
AAAI 2023 | 让人工智能技术变得有理论意义与负责任的新思考
2023-02-15 | 作者:微软亚洲研究院
编者按:本年度的 AAAI 大会已经拉开帷幕。上期文章介绍了在工业应用领域内人工智能研究的最新科研成果 ,本期文章继续放送微软亚洲研究院的研究员们在入选 AAAI 2023 的研究工作中,对人工智能创作、人工智能理论、负责任的人工智能相关话题的最新思考。
人工智能创作
VideoDubber:语音时长控制的机器翻译视频配音模型

论文链接:https://arxiv.org/abs/2211.16934
Demo链接:https://speechresearch.github.io/videodubbing
代码链接:https://github.com/microsoft/NeuralSpeech/tree/master/VideoDubber
视频译制(video dubbing)一般指将视频中的语音由原始语言翻译为目标语言,并保证翻译后音画同步。通常,视频译制由多个级联系统组成,包括语音识别、机器翻译和语音合成。以往的工作通常只在机器翻译阶段控制翻译后的单词/字母的数量,不考虑不同语言中单词/字符发音持续时间的相异性。为了同时保证翻译结果的自然性和语音同步性,微软亚洲研究院的研究员们提出的 VideoDubber 在机器翻译阶段引入了语音时长控制,直接以翻译中每个 token 的语音时长匹配目标语音的长度,进而减少因语音合成阶段时长的过分调整对翻译自然度的影响。
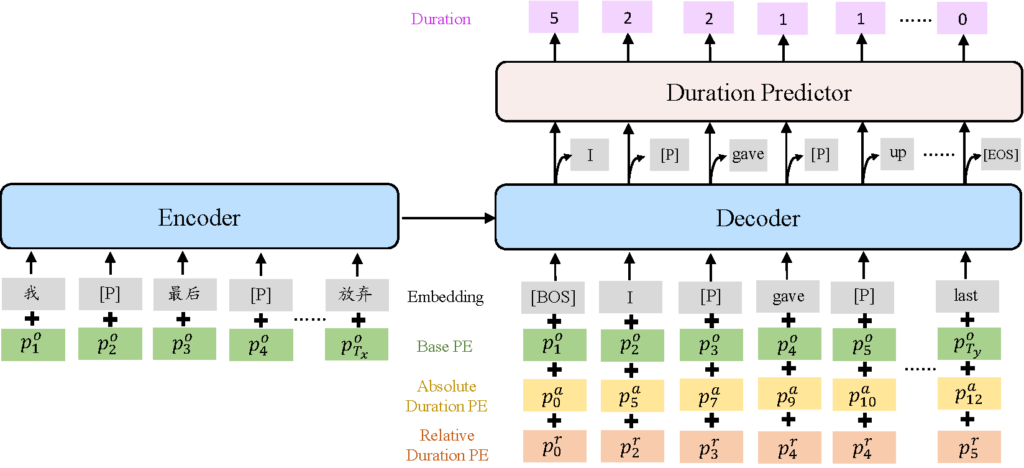
图1:VideoDubber 的整体架构
