
胡瀚:成功用Swin Transformer连接CV和NLP主流架构的“破壁人”
2023-04-19 | 作者:DeepTech深科技
编者按:计算机视觉和自然语言处理分别是计算机科学的重要研究方向,然而长久以来,两个领域遵循着截然不同的研究范式。在 Transformer 架构出现后,能否让其强大的通用性从自然语言处理拓展至计算机视觉的研究与应用中,打破两个领域间的“次元壁”成为了研究者们不断探索的问题。
微软亚洲研究院高级研究员胡瀚,成为了首个“破壁人”。他所提出的 Swin Transformer 促进了视觉 Transformer 取代长期统治视觉骨干网络的卷积神经网络,让计算机能够像理解语言一样看懂世界。凭借这一里程碑式的开创性成果,胡瀚作为“远见者”入选了2022年度《麻省理工科技评论》“35岁以下科技创新35人”中国榜单。
语言翻译、回答问题、生成文本……最近大热的 ChatGPT 可以被看作是大型语言模型的里程碑式进步,其展现出来的通用性和可靠性令人赞叹,可以说其基本上解决了自然语言处理领域的所有问题,也让人看到了实现通用人工智能的曙光。
这让计算机视觉领域的相关研究人员不禁设想,是否可以利用类似的方式来解决通用的视觉问题?如果能同样解决视觉问题,那将为现在强大的语言模型装上眼睛,让它能去更广阔的物理世界进行探索。
要想实现这一目标,一个重要的基础是视觉和语言在建模和学习上的统一。然而,长期以来,研究人员一般采用 Transformer 架构解决自然语言领域的问题,而采用卷积神经网络处理各种视觉任务。
由于 Transformer 具有很强的通用性,所以能否让 Transformer 在计算机视觉中得到应用,推动这两个领域甚至更广阔的人工智能应用朝着统一的方向发展,助力解决更为广泛的智能问题呢?
微软亚洲研究院研究员胡瀚,长期从事计算机视觉的研究工作,致力于推进计算机视觉与自然语言处理建模和学习的融合和统一。他所提出的 Swin Transformer [1],成为了推动视觉 Transformer 取代长期统治视觉骨干网络的卷积神经网络的一个里程碑工作。凭借这一开创性的成果,他成为2022年度《麻省理工科技评论》“35岁以下科技创新35人”中国入选者之一。

2022年度《麻省理工科技评论》“35岁以下科技创新35人”中国入选者胡瀚
提出 Swin Transformer,助推视觉 Transformer 的大规模研究
在清华大学自动化系读博期间,胡瀚就开始了对计算机视觉的研究。当时,他受到人类视觉机制的启发,尝试使用更全局系统的方式来解决视觉分割问题,并在视觉的基本原则方面有了一些掌握。
博士毕业后,他继续从事计算机视觉研究。在很早的时候,他就坚信要想实现更通用的人工智能,不同领域在建模方面的统一将是一个重要的基础。在2017年 Transformer 出现后不久,他就看好这一架构的强大通用性,并开始积极尝试将 Transformer 引入到视觉领域中。他早期的尝试包括基于 Transformer 实现学界首个端到端的物体检测器(2017年)[2],以及在2019年首次将 Transformer 用于视觉骨干建模[3],尽管效果不错,但这一神经网络遇到了实现效率问题而不太实用,也没有成为主流。
