
ICLR 2023 | 负责任的人工智能,守护机器学习的进阶思考
2023-04-27 | 作者:微软亚洲研究院
编者按:国际学习表征会议 ICLR(International Conference on Learning Representations),被公认为当前最具影响力的机器学习国际学术会议之一。多个来自微软亚洲研究院的最新研究成果被 ICLR 2023 大会接受。跟随上两期文章领略过杰出论文与机器学习鲁棒性方向的技术洞见后,本期将与大家分享负责任的人工智能方向的三篇研究工作,它们分别拓展了差分隐私深度学习效率的边界、时序图的可解释性研究以及预训练语言模型在文本生成中的安全性。欢迎点击论文链接,直达对负责任的人工智能的进阶思考!
T-GNNExplainer:时序图上的解释器

论文链接:https://openreview.net/pdf?id=BR_ZhvcYbGJ
时序图是一种基于时间的动态图,其中的节点和边都带有时间戳,在线社交网络和道路交通网络等就是时序图的典型例子。鉴于时序图的广泛应用,已经有许多时间图模型被提出,例如 Jodie,TGAT 和 TGN。与静态图神经网络相比,时序图模型中每个节点的表征都是一个时间的函数,用于预测未来演化趋势,例如哪些边将产生以及节点属性何时改变。
尽管这些时序图模型已被成功应用,但它们都是黑盒模型,缺乏透明度。信息如何在时序图中聚合和传播,以及历史事件如何影响预测等问题仍不清楚。对于理解预测的基本原理以及模型特性而言,人工智能的可解释性至关重要。当时序图模型应用于高风险场景时,如金融系统中的欺诈检测和医疗健康中的疾病进展预测,解释器都可以增加信任和可靠性。此外,解释器还有助于检查和减轻现实世界应用中的隐私、公平和安全问题。