VideoDubber 设计了两种与时长相关的位置编码(绝对时长编码和相对时长编码)在机器翻译过程中集成时长信息,引导对每个单词音长的预测,从而控制生成句子的语音长度。实验结果表明,VideoDubber在四个语言中的视频译制同步性优于基线模型,而且在保证翻译质量的同时,还实现了更好的语音时长控制。此外,由于真实视频译制数据集的不足,研究团队还构建了一个从电影中收集的真实场景测试集,对视频译制任务进行了综合评价。实验证明,在考虑语音等时性的真实测试集中,VideoDubber 的等时性控制能力和翻译质量更优秀。此外,主观评价表明, VideoDubber 自动译制视频的整体质量有显著提升。
人工智能理论
基于因果的组合在线学习

论文链接:https://arxiv.org/abs/2206.01995
本文探讨了基于因果的组合在线学习问题。在这个问题中,玩家在未知的因果模型中交互,干预变量的选择将影响因果模型中可见变量的最终结果。算法通过玩家的交互学习因果模型的参数,并更新干预策略得出多轮交互的累积悔值(即选择的干预方式与使得目标奖励变量最大化的最优集合在累计奖励上的差距)的最小值。
此前的理论研究中对因果在线学习中的组合优化问题的探讨有所欠缺,从而导致理论悔值中出现关于图大小的指数项。在组合在线学习的研究中,每个基础选择臂(base arm)的独立性与因果在线学习都不兼容。为了解决不兼容问题,本文提出了一种特殊的因果模型——二元广义线性模型(binary generalized linear model),仅有最多 n(n-1)/2 个参数(n 为变量个数)。对于一般的马尔科夫二元广义线性模型,本文设计了一种使用极大似然估计的在线算法 BGLM-OFU,可以实现 O(n^{3/2} T^{1/2} ln T) 的期望累积悔值。
