
WWW 2023 | 一键追更互联网技术国际顶会的最新科研进展!
2023-04-12 | 作者:微软亚洲研究院
编者按:国际万维网会议(Proceedings of the ACM Web Conference,简称 WWW)是互联网技术领域的顶级学术会议之一。WWW 大会汇集了国际一流学者与产业界精英,持续关注着互联网技术的学术研究前沿与热门发展方向。在今年的 WWW 2023 大会上,有多篇来自微软亚洲研究院的论文被录用。今天我们精选了其中的六篇进行简要介绍,研究主题涵盖算法公平、知识蒸馏、推荐系统与图自监督学习等。欢迎点击每篇文章下的链接,阅读论文原文,一键追更互联网技术研究的最新进展!
DualFair:群体和个体层面双重公平的表示学习

论文链接:https://arxiv.org/abs/2303.08403
代码链接:https://github.com/Sungwon-Han/DualFair
算法公平已成为重要的机器学习问题,特别是任务关键型 Web 应用程序中的关键问题。微软亚洲研究院的研究员们创新性地提出了可以消除如性别和种族等表征的敏感属性偏见的自监督模型 DualFair。与仅针对单一类型的现有模型不同,DualFair 针对两个公平性标准进行了联合优化——群体公平性和反事实公平性。因此,无论是群组还是个体层面,通过 DualFair 都可以得到更加公平的预测。
研究员们在自监督的学习方法 DualFair 中设计了两个特殊损失,能够在保证群体性与反事实公平性的同时保证高质量表征。第一个损失是公平对比损失,对处于反事实关系中的个体一视同仁(即反事实公平性),并确保敏感属性表征不可区分(即群体公平性)。在给定数据集 D 的一个块 B_s 上,其敏感属性为 S。通过采样器过滤输入 x^s 的敏感属性(s∈S),产生一个反事实版本的 x_cnt^(s^')。公平对比损失需要在原输入和生成的反事实版本上最大化,以确保反事实公平,在相同属性的输入之间最小化,以确保群组公平。