉用户特征进而提高推荐准确性的强有力工具之一。然而,目前基于图神经网络的增量推荐算法普遍存在两大问题:首先,大量可训练参数的引入导致训练时间过长,在一定程度上影响了推荐的效率;其次,由于这些算法都是基于用户交互数据来捕捉用户特征的,因此无法处理新用户或新物品出现时的冷启动问题。
本文提出的 FIRE 是一个无参数的模型,不需要非常耗时的训练过程,因此在模型更新阶段具有非常高的效率。此外,借助图信号处理技术,研究员们还为 FIRE 设计了两个低通滤波器:时间信息滤波器和辅助信息滤波器,用于提升推荐结果的准确性。时间信息滤波器通过对用户交互数据进行指数衰减,用来捕捉用户随时间变化的偏好,而辅助信息滤波器则将辅助信息(如用户特征、物品属性)建模为用户或物品间的相似度信息,用于剔除存在于推荐结果的异常信息。这两个滤波器都实现了过滤用户交互信号中的高频分量保留低频分量的效果,使得用户交互信号更加平滑,从而保证推荐内容的准确和可靠。实验证明,FIRE 在保持高准确性推荐结果的同时,有着非常高的训练效率。
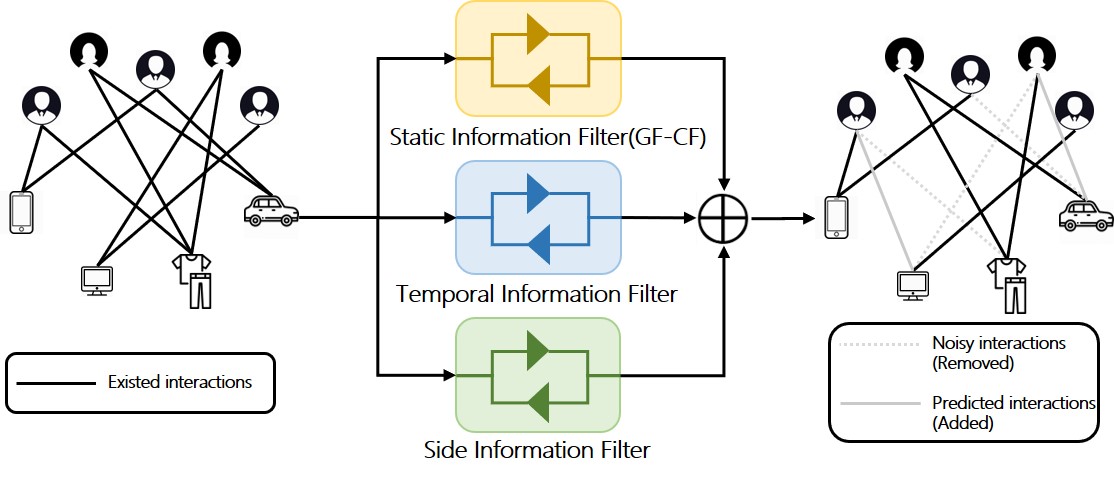
图8:FIRE 模型示意图






