
AAAI 2023 | 工业应用领域内,人工智能研究的最新学术成果
2023-02-09 | 作者:微软亚洲研究院
编者按:由美国人工智能协会主办的 AAAI 是(Association for the Advance of Artificial Intelligence)人工智能领域的顶级学术会议之一。本年度的 AAAI 大会于2月7日至2月14日举办,微软亚洲研究院也有多篇论文入选,讨论的主题包含:工业应用中的人工智能、人工智能理论、负责任的人工智能和人工智能创作等。欢迎跟随本期文章,速览工业应用领域内人工智能研究的最新学术成果。
针对从离线到在线强化学习的自适应策略学习

论文链接:https://www.microsoft.com/en-us/research/publication/adaptive-policy-learning-for-offline-to-online-reinforcement-learning/
当前,强化学习领域主要有两个分支:离线(offline)强化学习和在线(online)强化学习。前者关注在没有交互环境的情况下,仅凭离线数据集训练智能体;后者则是通过和环境交互的方式来训练智能体。然而在现实中,离线数据集并不完备,只通过之前的数据不能训练出最优智能体。在线强化学习虽然可以得到无限的数据,但因为在线探索的难度较大,所以往往需要巨大的在线探索样本。
本工作关注了两个领域的结合方向,即首先通过离线的方法进行预训练,然后在进行在线学习。研究员们提供了结合这两类方法的一种简单策略:通过对离线数据和在线数据进行区分,在学习的时候采取不同的更新策略来更大限度地提高学习效率。本方法能够便利地应用于当前流行的离线强化学习方法。
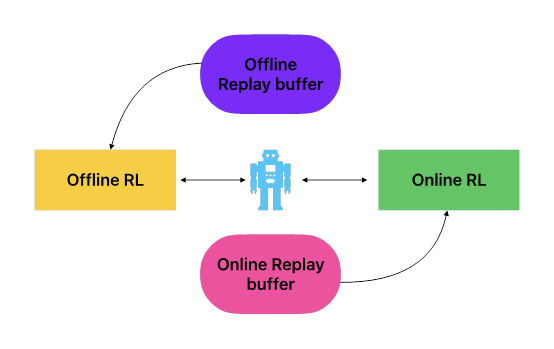
图1:自适应策略学习方法
H-TSP:一种解决大规模旅行商问题的分层强化学习算法