目前的现有解释器往往是专注于静态图模型的设计,对时序图的预测解释仍然需要进一步探索。因此,微软亚洲研究院的研究员们提出了 T-GNNExplainer:首个为时序图模型量身定制的解释器。具体来说,T-GNNExplainer 将时序图视为一系列节点之间的时间事件。对于给定的某次预测,T-GNNExplainer 的任务是找到导致预测的历史事件的一个子集。历史事件是先前发生的事件,所以同时满足空间和时间条件:它们在基于消息传递机制的k-跳邻域中,并且它们的时间戳应该接近目标事件的时间戳。
为了解决寻找子集的组合优化问题,T-GNNExplainer 包含探索和导航模块。探索模块采用蒙特卡洛树搜索,搜集在候选事件集中找到的重要事件。导航模块负责学习候选事件之间的关联性,以帮助缩小搜索空间。值得一提的是,导航模块是预训练模块,与探索模块集成后,能够大大加快搜索速度并提高结果质量。
研究员们基于两个典型的时序图模型(TGAT 和 TGN),同时在合成和真实的数据集上评估了 T-GNNExplainer 的性能。合成数据集采取了多元 Hawkes 过程和预定义的事件关系规则模拟产生事件,从而得到时序图。通过与合成数据集的重要事件集对比,研究员们发现 T-GNNExplainer 可以精确找到一个重要的事件集。在真实数据集中,由于确切的导致某个事件发生的事件集不可知,因此研究员们采用保真度-稀疏度曲线来评估 T-GNNExplainer 的性能。结果表明,相对于基准模型,T-GNNExplainer 的改进率高达约50%。
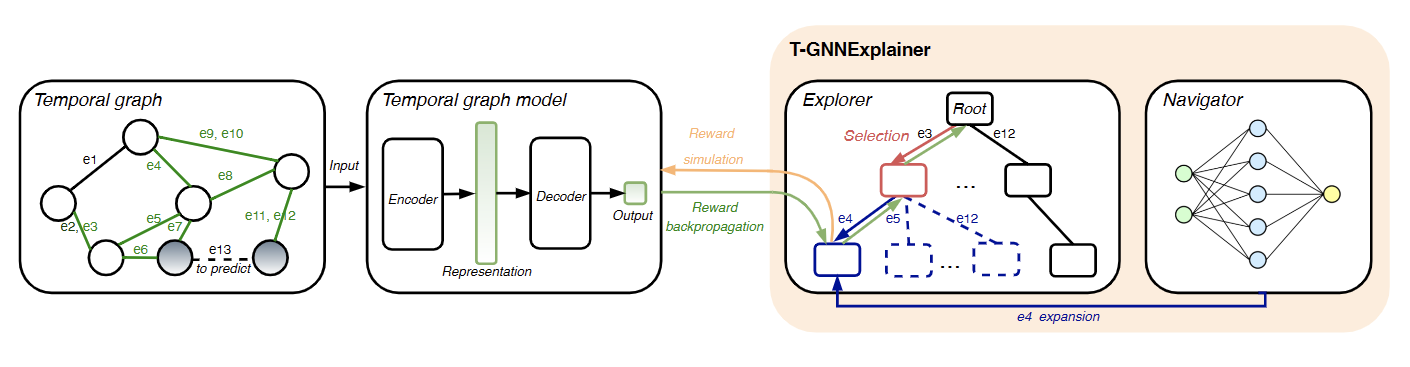
图1:T-GNNExplainer 的模型框架
基于推理阶段自适应优化的语言模型统一去毒去偏

论文连接:https://arxiv.org/pdf/2210.04492.pdf