第二个损失是自蒸馏损失,从实例中抽取语义信息并保证下游任务表现。研究员们强制要求来自学生分支的扰动实例表征要类似于来自教师分支的原始实例表征。依据的基本原理是:对原始内容影响较小的扰动,不应该改变学习得到的表示。为此,研究员们创新推出了扰动模块 TabMix,能够实现高效的自知识蒸馏。实验证明,DualFair 保持了高质量表示的同时,为敏感属性生成了公平的表征。消融研究进一步显示了两种公平标准的协同效应。
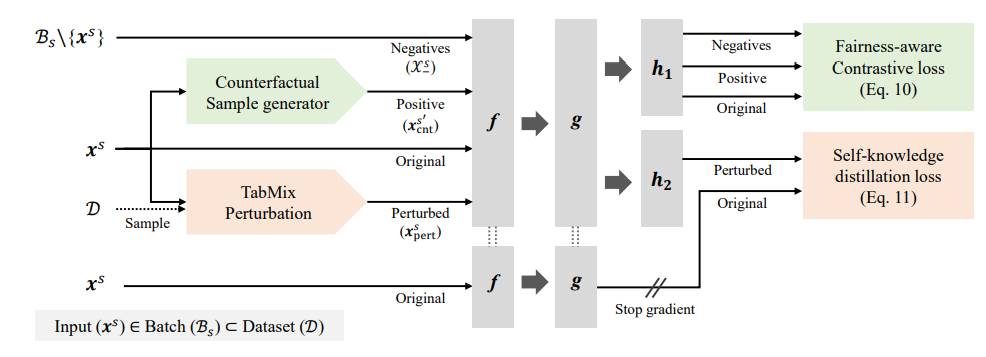
图1:DualFair 的整体框架。f,g,(h_1,h_2) 分别代表网络主体,隐射模块和两个预测模块。DualFair 通过联合优化公平的对比损失和自知识蒸馏损失,致力于保证表示学习的公平性和质量。
从多个异构推荐模型中进行知识蒸馏的方法

论文链接:https://www.microsoft.com/en-us/research/uploads/prod/2023/03/HetComp-CR.pdf
推荐系统可以通过集成多个异构模型来进一步提高准确度。然而,集成多个模型会使得线上推理的时间与模型数量成比例增加,因此带来昂贵的开销。本文旨在探索如何有效地使用知识蒸馏的方法,将多个异构模型的知识转移到单个轻量级模型,在保持高精度的同时降低推理成本。
经过一些预备实验的观察,研究员们发现以传统的方式从异构模型蒸馏知识时,蒸馏的有效性会严重下降。但同时,从教师模型的训练轨迹中可以获得缓解蒸馏困难的重要信号。因此,研究员们提出了一种改善蒸馏效果的思路:使用教师模型的训练轨迹,根据从易到难的顺序动态地蒸馏知识,进而将其提炼为 HetComp(面向推荐系统的异构模型压缩)框架。
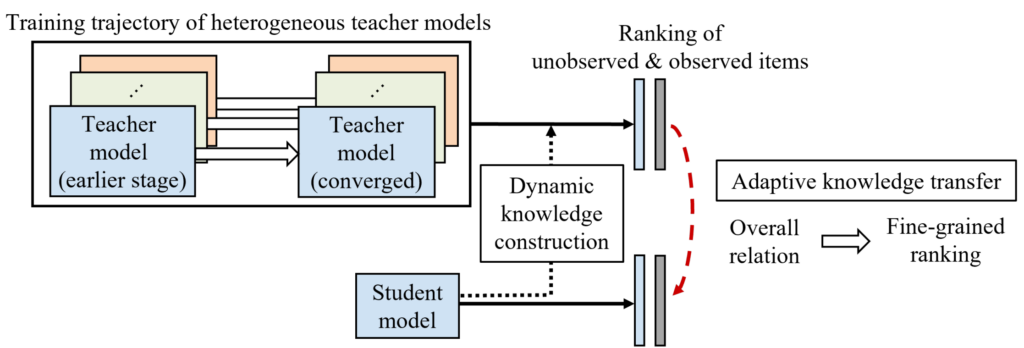
图2:HetComp 的训练框架总览图