论文链接:https://www.microsoft.com/en-us/research/publication/h-tsp-hierarchically-solving-the-large-scale-traveling-salesman-problem/
旅行商问题是著名的 NP 难问题,在供应链领域有着广泛的应用,尤其是与路径规划相关的应用。例如,给定一个分布在不同位置的客户列表,如何规划访问顺序才能使总旅行路径最短。随着客户数量增加,获取最优解的复杂度也呈指数级增加。当客户数量达到数千个及其以上时,获取次优解也需要花费大量的计算时间,或者在较短时间内难以获取高质量的解。这限制了其在实际问题尤其是规模较大且对求解效率要求较高的场景中的应用,如快递配送中的实时订单调度等。
本文提出了一个端到端的基于分层强化学习的方法 H-TSP 来解决此问题。该方法包含两层策略:上层策略用于将原始的规模较大的问题拆解成多个规模较小的子问题;下层策略解决每个子问题并将子方案合并形成原始问题的解决方案。通过实验对比发现,H-TSP 方法能够较好地协调效果与效率时间的平衡。同目前最高效的基于搜索的方法相比,该方法能够在仅损失4%效果的情况下,将求解时间从395秒降低到3.4秒。这也是首个达成处理超过10000的客户规模的端到端方法。
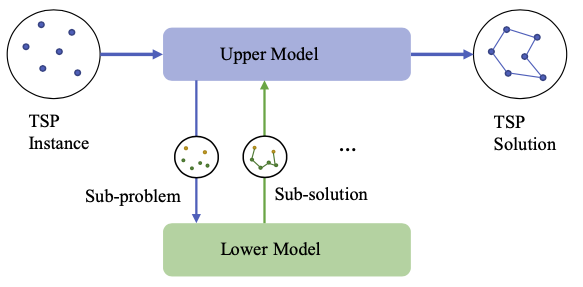
图2:H-TSP 方法的流程图,由上层策略(upper model))和下层策略(lower model)组
Pointerformer:一种基于多指针Transformer的解决旅行商问题的深度强化学习方法

论文链接:https://www.microsoft.com/en-us/research/publication/pointerformer-deep-reinforced-multi-pointer-transformer-for-the-traveling-salesman-problem/