针对二元线性模型(binary linear model),本文提出了一种新的解决方案:利用 do-calculus 算法,将包含隐藏结点的因果模型部分转化为马尔可夫因果模型,从而部分解决包含隐藏节点的因果模型中的组合在线学习问题。此外,新的算法 BLM-LR 也在本文中被提出,它使用线性回归代替极大似然估计,进一步摆脱对参数取值的假设,同时可以实现 O(n^{5/2} T^{1/2} ln T) 的累积期望悔值。
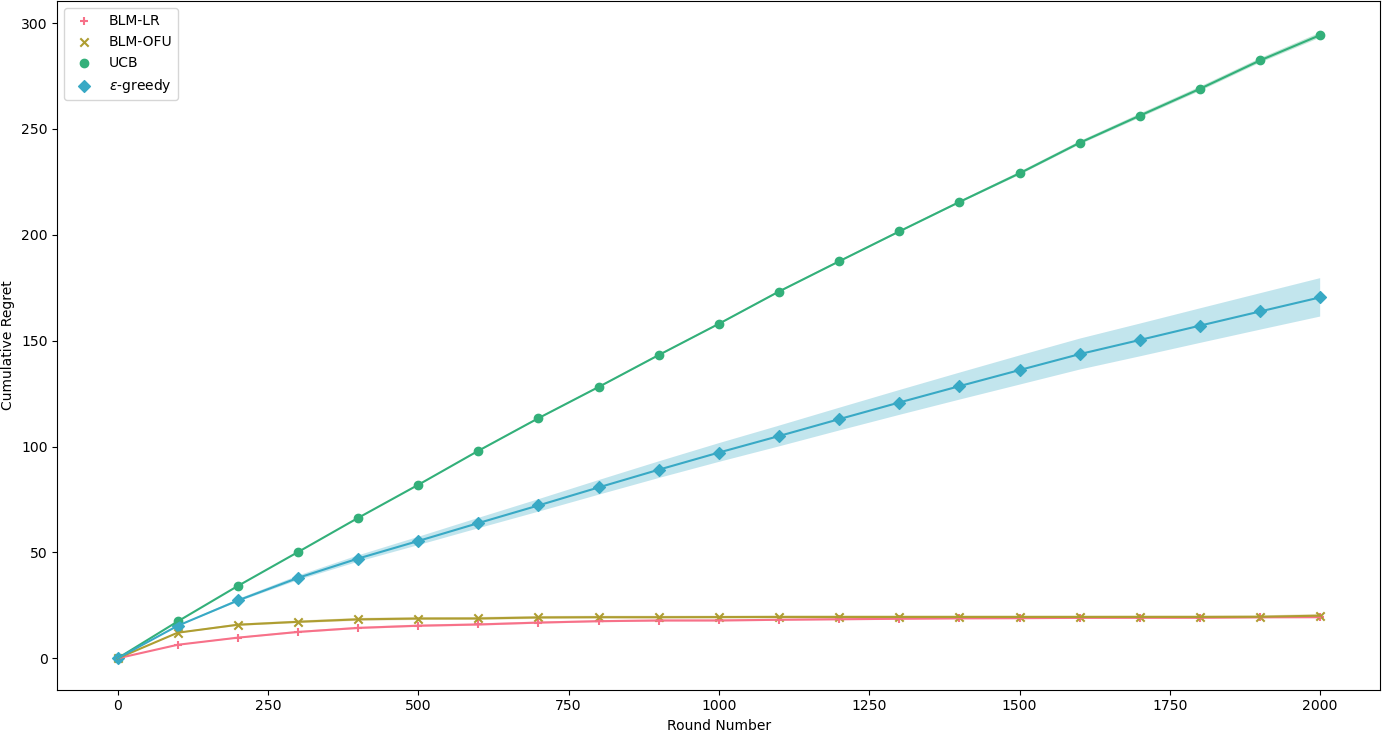
图2:在一个具有9个节点的平行图二元线性模型上进行性能模拟,BGLM-OFU 和 BLM-LR 算法的表现都优于传统的 UCB 和 Epsilon-Greedy 算法
主动Token融合算子

论文链接:https://arxiv.org/abs/2203.06108
如何进行有效的 token 信息的融合(token-mixing)是当前计算机视觉基础网络设计的重点。综合分析现有的 CNN、Transformer 和 MLP 网络中不同 token 融合方式的优缺点后,微软亚洲研究院的研究员们创新性地提出了一种主动且高效的 token 融合方式,作为计算机视觉任务中通用的基础算子。
研究员们提出了一种对于空间 token 进行细粒度(channel-wise)主动融合的算子(Active Token Mixer,简称为 ATM)。ATM 将空间信息融合的过程分解为三个并行的分支,即水平方向的融合、竖直方向的融合和原特征的处理。在水平方向和竖直方向上,ATM 能够根据不同位置的语义信息研判对应空间范围内不同位置的信息融合方式,从而实现空间 token 的自适应融合。基于 ATM,研究员们搭建了一种高效的基础视觉网络 ATMNet。大量的实验证明,不同模型大小的 ATMNet 在分类任务(ImageNet-1k)、物体检测任务(COCO)和语义分割任务(ADE20K)上均能取得 SOTA 性能。
