
段楠:把握研究领域的先机,打造更通用的人工智能模型
2024-01-09 | 作者:络绎科学
智能计算是一个非常广阔的概念,涵盖基础理论、软硬件、通用人工智能模型、脑科学、人机协作,以及 AI 在科学、文学、社会学、经济学中应用等一系列问题。
今天,AI 技术的发展已经显露出人类历史上的巨大机遇。通过不断设计、整合与优化软硬件架构和性能、不断获取高质量多模态异构大数据,AI 基础模型的表示、理解和生成能力、小样本学习能力、终身学习能力和推理能力也在不断变强。
“智能计算有望在未来几年取得更加突破性的进展,在诸多领域开创全新的应用场景,并从根本上改变人们的工作和生活。”微软亚洲研究院自然语言计算组资深首席研究员段楠表示。
他的主要研究方向为多语言多模态预训练基础模型、多模态生成式人工智能、代码智能和机器推理等。
多年来,他带领团队与微软内部多个产品部门进行长期深入的产研结合合作,所开发技术成功转化到必应搜索/广告/新闻、微软小娜、Visual Studio/VSCode、Azure 云服务等产品,为全球用户提供多样化 AI 服务。
段楠实现的主要成果包括:主导研发了多语言预训练语言模型 Unicoder,实现单一预训练语言模型对100种人类语言的覆盖;多模态预训练模型 Unicoder-VL,以及全球首个多语言多模态预训练模型 M3P;代码预训练模型 CodeBERT 及其后续版本 GraphCodeBERT 和 UniXcoder,构建代码智能领域基准测试集 CodeXGLUE,引领预训练技术在软件工程领域的快速发展等。
