语音合成模型NaturalSpeech 2:只需几秒提示语音即可定制语音和歌声
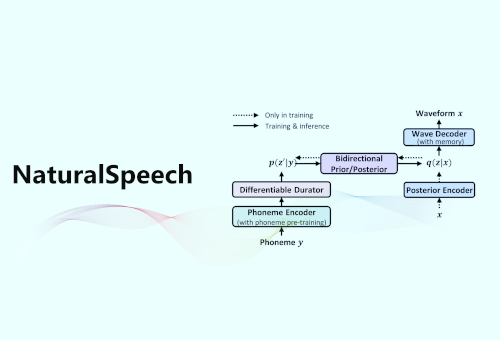
编者按:如果问华语乐坛近期产量最高的歌手是谁,“AI 孙燕姿”一定有姓名。歌迷们先用歌手的音色训练 AI,再通过模型将其他歌曲转换成以歌手音色“翻唱”的歌曲。语音合成技术是“AI 孙燕姿”的背后支持。广义的语音合成包含文本到语音合成(Text to Speech,TTS)、声音转换等。在 TTS 领域,微软亚洲研究院机器学习组和微软 Azure 语音团队早已深耕多年,并在近期推出了语音合成模型 NaturalSpeech 2,只需几秒提示语音即可定制语音和歌声,省去了传统 TTS 前期训练过程,实现了零样本语音合成的跨越式发展。
发布时间:2023-05-10 类型:深度文章