具体而言, HetComp 构建了一个动态知识库。这个知识库根据学生模型的学习状态,从每个教师的轨迹中找出适当的知识,并组成一组从易到难的教师信号排列帮助训练学生模型。在训练过程中,HetComp 使用自适应知识转移的方式,根据学生的学习状态调整蒸馏目标。HetComp 会让学生模型首先复制教师模型的整体预测关系,再逐步学习其中的细粒度排序顺序。此外,HetComp 还利用了未观察到的用户-物品来帮助知识蒸馏,缓解伪正例的影响。
在 Amazon、CiteULike 和 Foursquare 三个公开数据集上进行的大量实验结果证明了 HetComp 能够有效地将集成模型的能力蒸馏到单模型上。同时,研究员们还深入分析了教师的训练轨迹有助于物品推荐的原因。
ECF:基于聚类的可解释协同过滤

论文链接:https://www.microsoft.com/en-us/research/uploads/prod/2023/03/ecf-CR.pdf
提高推荐模型的可解释性有助于增强推荐结果的说服力,提升用户满意度,从而提高点击率和用户转化率。而作为一种广泛使用且有效的基础推荐技术,协同过滤(Collaborative Filtering)的实现,例如矩阵分解(MF)或者基于深度学习的嵌入表示模型(LightGCN),往往是不可解释的。本着一个可解释推荐模型应该满足灵活性、一致性和自洽性的条件,本文提出了一个简单且有效的可解释性协同过滤框架:ECF(Explainable Colaborative Filtering)。
ECF 旨在从用户的群体行为中挖掘出一些可解读的兴趣簇(Taste Clusters),使得处在同一个兴趣簇的物品同时满足两个条件:(1)物品之间共享一些内容标签;(2)这些物品会被一组有相似兴趣的用户喜欢。并通过学习用户/物品到兴趣簇的稀疏映射,进而利用兴趣簇的标签及用户-兴趣簇-物品的路径实现可解释推荐。
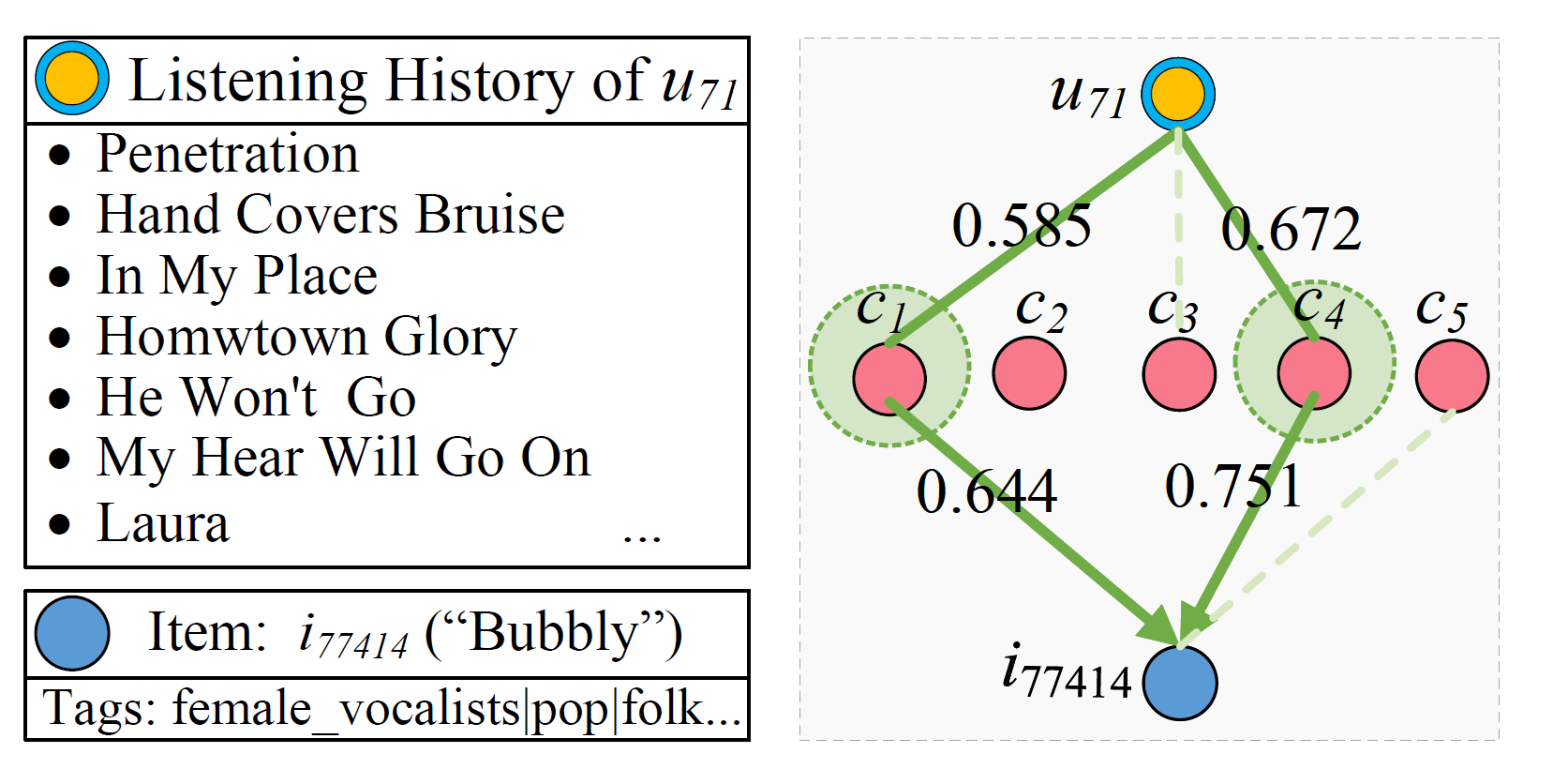