截止目前,他已发表学术论文100余篇,Google Scholar 被引用次数超过10000次,持有专利20余项。凭借构建多语言多模态预训练基础模型,探索基于基础模型的复杂任务推理和任务完成机制,推动通用型人工智能技术的发展,段楠成为 DeepTech 2022年“中国智能计算科技创新人物”入选者之一。

DeepTech 2022年“中国智能计算科技创新人物”入选者段楠
从算法层面助力解决多模态生成式人工智能核心难题
最近三年,段楠带领团队开展视觉内容生成研究,从算法的层面解决了多模态生成式人工智能中的一些核心问题。
他和团队主导实现了业界首个开放域视觉内容生成预训练模型 NUWA(女娲)[1]及其后续版本NUWA-Infinity(任意分辨率图像和视频生成)[2]、NUWA-XL(超长视频生成)[3]和DragNUWA(可控视频生成)[4],引领了人工智能在高清、超长和可控视觉内容生成场景下的创新和落地。
NUWA-Infinity 可生成任意大小的高清图片或长时间视频。该技术将自然语言处理中的“变长”生成算法与视觉内容生成场景进行结合,从而能够生成用户指定大小的高清图片和视频内容。

NUWA-Infinity 基于静态图像生成的视频
NUWA-XL 是针对超长视频生成的核心问题提出的解决方案。该算法可以在保障关键帧场景切换明显的同时,又能够让整个视频内容保持丰富、连贯,并且可以生成较长时间的视频内容。
在以往的视频生成系统或模型中,一般仅可生成几秒钟或十几秒种以内的视频,而 NUWA-XL 实现了用16句话的简短描述生成11分钟动画片,充分展示了该模型对超长视频生成的能力。