随着深度强化学习在越来越多的问题上都取得了较好的效果,其也被应用到了一些经典的组合优化问题中,比如旅行商问题。虽然文献中提出了众多不同的方法,但总的来说可以将其归为两类:基于搜索以及端到端的方法。基于搜索的方法通常结合一些启发式的搜索策略,能够取得较好的效果,但是搜索本身会消耗大量的时间,使得这类方法的效率较低;另一方面,端到端的方法可以直接生成解决方案,因此可以在很短的时间内给出答案,但是由于学习本身的复杂性使得这类方法仅在数百个节点的问题中效果显著,很难扩展到更大规模的问题上。
在更大规模问题上应用端到端的方法的阻碍主要有两点:内存的消耗和学习的效率。针对这两点,本文提出了一个新的用以求解较大规模的旅行商问题端到端的方法 Pointerformer。研究员们采用了占用内存较小的可逆残差网络和多头 Transformer,结合如特征增强、扩展的节点上下文等策略。Pointerformer 方法能够扩展到包含数千个节点的问题上并取得较好的效果。
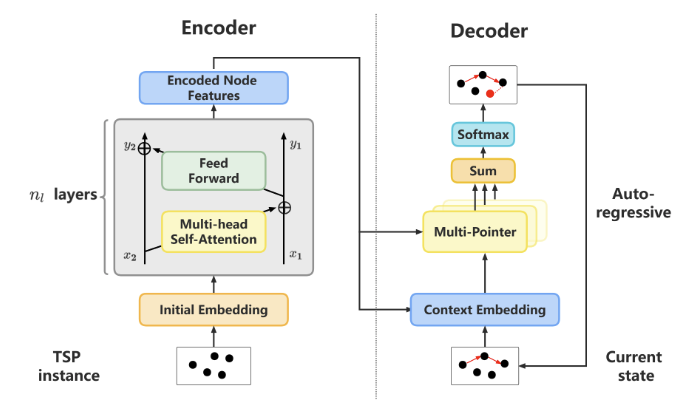
图3:Pointerformer 方法流程图,Encoder 生成节点的嵌入信息,Decoder 结合上下文信息生成解决方案
用于多变量时间序列建模的空间关系分解

论文链接:https://www.microsoft.com/en-us/research/publication/learning-decomposed-spatial-relations-for-multi-variate-time-series-modeling/
多变量时间序列建模(Multi-variate time-series modeling)在金融、气象、交通等领域都得到了广泛的应用。许多运用图与图神经网络来表征变量间空间关系的方法都取得了不俗的效果。
但现有的空间关系建模方案仍存在一些问题,部分方法需要数据中提供变量间的空间关系,从而导致利用范围被限制。另一些方法通过图结构学习从时序数据中挖掘空间信息,但往往对整个数据集仅用单一静态图建模,无法灵活建模,因此数据中很可能存在不断变化的变量间关系。