图3:在音乐推荐场景下的 ECF 模型示意图(黄色为用户节点,蓝色为音乐节点,红色为兴趣簇节点)
为了得到高质量的兴趣簇,研究员们从语义相似性、标签相似性及独立性三个方面设计了不同的损失函数以对模型进行端到端的优化,并利用辅助的协同信号进一步提高模型的收敛速度。同时,他们还设计了一系列新的可解释性评价指标及用户实验用于对比不同基于聚类的可解释性模型。
多个数据集上的实验表明,ECF 不仅能增强协同过滤算法的可解释性,同时也能达到相当高的推荐精度。ECF 有着广泛的应用场景,例如用户标签生成、可解释召回、带有主题的相似物品列表推荐、定向广告中的相似人群模型等。目前 ECF 已经被应用于微软 Xbox GamePass 游戏推荐场景中。
xGCN:一种基于图卷积网络的超大规模图嵌入模型

论文链接:https://www.microsoft.com/en-us/research/uploads/prod/2023/03/xgcn-CR.pdf
项目代码:https://xgcn.readthedocs.io/en/latest/index.html
近年来,图神经网络(GNN)因其强大的结构表达能力被广泛应用于各种图相关的学习任务中。图嵌入表示是一种经典的应用范式:通过模型训练,把图上的每个节点表示成一个低维的向量;推理时,使用低维向量辅助下游任务,例如节点分类、链路预测等。然而,现有的 GNN 在学习大规模网络嵌入时,仍存在诸多缺陷,主要包括:(1)多跳信息传播带来的过平滑与可拓展性问题;(2)每个节点 ID 都对应一个可学习的向量,导致模型整体的参数量过高,难以支持大规模训练;(3)GNN 卷积层参数和节点 ID 嵌入向量表有着不同的性质:GNN 卷积层参数属于稠密参数,更新频率快;而节点 ID 形成的 Embedding Table 属于稀疏参数,更新频率慢。传统端到端的梯度优化会导致次优的结果。