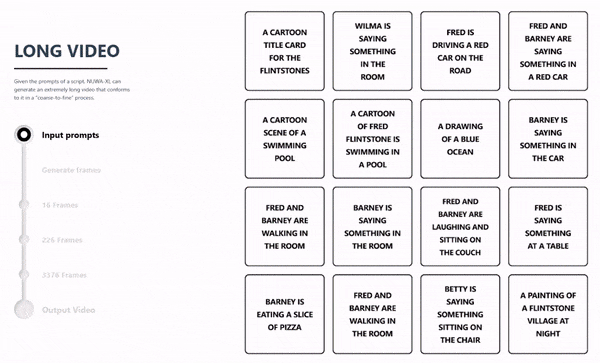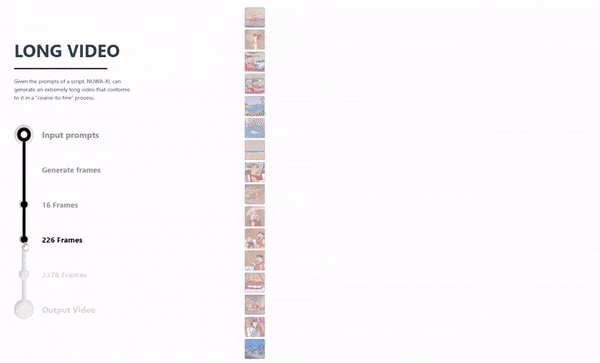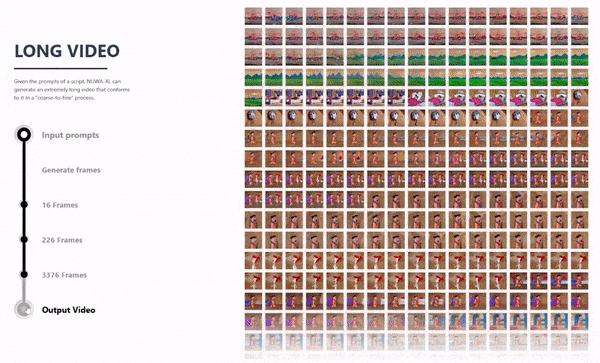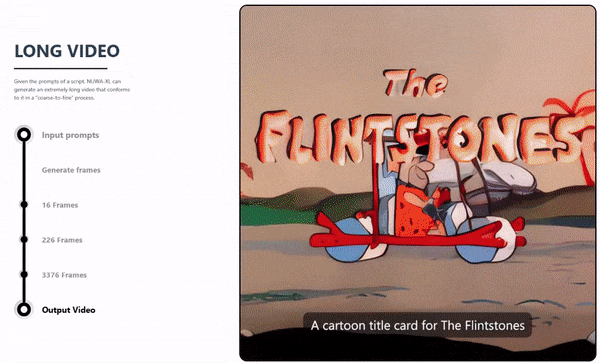
NUWA-XL 长视频生成流程动态演示
最近,段楠与团队提出了新型视频生成模型 DragNUWA,从可控性角度提出视频生成新方案。实际上,从相对比较离散的文字空间到相对比较具体的视觉内容,映射的不是“一对一”,而是“一对多”的关系。也就是说,一句话可以用成千上万种不同的视觉内容来表达。因此,如何让视频生成的内容更加可控是该研究的重点。
与以往研究相比,该研究引入了用户输入的轨迹信息。用户不仅可以输入一句话来生成视频,还可以输入一张静态图片,并在图片上标记希望运动的目标方向和力度、运动角度和轨迹等。
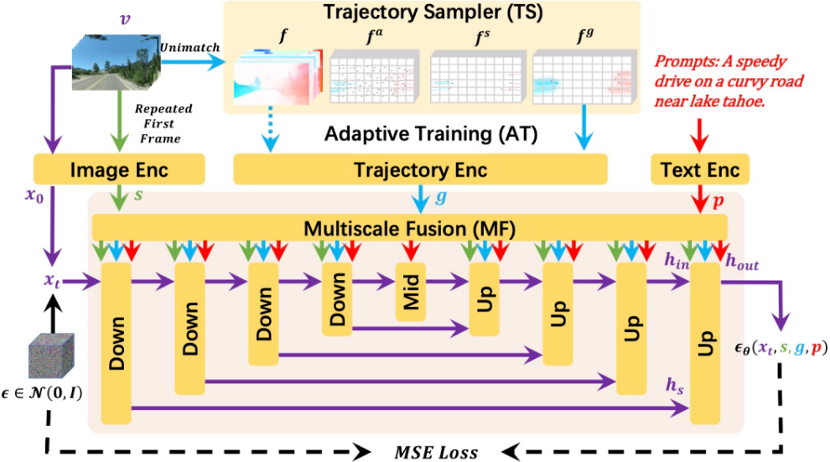
DragNUWA 的训练过程概述
段楠表示:“通过从语义、空间和时间这三个角度提供约束信息,DragNUWA 极大地增强了视频生成模型的可控性。”
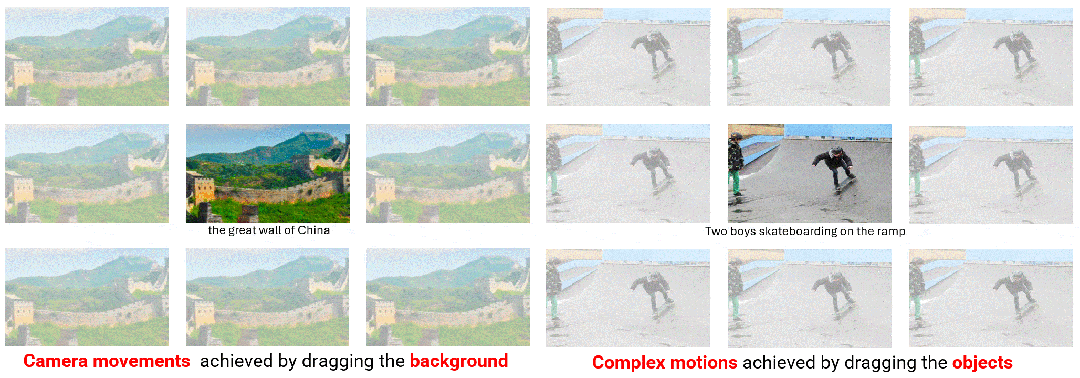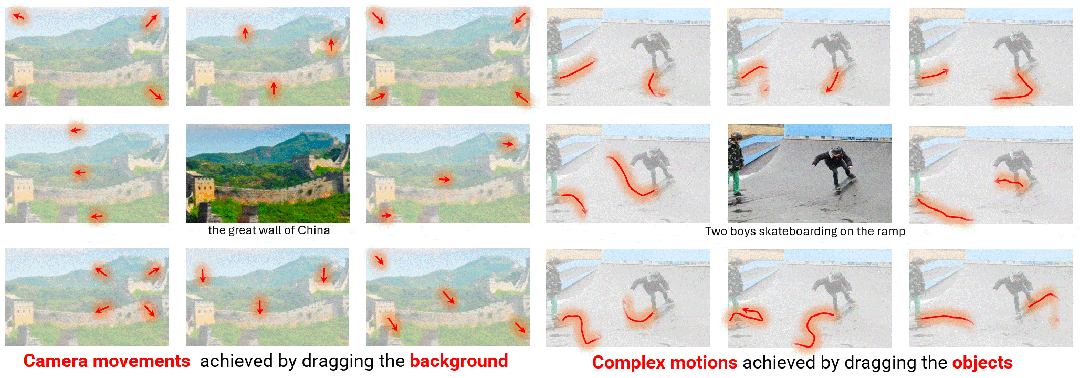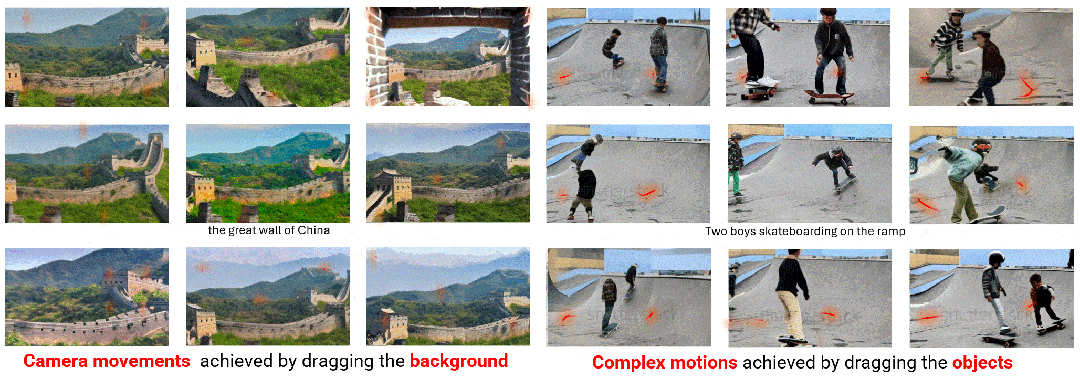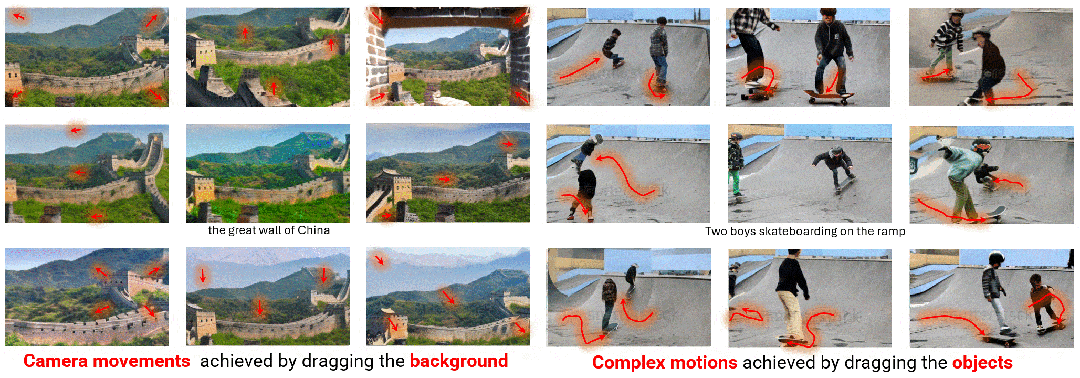
DragNUWA 的两种轨迹控制方式。拖拽背景可以生成各种镜头效果(左),拖拽物体可以生成人物复杂轨迹(右)