两年后,他于2021年提出的 Swin Transformer 解决了其中的效率难题,从而推进了这一网络在视觉领域走向实用。在这个工作中,他创造性地提出了“移位窗口”方法,该方法无需同时处理数以千计的局部窗口,可以将需要处理的窗口数量降低50倍,这大大提升了计算的并行性,在 GPU 上取得了3倍的速度提升。
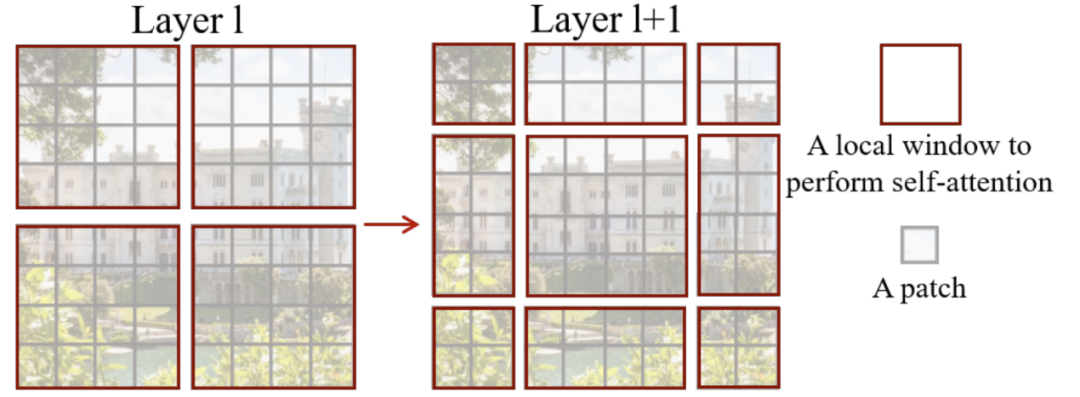
Swin Transformer 中的一个关键技术:移位窗口方法
胡瀚和团队首次证明了 Transformer 网络能够在非常广泛的视觉问题中大幅超越卷积神经网络,推动该领域大规模兴起了对视觉 Transformer 的研究。“当时我们很快做了开源,把一些实现细节分享给了整个领域。有了这个基础,其他研究者才能更快地去追随并开展进一步研究,进而共同推进该领域的发展。”他说。
作为项目负责人,他以《Swin Transformer:使用移位窗口的分层视觉 Transformer》(Swin Transformer: Hierarchical Vision Transformer using Shifted Windows)为题发布在预印本平台 arXiv[1]。
据悉,该成果获得了计算机视觉国际大会的最佳论文(马尔奖),这一奖项被视为国际计算机视觉领域的最高荣誉之一。同时,相关论文在一年多时间获得超过5000次引用和超过10000次 GitHub 标星。
目前,Swin Transformer 正作为骨干网络广泛地应用于计算机视觉领域,并为全球亿万人的工作和生活带来了很大的改变。比如,其已在微软产品 PowerPoint 的视觉素材推荐中获得应用,正在帮助用户制作更具美观性的设计和演示文稿。另外,其还被应用于图像搜索、元宇宙、自动驾驶和机器人等诸多领域。
与此同时,Swin Transformer 所代表的大一统趋势,有利于大大简化芯片设计,也有利于更通用的人工智能模型的开发。
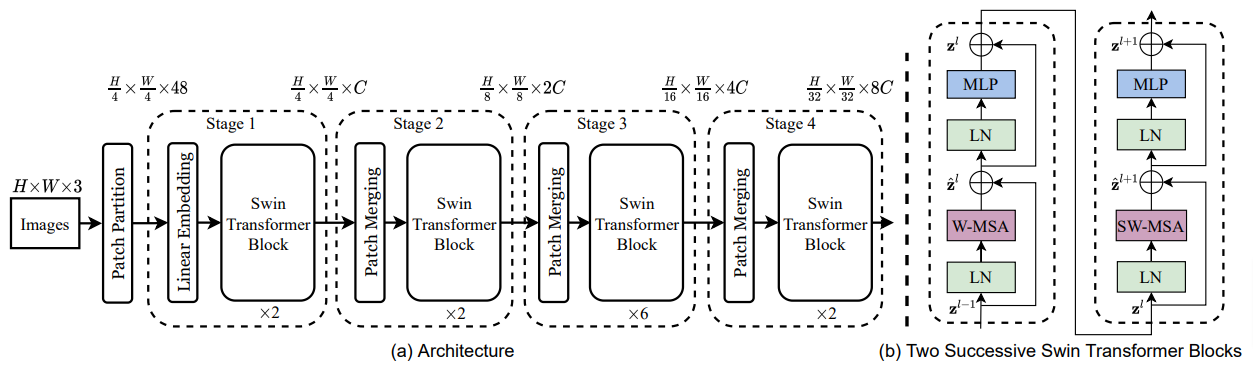
Swin Transformer
“Swin Transformer 所解决的计算机视觉长期与自然语言的主流架构不匹配的问题是一个更宏大目标中的第一步,即实现和人脑一样用一个通用模型和类似的学习机制去解决各种各样智能问题。”胡瀚表示,目前他正在继续攻克这个更宏大目标上的各种挑战,比如如何有效地扩展计算机视觉和多模态模型并将其稀疏化的问题。
人脑具有的强大智能,以及能从少量样本中学习新智能的能力,很大程度上来自于其海量的百万亿级的神经连接。同时,需要说明的是,连接的稀疏性,又能让大脑变得非常节能。因此,开发有效的视觉大模型和稀疏模型,对实现强大而通用的智能来说非常关键。
他通过解决训练稳定性、视觉任务分辨率鸿沟,以及基于自监督预训练解决海量标注数据需求的问题,成功地训练了拥有30亿参数的稠密视觉模型 Swin Transformer v2.0 版本[4]。作为截止2022年8月世界最大的稠密视觉模型,Swin Transformer v2.0 版本当时在多个重要的代表性视觉评测集中取得了新的记录。此外,胡瀚还参与开发了目前 GPU 上最高效的混合专家框架 Tutel 和用于计算机视觉的 Swin-MoE 模型。