为了克服这些问题,本文提出了一种不同于传统端到端全梯度训练方式的新型 GNN 模型:xGCN。相比于需要梯度训练的参数,xGCN 将节点 ID 嵌入向量表示为静态特征,并使用无监督的传播过程和一个由 MLP 构成的“提炼网络”(Refinement Network,RefNet)来持续迭代地更新嵌入向量。xGCN 能够显著减少模型参数数量、加速模型训练,同时提升预测准确率。
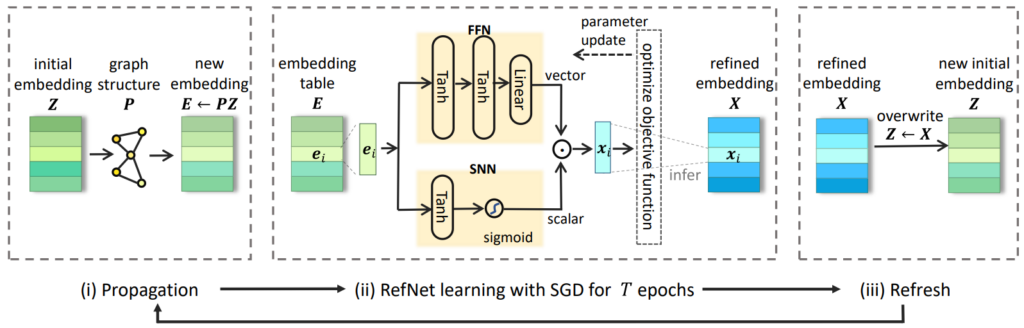
图4:xGCN 的模型框架图(迭代过程包含三个部分:传播、提炼和刷新)
研究员们在四个大规模社交网络数据集上进行了链路预测实验,结果表明,xGCN 在准确率和训练速度方面均超过了现有的基线模型。其中,在有着一亿个用户节点的真实 Xbox 游戏社交网络数据集上,xGCN 在小于 100GB 内存的单机环境内,不到11个小时即完成了训练,并且其效果优于一些需要近 500GB 内存、训练时长超过3天的基线模型。xGCN 目前已落地微软 Xbox 社交推荐的应用场景。
基于个性化图信号处理的协同过滤

论文链接:https://arxiv.org/abs/2302.02113
协同过滤是推荐系统中最流行的技术之一,它通过用户与商品的交互历史来预测用户与其他商品交互的可能性。现有的基于图信号处理的协同过滤方法依赖于两个假设:一,用户的个性化偏好完全由其交互历史来表征;二,交互信号中的低频信息足以预测用户偏好。然而,由于推荐系统存在数据稀疏问题,稀疏的历史交互可能不足以准确描述用户偏好。此外,只使用包含用户一般兴趣的低频信息,可能会忽略包含用户个性化兴趣的高频信息。
为了更准确地描述用户,微软亚洲研究院的研究员和合作者提出了“个性化图信号”概念。“个性化图信号”将描述用户的方式从仅使用用户的交互信息升级为同时使用用户-物品之间的相似度信息和用户-用户之间的相似度信息。研究员们还构造了囊括物品-物品、用户-物品、用户-用户之间相似度信息的增广相似度图,以便更有效地利用“个性化图信号”。