多模态生成式人工智能不仅具备巨大的商业价值,还是构建通用型人工智能不可或缺的重要组成部分。当前的人工智能系统主要利用大语言模型进行规划和推理,但人类在做决策时不仅仅会思考一段文字,还会去想象相关的视觉场景。因此,段楠团队对生成算法模型研究的最主要目标,是希望通过设计多模态生成模型帮助人们做更好的规划和推理,以在未来辅助 AI 模型做决策。
“未来,我们希望基于 NUWA 系列工作中沉淀出来的视频生成技术构建通用世界模型(General World Model)。这样就从多模态角度将大语言模型和视频生成模型相结合,从而可以更好地完成任务规划、推理和决策。”段楠说。
从首名联合培养博士到微软亚洲研究院资深首席研究员
2007年夏天是段楠的硕士毕业季,他从硕士期间就开始在前微软亚洲研究院副院长周明(现澜舟科技创始人兼 CEO)负责的自然语言计算组实习。也正是那时,周明开始在天津大学招收博士研究生。
基于对研究方向的热爱和实习期间优异的工作表现,段楠成为了微软亚洲研究院-天津大学的首名联合培养博士,以统计机器翻译为主要研究方向。彼时,与计算机视觉、计算机图形学等方向的发展相比,自然语言处理还处于相对发展平缓的阶段。
2012年,段楠在博士毕业后正式加入了微软亚洲研究院,研究方向以问答和自然语言理解为主。段楠与团队早期在多语言模型方面进行系列研究,并开发了微软内部首个多语言预训练模型 Unicoder[5],该技术此后落地到微软必应搜索引擎,支持全世界100种语言和200个地区的搜索和问答。2021年4月,Unicoder 模型登上 XTREME 多语言自然语言理解基准测试排行榜。
当时,人们总是想找到一种无歧义的中间形式化语言来标注数据,这样机器可以非常方便地理解自然语言。但这充满挑战,怎么样才能够很好地获得大量的结构化数据,来更好地理解自然语言呢?