为了解决上述问题,本文提出了一种多变量时间序列中空间关系分解框架(spatial relation decomposition framework,简称 SRD),将变量间的空间关系分解为动态和静态两部分,并分别用一个先验图(prior graph)和动态图(dynamic graph)来表示。为了更好的协调两个图的学习,本文采用了 Min-Max 学习的策略,在更好建模动态静态两部分空间关系的同时,保证了训练效率。在多变量时间序列预测(forecasting)和点预估(point prediction)任务上,SRD 都超越了已有的方法。进一步的实验分析表明,先验图和动态图对原数据中动态和静态的空间关系进行了合理的分解和建模。
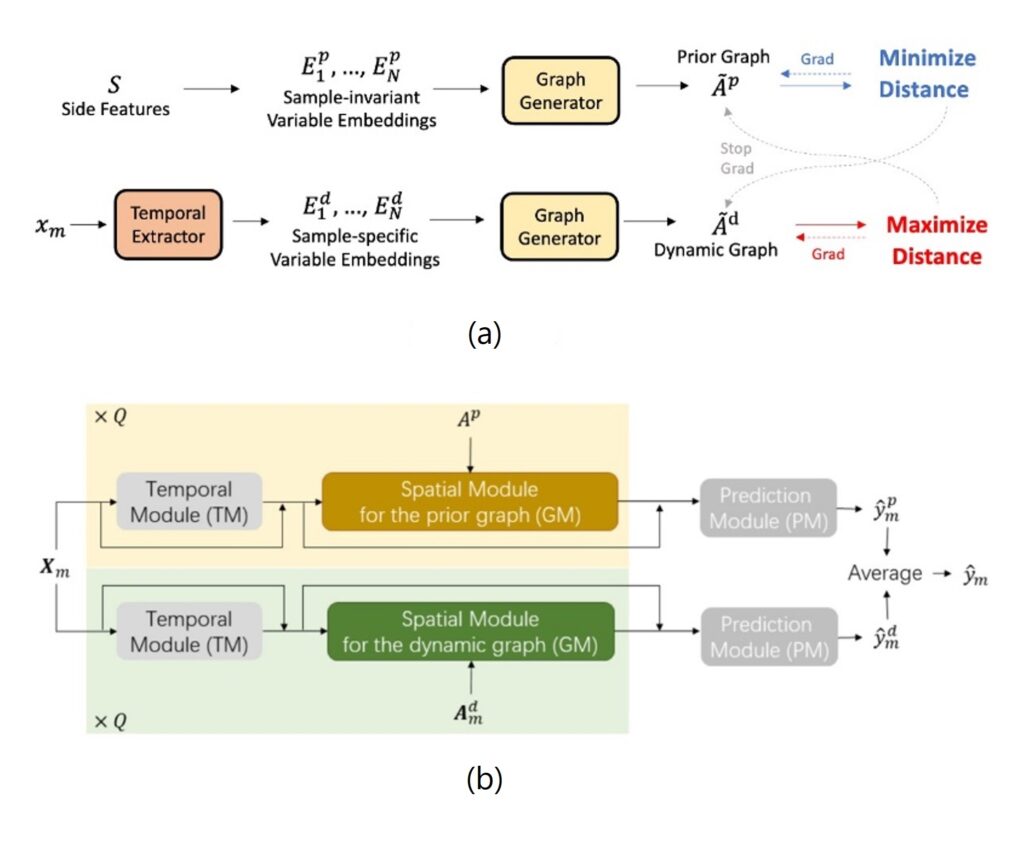
图4:(a)图学习框架;(b)整体网络结构
MultiSpider: 面向多语言Text-to-SQL语义解析任务的数据集

论文链接:https://arxiv.org/abs/2212.13492
Text-to-SQL 语义解析是一项重要的 NLP 任务,极大的方便了用户和数据库之间的交互,成为许多人机交互系统的关键组成部分。Text-to-SQL 研究工作的最新进展一直由大规模数据集驱动,但其中大多数以英语为中心。
对此,微软亚洲研究院的研究员们提出了目前最大的多语言 Text-to-SQL 数据集 MultiSpider,涵盖七种语言(英语、德语、法语、西班牙语、日语、中文和越南语)。
在此基础上,研究员们在三种典型实验设置(零样本、单语和多语言)下的结果表明,相对于英语,非英语语言的平均准确性下降了6.1% 。通过定性和定量分析,研究员们进一步探究了其背后的原因:Text-to-SQL 任务的两个挑战——lexical mapping 和 structural mapping,在不同语言的具体表现以及强度。