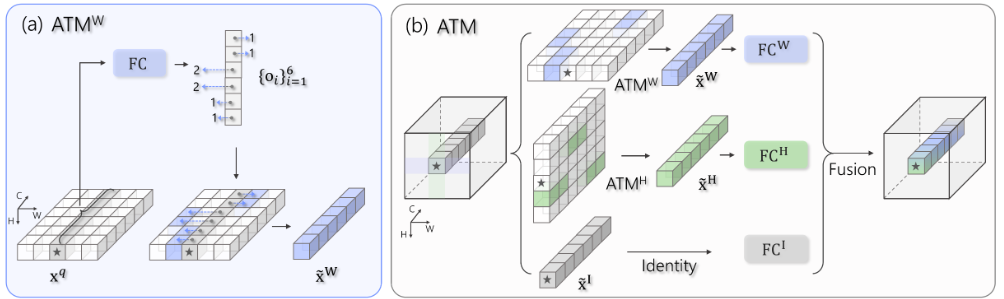
图3:在水平方向上基于主动 token 融合的过程示意图(a)和完整的 ATM 模块示意图(b)
负责任的人工智能
Prototypical Fine-tuning: 自适应数据集大小的稳健微调方法

论文链接:https://arxiv.org/abs/2211.13638
预训练模型在各种 NLP 任务上都已取得了巨大成功。预训练模型强大的判别能力可以归因于一个较弱的归纳偏差,使得模型的表达性受较少约束。但这同时也造成了过拟合和局部最优的问题,在训练样本数量较少时尤为明显。诸如 prototypical learning 等非参数模型较为直接建模数据的类内与类间关系引入了较强的归纳偏差。
微软亚洲研究院的研究员们综合大规模预训练模型与非参数模型的优点,使得模型能够自由习得一个归纳偏差,从而适应不同复杂度的数据集。本文提出了 Prototypical Fine-tuning (PFit)。PFit 将每个类中的数据表示为一组 prototype,每个 prototype 均建模为混合分量。同时,PFit 基于模型性能和数据分布的复杂程度自动学习 prototype 个数。PFit 确保了假设空间足够充分,使得在保证模型有足够泛化能力的同时,更加轻易地学到任务的可行解。
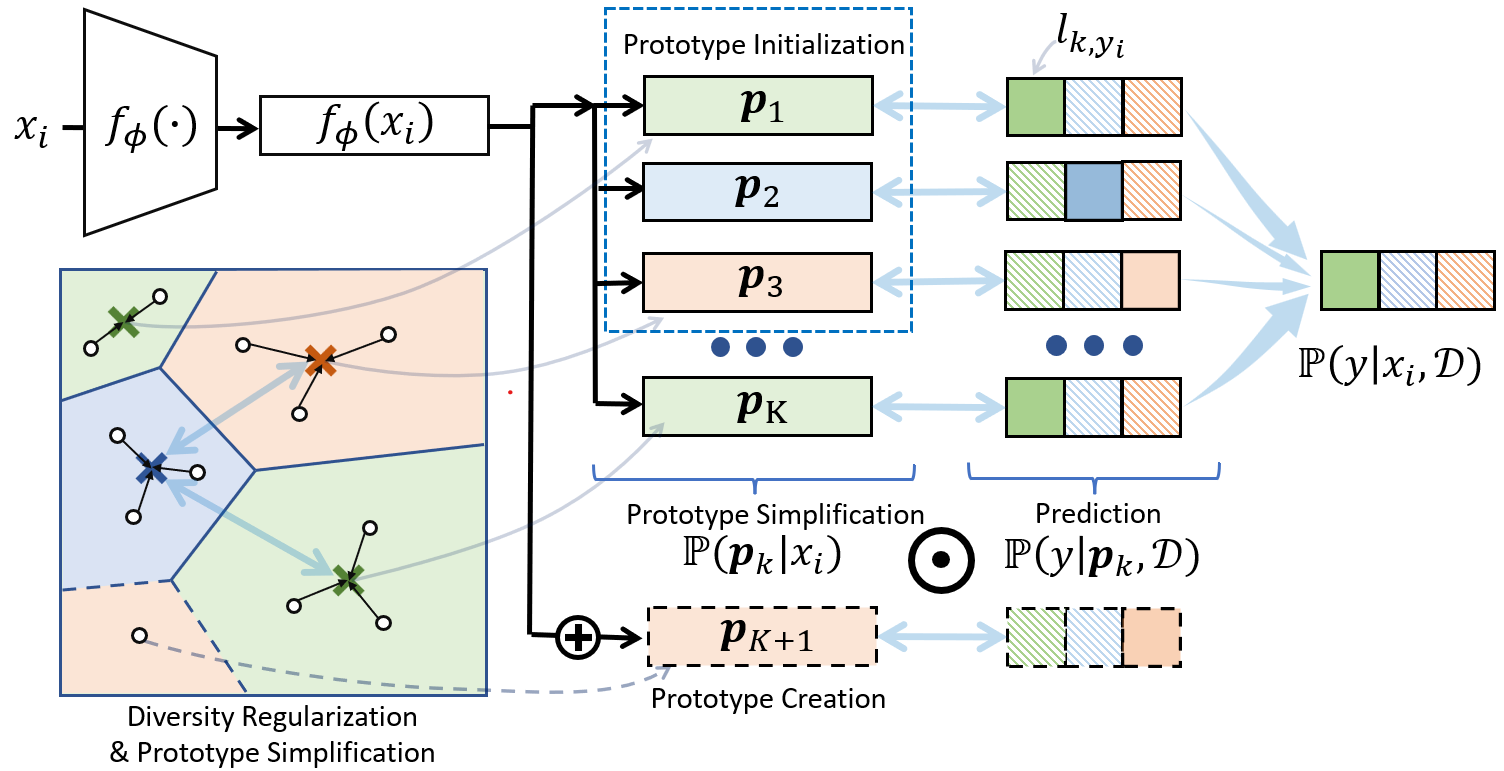
图4:Prototypical Fine-tuning 模型图
PFit 由四部分构成:
● Mixture Prototype Initialization :利用预训练模型表征中的语义特征来初始化 prototype 以加快收敛;