预训练语言模型(PLMs)在文本生成(NLG)方面取得了长足进步,但却会将预训练语料中存在的有害内容(例如有毒语言和对少数群体的社会偏见等)内化、生成、传播,甚至放大。随着语言模型逐步成为各类 NLG 应用(如聊天机器人、文案写作助手)的基础,其生成的有害内容也可能通过与终端用户的频繁交互,在人类社会中广泛传播,最终造成重大的负面影响,例如吸引仇恨、导致偏见、加剧不平等。同时,这些问题不仅没有随着语言模型规模的增大而解决,反而有逐步恶化的倾向,更加突显了发展符合道德的语言生成方法的必要性和紧迫性。
现有的去毒和去偏见技术通常分为两大范式。一种是特定领域微调(Domain-Specific Tuning),即使用精心获取的干净无害的数据对模型进行进一步训练。该方法有效,但数据构建及训练大模型的成本太高且实效性差。第二种是约束解码(Constrained Decoding),以过滤、对抗引导、输出分布整流等方式来避免有害的文字生成,而无需重新训练模型。然而,这类方法会严重降低生成文本的质量或减慢生成速度。此外,现有方法都是分别处理去毒和去偏问题,这往往导致经过去偏的模型依然存在毒性,同时经过去毒的模型反而放大了偏见。
为了应对这些挑战,微软亚洲研究院的研究员们首次提出了一个基于推理阶段自适应优化的去毒和去偏见统一框架 UDDIA。UDDIA 将去偏见和去毒形式化为统一的输出分布整流过程,以此来均衡不同群体相关内容的生成概率并最小化与毒性之间的关联。该框架等价于学习一个多属性(如性别、种族、毒性等)混合的文本分布。此外,UDDIA 仅在推理(生成)阶段通过优化极少量(~1%)参数进行干预,并动态地选择何时干预、更新哪些参数。