除了数据集,为了解决 lexical 方面的挑战,研究员们还提出了一个简单通用的数据增强框架 SAVE (Schema-Augmentation-with-Verification),使得所有语言的整体准确率提高了1.8%,并且将不同语言间的表现差异减少了29.5%。
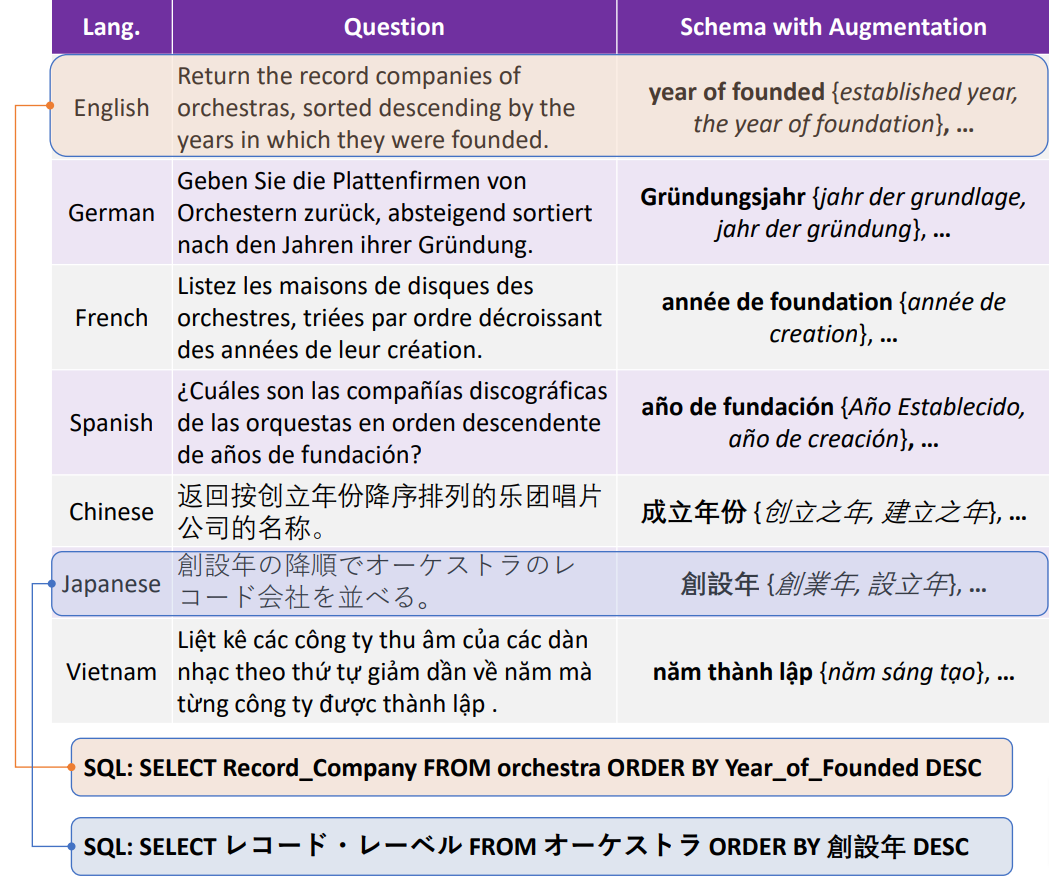
图5:MultiSpider 数据集示例
迈向推理高效的深度集成学习

论文链接:https://arxiv.org/abs/2301.12378
项目主页:https://seqml.github.io/irene/
深度集成学习在带来了性能提升的同时,也带来了较高的推理成本,但集成推理的高效性却很少被讨论。原因之一是人们普遍认为更多的模型会带来更高的性能收益。然而,经研究发现,扩大集成学习的规模所带来的性能提升呈边际效应递减。此外,以往的工作为加速推理,采用启发式标准(如置信度阈值)来决定是否停止推理,但这些方法没有将推理效率作为优化目标的一部分,可能产生次优的解决方案。
因此,本文提出了一种推理高效的集成学习方法 Inference Efficient Ensemble(IRENE 意为和平女神),以实现集成学习性能与效率的同步优化。IRENE将模型的集成视为一个序列决策问题,并学习一个序列选择器以预测任意样本,最后完成集成模型的最佳推理停止(inference halting)步骤。基础模型和序列选择器被精心设计的优化目标联合优化,使集成推理能够针对不同难度的样本进行动态调整。实验表明,IRENE 可以降低高达56%的推理成本,同时保持与完全集成相当的性能,实现了明显优于其他基线的集成效用。
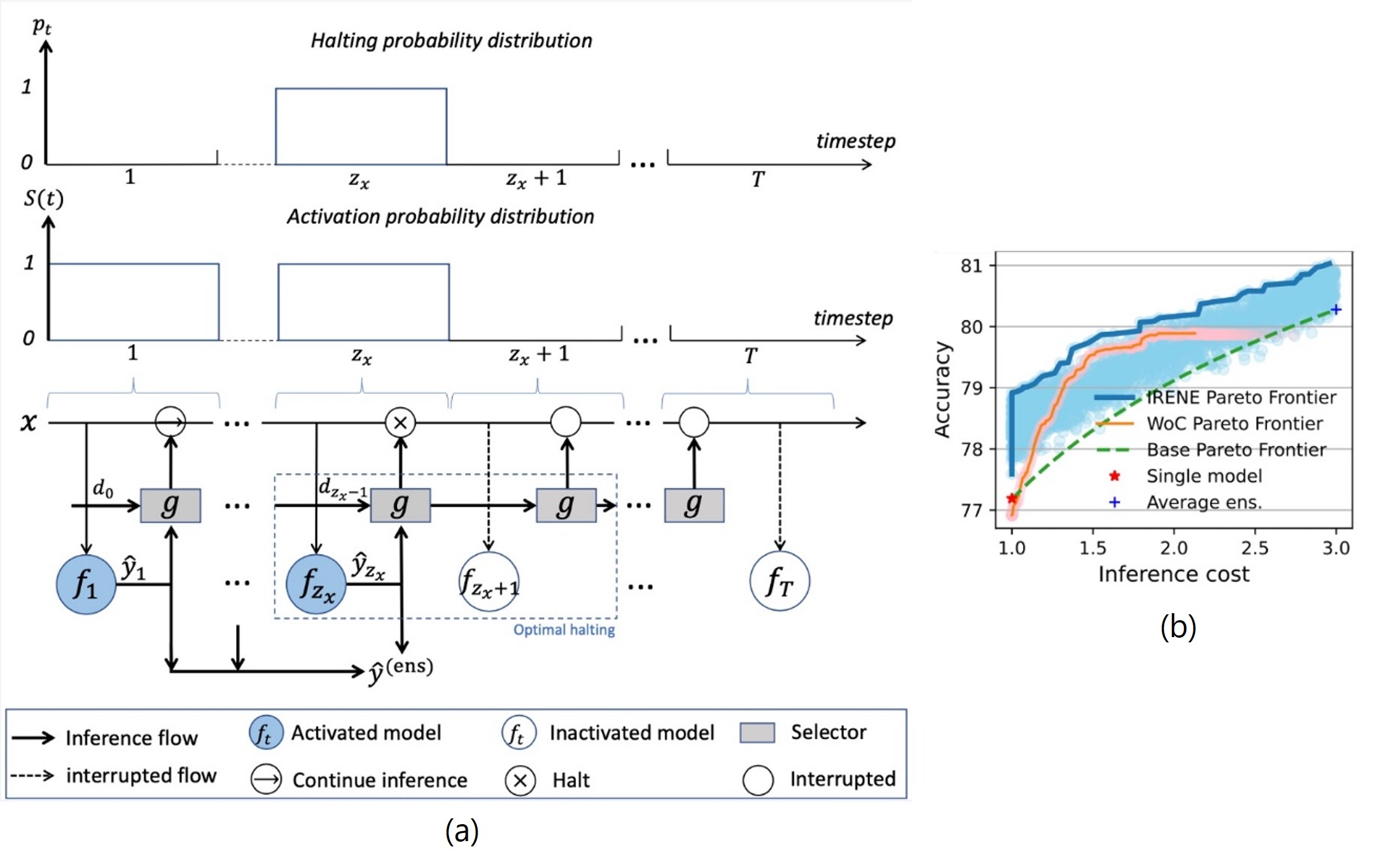
图6:(a)IRENE 的顺序推理和最佳停止机制;(b)不同方法的帕累托前沿