● Infinite Mixture Prototype Creation:扩展 Infinite Mixture Prototype (IMP) 以灵活地捕捉数据分布,并在用数据驱动方式的同时微调 prototypes 与预训练模型;
● Adaptive Prototype Simplification:为提高泛化能力和效率,利用简单的归纳偏差并维护一组能够充分表示数据分布的 prototypes;
● Dynamic Diversity Regularization:动态地增强 prototypes 的多样性,以提高模型表达力;
在多个数据集上的实验表明,PFit 在低资源场景下可以显著提升性能,且在高资源场景中可以达到与原模型相当甚至更佳的效果。
基于相似度分布的成员推断

论文链接:https://arxiv.org/abs/2211.15918
本文揭示了一种图像检索和识别类模型中基于成员推断的新型安全风险。以往的成员推断攻击相关研究只关注图像分类任务,忽视了检索和细粒度识别任务的神经网络模型同样存在被攻击的风险。然而,由于图像检索和细粒度识别算法与图像分类模型的训练和推理范式差异较大,原有方法并不适用。
因此,为了能够更好地评估图像检索和细粒度识别模型在成员推断攻击上的安全风险,本文提出了一种新方法。由于图像检索主要关注样本间的关联关系,所以微软亚洲研究院的研究员们提出了一种基于样本间相似度的分布来进行成员推断的新攻击方法。实验证明,新方法对于图像检索和以往的图像分类任务都能形成有效的攻击威胁。
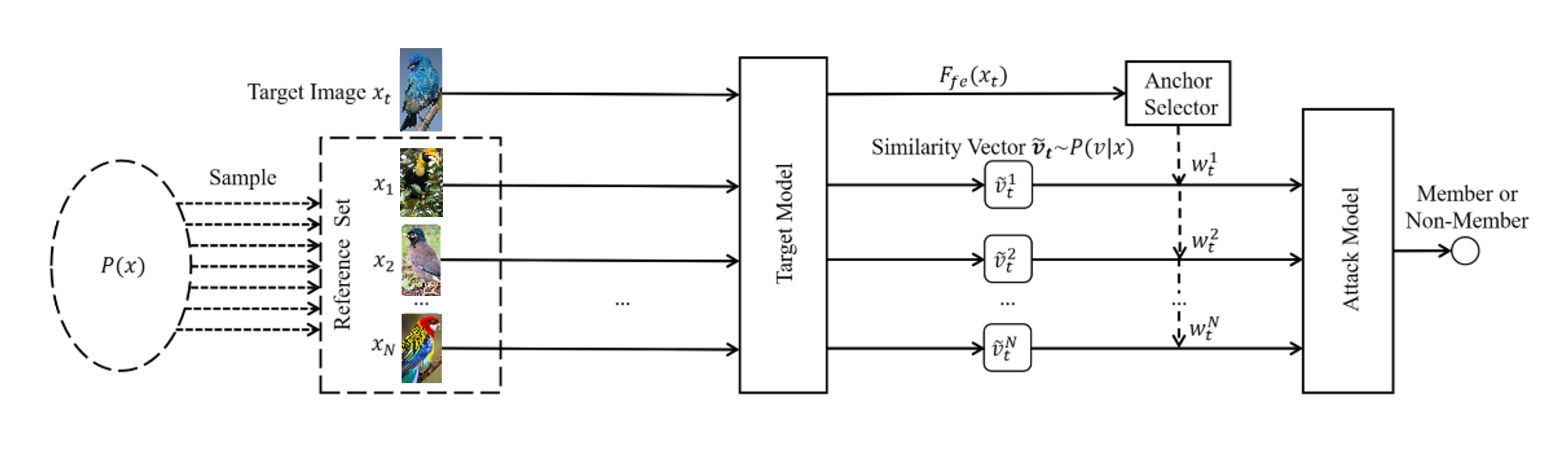
图5:基于样本间相似度的分布来进行成员推断的新攻击方法