实验结果表明,UDDIA 能减少 GPT-2 模型约40%的毒性和偏见,并保持较小的生成质量损失和较高的生成效率。该框架方法标志着在迈向道德和负责任的 NLG 方面取得了重要进展,并为未来不断增大的语言模型的安全性提供了一种灵活可扩展且低成本的有效方案。
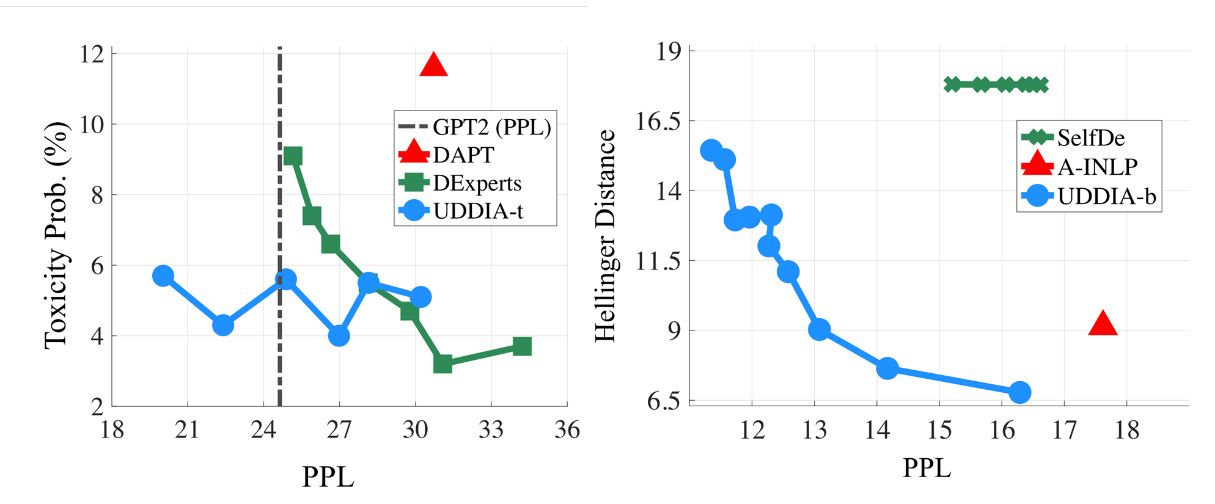
图2:UDDIA框架 (左) 去毒与生成质量的平衡曲线(右)去偏见与生成质量的平衡曲线
探索差分隐私深度学习的边界

论文链接:https://arxiv.org/abs/2212.01539
近期的差分隐私(DP)深度学习研究已显著提高计算效率和隐私-效用权衡,并在常见的隐私保证水平下实现了高效且具有良好效用的隐私保护学习流程。其中的差分隐私随机梯度下降(DP-SGD)是一种实现差分隐私保护学习的通用算法。DP-SGD 会对每个样本的梯度进行平裁剪(即先将梯度拉伸为一维向量,然后进行裁剪),接着再添加适当大小的噪声扰动。
由于 DP-SGD需要对每个样本梯度进行裁剪:1)首先实例化每个样本梯度;2)对其按照 L2 范数进行裁剪,而这会导致较高的内存和时间开销,所以使用 DP-SGD 的隐私机器学习在内存需求和速度方面比非隐私版本要高出许多。因此进行相关研究需要解决的首个问题是:隐私学习能否像非隐私学习一样在内存和时间效率(每个epoch)上保持高效?只有在提高效率后,才有可能将其应用于训练 GPT-3 等大型语言模型。
通过高效的逐层裁剪,文章作者对上述问题给以肯定的回答。具体的逐层裁剪操作如下:在神经网络进行反向传播时,在某一层参数计算出每个样本梯度后,立即进行裁剪并计算平均梯度,接着释放每个样本梯度的空间,并继续向下一层参数进行反向传播。逐层裁剪,在将裁剪操作嵌入到反向传播的过程中,还允许梯度裁剪与反向传播同时进行,从而极大地提高了效率。这使得在许多实际任务中,隐私学习在内存效率和每次训练更新的时间效率上能够媲美非隐私学习(参见图3,图4)。