此外,每个用户的真实偏好由反映一般用户偏好的全局平滑信号和反映个性化用户偏好的局部平滑信号组成。为了获得这两种信号,研究员们提出了一种混合频率图滤波器,可以将对信号进行全局平滑的理想低通滤波器和对信号进行局部平滑的线性低通滤波器组合。个性化图信号、增广相似图和混频图滤波器协同发力,使得推荐系统的准确性有所提升。
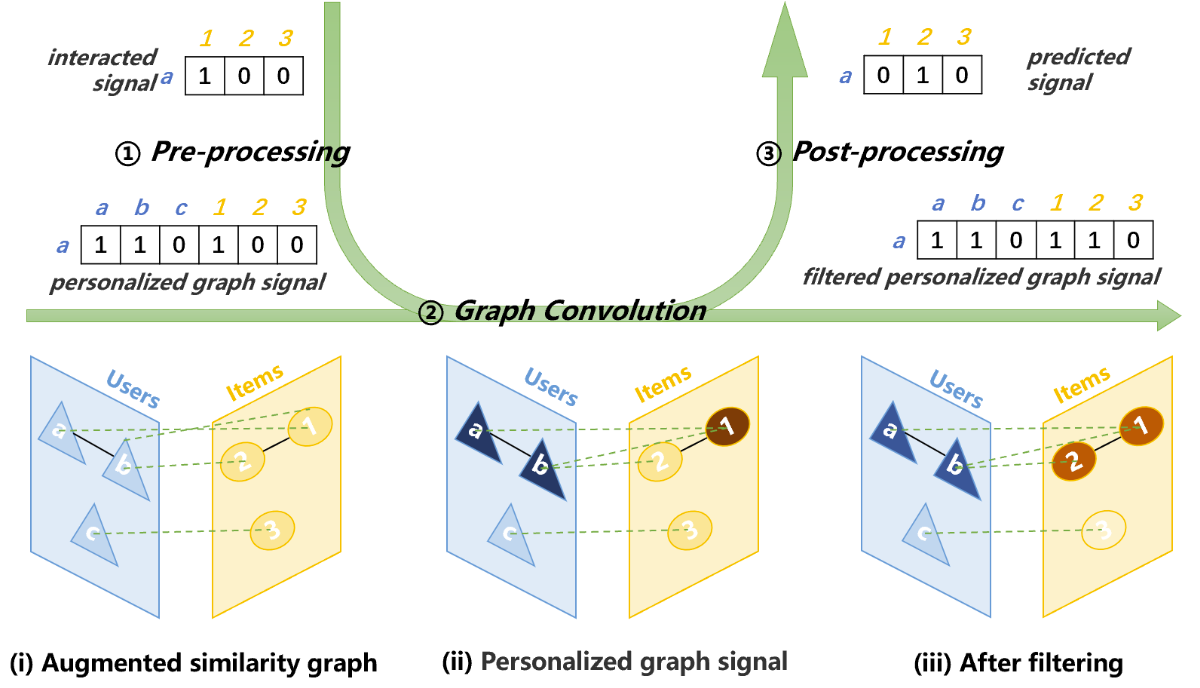
图5:PGSP 模型架构
SeeGera: 自监督半隐式的图变分自编码器

论文链接:https://arxiv.org/pdf/2301.12458.pdf
目前的图自监督学习(SSL)主要使用图对比学习的方法学习节点表征,然而图对比学习中存在 K 值难以确定、模型容易坍塌等问题。因此,生成式图自监督学习被提出,旨在通过重建图数据以学习节点表示。但大多数现有方法仅关注无监督学习任务,在分类任务上和图对比学习进行比较的研究相对较少。为填补相关研究缺失,近期 GraphMAE 模型被提出,并在分类任务上表现超过了 SOTA 图对比学习方法。然而,该方法在无监督学习任务上表现未知。因此,亟需提出新的生成式图自监督学习模型,该模型能够同时适用于下游无监督和有监督学习任务。
本文提出了 SeeGera 模型,可全面提高生成式图自监督学习在无监督与有监督学习任务中的性能。SeeGera 模型基于自监督变分图自编码器(VGAE),采用层次化的半隐式变分推理框架。一方面,SeeGera 在编码器中同时嵌入节点信息和节点特征信息,并在解码器中重构图的拓扑链接和节点特征。另一方面,SeeGera 在分层变分框架中添加了一个额外的结构——特征掩蔽层,提高了模型的泛化能力。大量的实验表明,SeeGera 能够在下游多个无监督和有监督学习任务中表现出色。
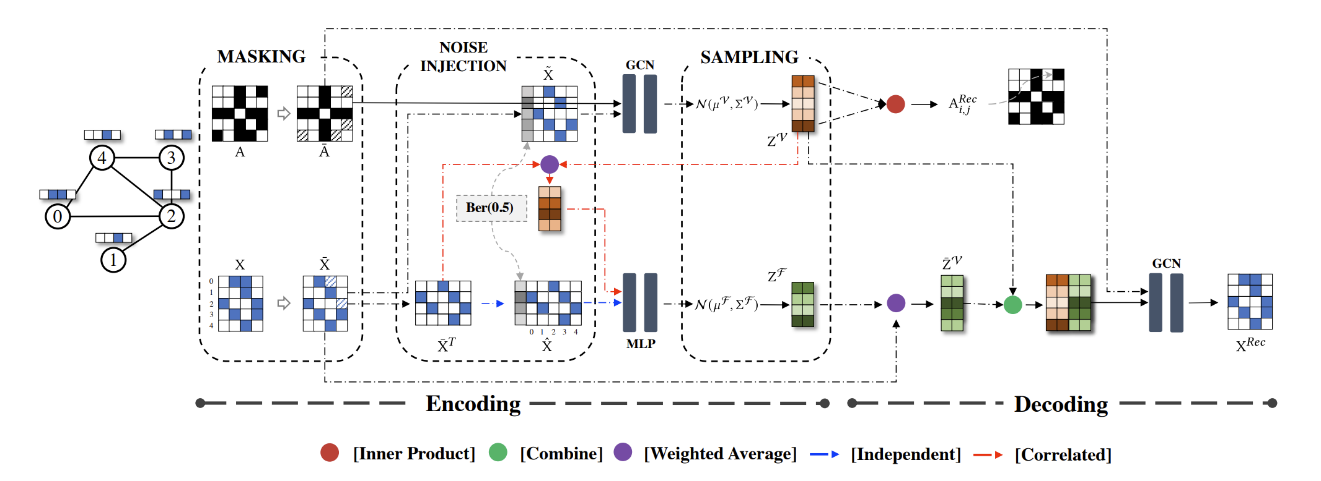
图6:SeeGera 模型框架