促进 AI 不同领域实现大一统和大融合,赋能人类美好生活
回顾自小的成长背景和求学经历,胡瀚感恩于父母对教育的重视。“小时候尽管家境清贫,而且当地辍学率比较高,但他们仍旧支持我一路读到博士。”他喜欢没日没夜地看书,有时也会睡在图书馆,很小就意识到知识的无边界以及世界之大。
在他看来,到北京也是冥冥之中的缘分驱使。“记得高考完找班主任老师给自己写寄语,他写了‘北上’这两个字,后来真的有幸北上到北京求学。后来,博士期间的导师周杰教授,给我们创造了引导为主,鼓励自由探索的氛围。这很适合我,让我的思维自主创新和自我求索方面的能力有了很大的提升。”
他认为,走上研究之路,是命运的安排。他觉得自己遇上了三个转折点:第一个是能够有幸从小乡村考入清华,和最优秀的同学一起学习生活,接受国内最好的教育。第二个是在读研时选择了人工智能方向,也遇到了适合自己的导师,亲眼见证当时发展不算最火热的人工智能,逐渐变得越来越重要,并不断地改变着世界的面貌。第三个是进入微软亚洲研究院工作,与国内人工智能方向最优秀的研究员和前辈合作,在一个适合做研究的土壤下生根发芽,做出了具有代表性的工作。
作为一个科研工作者,他将自己的主要目标定为研究新的生产力工具和突破性技术,从而赋能每个人、每个机构和整个社会。因此,他希望能够推动人工智能不同领域之间的大一统和大融合,让其在未来能像人脑一样,用一个强大通用的模型,就能解决各种复杂的智能任务。“这样的人工智能系统将有望和100年前的电力革命一样,改变整个人类社会的生活和生产方式,促进社会进步,让每一个人的生活都能更加美好。”胡瀚说。
对于未来,他也给自己制定了新的研究目标,他希望攻克通用视觉问题,为实现对图像的可靠(几乎不出现错误)而全面理解和生成而努力。“对于这一个目标来说,我们此前的工作已经从某种程度上验证了在解决视觉和语言问题上,方法论并没有本质区别。既然 ChatGPT 可以几乎可靠地解决几乎所有自然语言处理方面的问题,那么我相信,通用的视觉问题也是能够得到可靠解决的。”胡瀚如是说。
参考资料:
1. Z., Liu. et al. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv(2021). https://arxiv.org/abs/2103.14030
2. H., Hu.et al. Relation Networks for Object Detection. arXiv(2017). https://arxiv.org/abs/1711.11575
3. H., Hu. et al. Local Relation Networks for Image Recognition. arXiv (2019). https://arxiv.org/abs/1904.11491
4. Z., Liu. et al. Swin Transformer V2: Scaling Up Capacity and Resolution. arXiv (2022). https://arxiv.org/abs/2111.09883