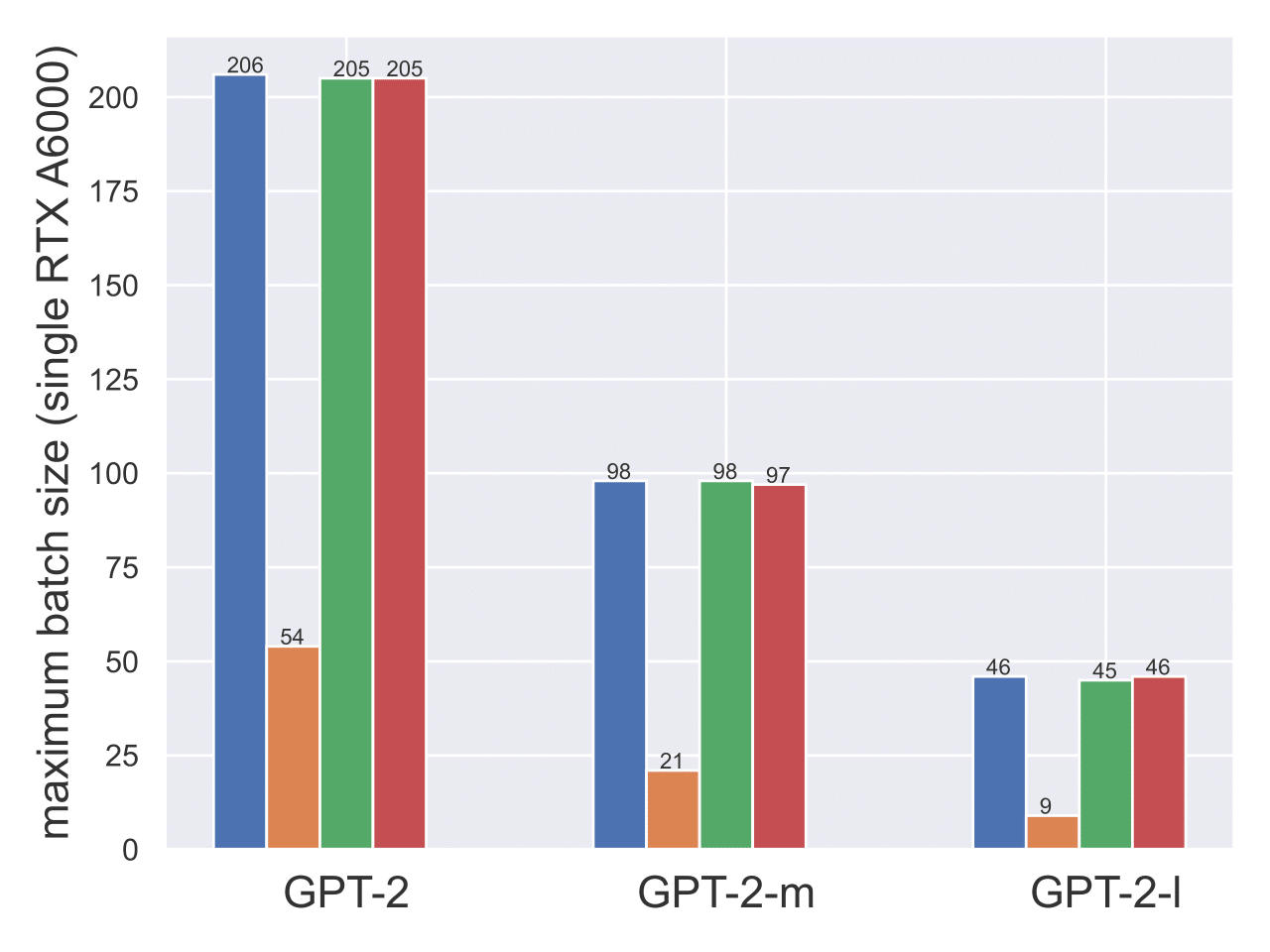
图3:不同算法内存需求比较:非隐私学习,平裁剪,虚拟裁剪和分层裁剪
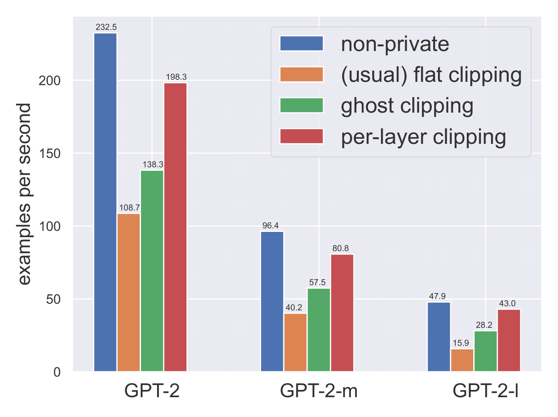
图4:不同算法吞吐速率比较:非隐私学习,平裁剪,虚拟裁剪和分层裁剪
第二个需要解决的问题是:该如何选取每层的裁剪阈值?通过简单的实验,研究员们发现使用固定阈值的逐层裁剪在性能上比平裁剪有明显降低。自适应阈值是让逐层裁剪突破性能瓶颈的关键(参见图5)。自适应阈值只需要很少的隐私预算,就可以根据算出的样本梯度 L2 范数自动估计出一个合适裁剪的阈值。多个任务证明,新方法在给定训练 epoch 约束下与平裁剪的表现相当,从而可以在更短的实际时间内获得相似或更好的任务性能。
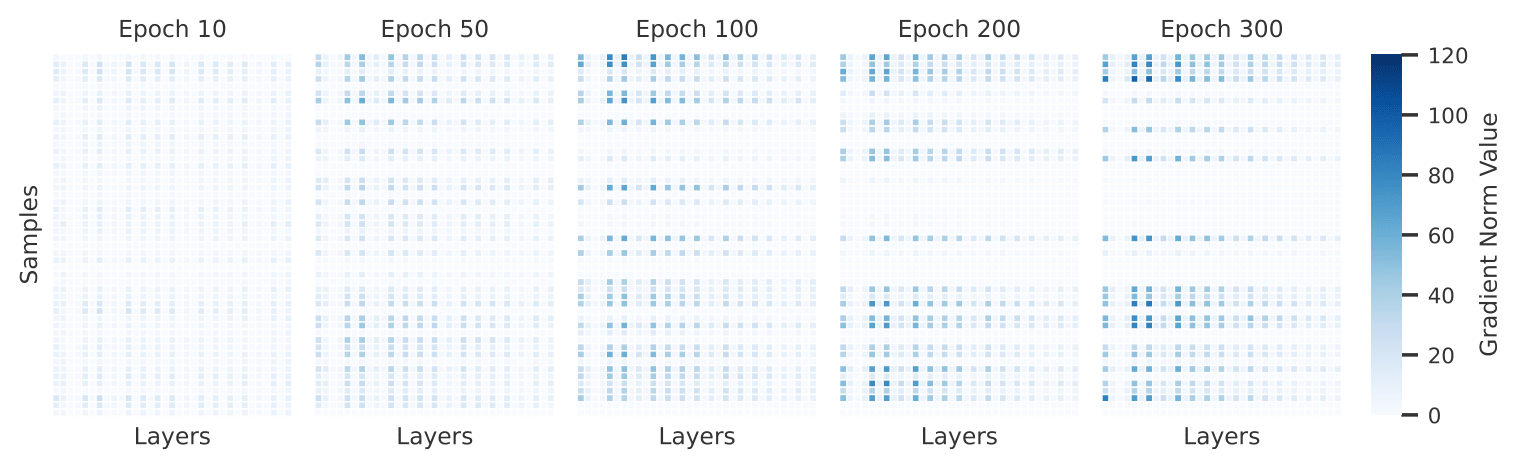
图5:不同样本的每层梯度大小随着训练步数变化显著
DP-SGD 算法在性能和效率方面的提升也使得研究员们不断探究差分隐私深度学习模型的极限。因此,研究员们在本文中探究了如何在机器学习中保护训练数据的隐私,保证模型不能被反推出训练样本的个体信息。
研究员们对具有1750亿参数的 GPT-3 进行了隐私微调。为了绕过裁剪分布在多个设备上的梯度的困难,研究员们在每个设备上对每个模型片段的梯度都进行了分组裁剪。在 ε=1 的情况下,使用隐私微调的 GPT-3 在摘要任务上可以获得优于非隐私微调的最大 GPT-2 的任务性能。研究员们突破了 DP-SGD 的效率瓶颈,使其可以成功应用于超大语言模型的训练中,经过多个测试,新方法几乎能同时实现了性能与效率的最佳值。






