
对生成式人工智能而言,2023年是具有重要意义的一年。在这一年里,数百万人通过使用 ChatGPT 和 Microsoft Copilot 等工具,让人工智能从实验室走进了我们的现实生活。展望2024年,人工智能将会变得更加便利和实用、更加深入细微,并将融入到那些可以提升我们日常工作和协助解决全球性问题的技术中。
发布时间:2024-02-22 类型:深度文章


对生成式人工智能而言,2023年是具有重要意义的一年。在这一年里,数百万人通过使用 ChatGPT 和 Microsoft Copilot 等工具,让人工智能从实验室走进了我们的现实生活。展望2024年,人工智能将会变得更加便利和实用、更加深入细微,并将融入到那些可以提升我们日常工作和协助解决全球性问题的技术中。
发布时间:2024-02-22 类型:深度文章

AAAI上新 | 从生成检索、跨语言迁移,到负责任的视觉合成
编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。
发布时间:2024-02-21 类型:深度文章

编者按:2023年,人工智能无疑是科技领域的“巨星”,大模型的持续迭代不仅激发了学术界和产业界的深刻变革,也加速了技术在各领域的广泛应用。这一进程再次证明,我们正处在孕育新一代计算范式的关键节点。在这样的背景下,微软亚洲研究院持续刷新自我,在新的使命的驱动下,以前瞻的思想引领科研创新,以前沿的技术成果赋能人类社会。辞旧迎新之际,让我们通过8个关键词,回顾微软亚洲研究院过去一年的重要成就,共同踏上科学探索的新征程。
发布时间:2024-02-06 类型:深度文章

对话 | ACM、IEEE双Fellow谢幸:坚持长期主义研究的秘诀是什么?
编者按:日前,全球计算机领域影响力最大的专业学术组织国际计算机学会(Association for Computing Machinery,简称 ACM)公布了2023年度 ACM Fellow 名单。微软亚洲研究院资深首席研究员谢幸博士因其在空间数据挖掘和推荐系统方面的卓越贡献获选其中。
发布时间:2024-02-05 类型:深度文章

Microsoft Research Forum首期上线:探索通用型人工智能的前沿研究
近日,微软研究院上线了面向全球研究界的全新线上系列活动 Microsoft Research Forum,旨在共同探讨人工智能时代的最新研究进展、大胆新颖的想法以及全球研究界关注的重要议题。来自微软研究院全球各地的研究人员将分享他们的研究洞见,并与大家进行在线讨论,希望碰撞出更多新的思想火花。
发布时间:2024-02-02 类型:深度文章
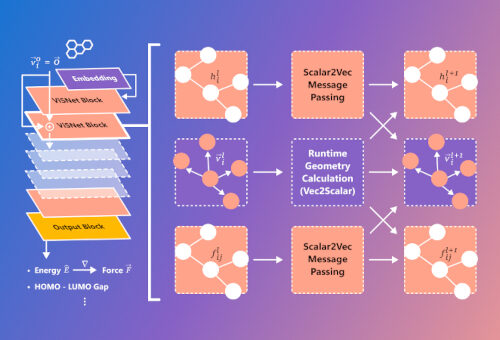
ViSNet:用于分子性质预测和动力学模拟的通用分子结构建模网络
编者按:尽管几何深度学习已经彻底颠覆了分子建模领域,但最先进的算法在实际应用中仍然面临着几何信息利用不足和高昂计算成本的阻碍。为此,微软研究院科学智能中心(Microsoft Research AI4Science)的研究员们提出了通用分子结构建模网络 ViSNet。在多个分子动力学基准测试中,ViSNet 均表现优异。
发布时间:2024-01-31 类型:深度文章

提示词专场:从调整提示改善与LLMs的沟通,到利用LLMs优化提示效果
编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。
发布时间:2024-01-30 类型:深度文章

微软亚洲研究院资深首席研究员谢幸博士获选2023 ACM Fellow
国际计算机学会(Association for Computing Machinery,简称 ACM)今天公布了2023年度 ACM Fellow 名单。本届入选的科研人员来自全球各地,并在包括人工智能技术、计算机图形学、网络安全、移动计算、软件分析和网络搜索等领域做出了突破性创新。其中,微软亚洲研究院资深首席研究员谢幸博士因其在空间数据挖掘和推荐系统方面的卓越贡献获选2023 ACM Fellow。
发布时间:2024-01-25 类型:深度文章

优化LLM数学推理;深度学习建模基因表达调控;基于深度学习的近实时海洋碳汇估算
编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。
发布时间:2024-01-04 类型:深度文章

编者按:2023年是微软亚洲研究院建院25周年,借此机会,我们特别策划了“智汇对话”系列内容,邀请全球各领域顶尖专家学者共同畅谈研究文化,探讨跨学科创新,展望技术未来。
发布时间:2023-12-08 类型:深度文章






