
尽管如今的 AI 模型已经具备了理解自然语言的能力,但科研人员并没有停止对模型的不断改善和理论探索。自然语言处理(NLP)领域的技术始终在快速变化和发展当中,酝酿着新的潮流和突破。
发布时间:2023-07-12 类型:深度文章


尽管如今的 AI 模型已经具备了理解自然语言的能力,但科研人员并没有停止对模型的不断改善和理论探索。自然语言处理(NLP)领域的技术始终在快速变化和发展当中,酝酿着新的潮流和突破。
发布时间:2023-07-12 类型:深度文章

ACL 2023|大模型时代,自然语言领域还有什么学术增长点?
国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称 ACL)是自然语言处理(NLP)领域的顶级国际会议,ACL 2023 将于2023年7月9-14日在加拿大多伦多举行。随着人工智能技术的快速发展,确保相关技术能被人们信赖是一个需要攻坚的问题。微软亚洲研究院也在不断推进负责任的人工智能的探索发现与应用实践。今天我们为大家带来3篇微软亚洲研究院以负责任的人工智能为主题入选 ACL 2023 的论文。
发布时间:2023-07-04 类型:深度文章

文档智能多模态预训练模型LayoutLMv3:兼具通用性与优越性
编者按:企业数字化转型中,以文档、图像等多模态形式为载体的结构化分析和内容提取是其中的关键一环,快速、自动、精准地处理包括合同、票据、报告等信息,对提升现代企业生产效率至关重要。因此,文档智能技术应运而生。过去几年,微软亚洲研究院推出了通用文档理解预训练 LayoutLM 系列研究成果,并不断优化模型对文档中文本、布局和视觉信息的预训练性能。近期发表的最新的 LayoutLM 3.0 版本,在以文本和图像为中心的任务上有了更加出色的表现,让文档理解模型向跨模态对齐迈出一大步!
发布时间:2022-07-26 类型:深度文章

无限视觉生成模型NUWA-Infinity让视觉艺术创作自由延伸
编者按:此前,微软亚洲研究院提出了多模态模型 NUWA,它可以基于给定的文本、视觉或多模态输入生成图像或视频,并支持多种视觉艺术作品创建任务,包括文本到图像或视频的生成、图像补全、视频预测等。近日,微软亚洲研究院公开发表了新的研究成果:NUWA 的升级版——无限视觉生成模型 NUWA-Infinity,让视觉艺术创作趋于“无限流”,可生成任意大小的高分辨率图像或长时间视频。一起来感受一下 AI 的无限创作力吧!
发布时间:2022-07-22 类型:深度文章

ACL 2022 | NLP领域最新热门研究,你一定不能错过!
编者按:作为自然语言处理领域的国际顶级学术会议,ACL 每年都吸引了大量学者投稿和参会,今年的 ACL 大会将于5月22日至5月27日举办。值得注意的是,这也是 ACL 大会采用 ACL Rolling Review 机制后的首次尝试。在此次会议中,微软亚洲研究院有多篇论文入选,本文精选了其中的6篇进行简要介绍,论文主题涵盖了:编码器解码器框架、自然语言生成、知识神经元、抽取式文本摘要、预训练语言模型、零样本神经机器翻译等。欢迎感兴趣的读者阅读论文原文。
发布时间:2022-05-19 类型:深度文章

编者按:此前我们曾提出了一个问题:从文字脚本生成创意视频一共分几步?微软亚洲研究院的开放领域视频生成预训练模型给出了答案:只需一步。现在,我们追问:除了文字生成视频之外,还有哪些途径可以生成视频?我们能否使用自然语言对视觉内容进行编辑?微软亚洲研究院最新推出的多模态模型 NÜWA,不仅让视觉内容创造多了一条路,甚至还让 Windows 经典桌面有了更多的打开方式。
发布时间:2022-03-03 类型:深度文章
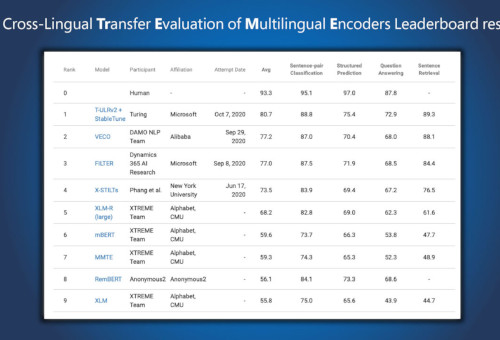
为进一步实现用 AI 赋能用户体验,微软正在不断拓展多语言模型的边界。近日,由微软图灵团队与微软亚洲研究院联合探索的最新跨语言研究成果——多语言预训练模型 T-ULRv2,登顶 XTREME 排行榜,T-ULRv2 可以在相同向量空间表示和理解94种语言,提升所有语言的产品体验。
发布时间:2020-11-04 类型:深度文章

代码智能新基准数据集CodeXGLUE来袭,多角度衡量模型优劣
代码智能(code intelligence)目的是让计算机具备理解和生成代码的能力,并利用编程语言知识和上下文进行推理,支持代码检索、补全、翻译、纠错、问答等场景。以深度学习为代表的人工智能算法,近年来在理解自然语言上取得了飞跃式的突破,代码智能也因此获得了越来越多的关注。该领域一旦有突破,将大幅度推动 AI 在软件开发场景的落地。
发布时间:2020-09-29 类型:深度文章
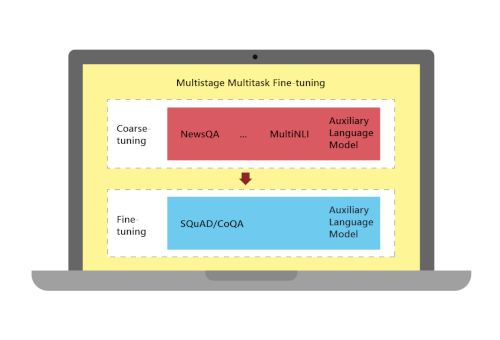
微软机器阅读理解系统性能升级,刷新CoQA对话式问答挑战赛纪录
近日,由微软亚洲研究院自然语言处理组与微软雷德蒙语音对话组研究员组成的团队,在斯坦福大学发起的对话式问答挑战赛CoQA(Conversational Question Answering Challenge)中荣登榜首,成为目前排行榜上唯一一个模型分数超过人类分数的团队。
发布时间:2019-05-06 类型:深度文章
WMT 2019国际机器翻译大赛:微软亚洲研究院以8项第一成为冠军
近日,由国际计算语言学协会ACL(The Association for Computational Linguistics)举办的WMT 2019国际机器翻译比赛的客观评测结果揭晓,微软亚洲研究院机器学习组在参加的11项机器翻译任务中,有8项获得了第一名,另外3项获得第二名,凭借多维度的技术创新成为冠军团队。
发布时间:2019-04-22 类型:深度文章