段楠团队部分成员合影
在 Visual Studio/VSCode 等微软产品陆续开发后,2019年左右,他们意识到,编程语言就是一种无歧义的语言,用它作为语言机器将非常容易理解。
随着语料的累积,大语言模型(Large Language Model,LLM)对自然语言具有非常丰富的理解能力。段楠与团队带着对语义分析挑战的问题,直接开展了后续一系列代码智能的研究,包括:业界首个代码预训练模型 CodeBERT[6] 及其后续版本 GraphCodeBERT[7] 和 UniXcoder[8],构建代码智能领域基准测试集 CodeXGLUE[9] 等。后续 OpenAI 的 CodeX、ChatGPT 和 GPT-4 更是直接验证了代码预训练对构建 LLM 的重要性。
回顾多年来的研究方向和研究课题,段楠团队好像总是在特殊的时间节点上“提早准备”,对此段楠表示:“作为团队负责人,必须对领域发展有系统的、明确的认识,再根据技术的发展,抓住时机及时调整研究方向。”
他同时指出,现在随着 ChatGPT 的出现,领域的选题也越来越难。研究者不仅要考虑当下能解决的问题,也要更长远地去解决那些根本性的问题。
将持续推动通用型人工智能技术的发展
当前,AI 技术大致分为四个主要研究方向,即 LLM、多模态 LLM、多模态生成式人工智能以及 AI 智能体。
简单来理解这四个方向,LLM 构造类似于大脑的功能;多模态 LLM 是对声音、图像等外界环境具有感知能力;生成式人工智能是让 AI 模型具备听、说、读、写的能力;AI 智能体则是让整个 AI 系统能够调用甚至制造工具,并利用这些工具完成数字世界或物理世界各种类型的任务。
段楠认为,未来与 AI 本身发展同样重要的是,需要构建负责任的 AI(谢幸:做经得起时间检验的研究,打造负责任的人工智能)。也就是说,要保证 AI 模型与人类共生、共创,让 AI 更好地辅助人类去提升生产力及创造力。
他指出,目前 AI 模型在没有见过的、复杂的问题上做得还不够好。以最新的一些 AI 模型为例,一旦它们遇到新出现的、相对复杂的数学类或算法类问题,相关生成质量明显下降。
因此,增强模型的推理能力是非常重要的方向之一,将让它们在未遇到过的问题上具备泛化能力。这样,即便在没有数据驱动的研究方向,也能够通过 AI 模型进行推理。
段楠表示,在感知层构建多语言、多模态、多领域统一预训练模型,在认知层探索具备小样本学习和终身学习能力的可解释复杂推理机制,这两方面研究能够从总体上推动通用型人工智能技术的发展,并驱动其在创新性应用产品中的落地。
参考资料:
[1] Chenfei Wu, et al. "NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion"
https://arxiv.org/abs/2111.12417
[2] Chenfei Wu, et al. "NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis"
https://arxiv.org/abs/2207.09814
[3] Shengming Yin, et al. "NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation"
https://arxiv.org/abs/2303.12346
[4] Shengming Yin, et al. "DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory"
https://arxiv.org/abs/2308.08089
[5] Haoyang Huang, et al. "Unicoder: A Universal Language Encoder by Pre-training with Multiple Cross-lingual Tasks"
https://arxiv.org/abs/1909.00964
[6] Zhangyin Feng, et al. "CodeBERT: A Pre-Trained Model for Programming and Natural Languages"
https://arxiv.org/abs/2002.08155
[7] Daya Guo, et al. "GraphCodeBERT: Pre-training Code Representations with Data Flow"
https://arxiv.org/abs/2009.08366
[8] Daya Guo, et al. "UniXcoder: Unified Cross-Modal Pre-training for Code Representation"
https://arxiv.org/abs/2203.03850
[9] Shuai Lu, et al. "CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation"
https://arxiv.org/abs/2102.04664






